# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
相信大家都有过这样的体验:同一个系列的模型,使用文本交互的时候,模型就像开启了 “最强大脑”,数学代码等各种复杂推理任务样样精通,可是一旦将其改造成语音对话模型之后,性能就猛烈下降,严重 “降智”,经常会犯很多基本的逻辑错误。
这个让整个行业十分头疼的现象,学术界将其定义为 “模态代沟”(Modality Gap)。
为了降低 Modality Gap,整个 Speech AI 行业在过去几年里进行了两波主要的改进。
第一波改进,大家发现应该 “换模态”。既然传统端到端的语音大模型严重降智,那就通过文本模态进行缓冲,也就是让模型先 “想” 出文本,再将文本转换成对应的语