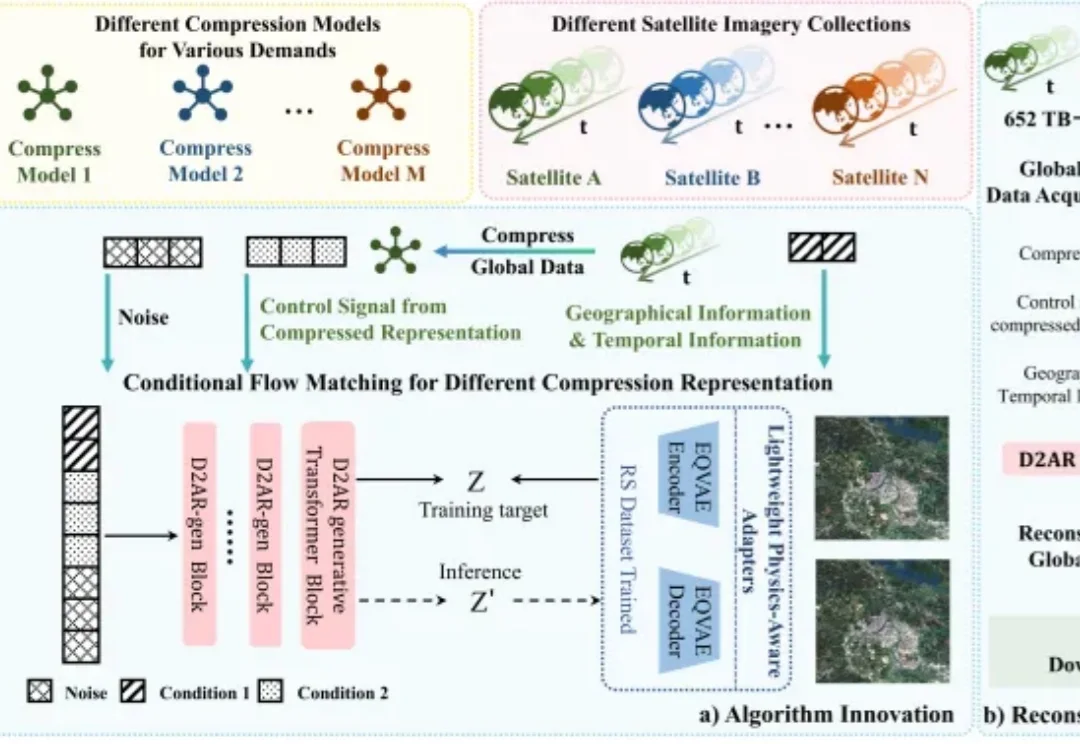
国产超算生成式压缩模型训练性能突破2.16 EFLOP/s,支撑全球遥感数据万倍级压缩
国产超算生成式压缩模型训练性能突破2.16 EFLOP/s,支撑全球遥感数据万倍级压缩随着全球遥感卫星持续运行,地球观测数据正在快速增长。多源、多时相、多光谱遥感影像为国土监测、生态评估、灾害预警、气候变化研究等任务提供了重要数据基础,但也带来了显著的存储、传输和计算压力。
来自主题: AI技术研报
9209 点击 2026-05-29 09:39
 搜索
搜索
随着全球遥感卫星持续运行,地球观测数据正在快速增长。多源、多时相、多光谱遥感影像为国土监测、生态评估、灾害预警、气候变化研究等任务提供了重要数据基础,但也带来了显著的存储、传输和计算压力。

DeepSeek V4发布,比模型本身更受关注的,是一个根本性的转变: 国产算力生态正在从过去“芯片被动适配模型”的单向奔赴,迈向“芯模协同”的新阶段。

同一个市场,同一个月成立的公司。

7×24,AI也吃不消。

当对话型 AI 服务于数十亿用户时,我们能否看见用户没说出口的那一层?JHU、MIT 和 Google Research 给出了新的解法。

有一个我们很少说出口的预设:AI 带来的恐慌是从下往上递减的。越底层越慌,越顶层越从容。应届生最危险,大厂高管有把握,基础模型公司的人?他们是在写未来,不是在应对它。
初创公司Axiom Math宣布,他们从2026年2月开始提交的8篇论文,到5月28日有5篇已经通过同行评审,登上学术期刊。创始人洪乐潼,2001年出生于广州,本科MIT三年拿下数学与物理双学位,还拿过北美数学本科生的最高荣誉罗德奖学金和摩根奖。
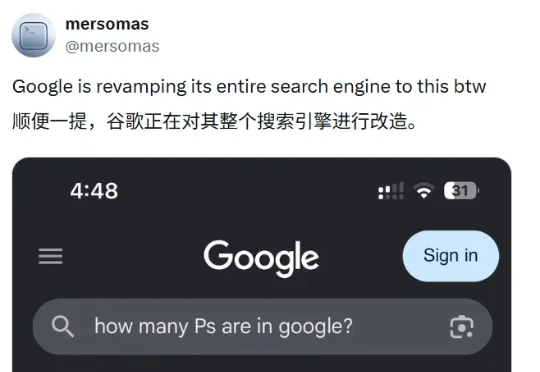
今天,又有新的问题出现了,这一次是谷歌搜索。有用户发现,近日升级了 AI 能力的谷歌搜索在面对「google 里面有几个 P」这样的简单问题时竟然失败了!这件事引发广泛关注和测试热潮。我们也简单试了下,就算用汉语提问,谷歌搜索同样错误,而且还自行加戏,导致错上加错 —— 说 Pixel 里面有两个 P

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。
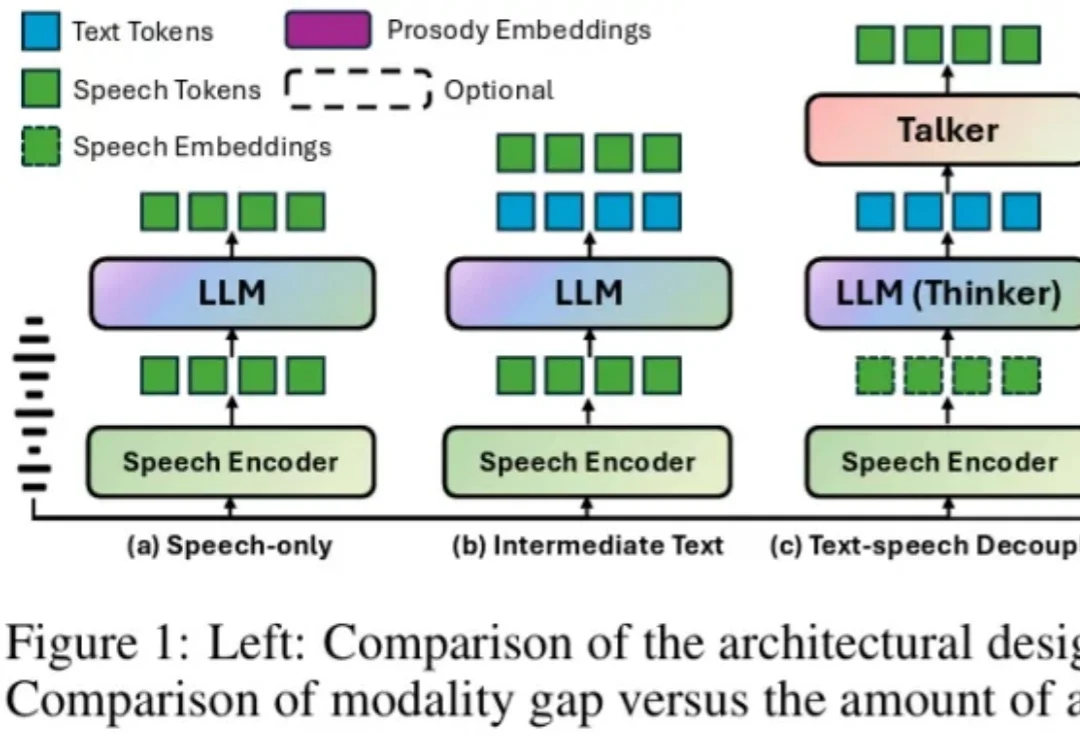
相信大家都有过这样的体验:同一个系列的模型,使用文本交互的时候,模型就像开启了 “最强大脑”,数学代码等各种复杂推理任务样样精通,可是一旦将其改造成语音对话模型之后,性能就猛烈下降,严重 “降智”,经常会犯很多基本的逻辑错误。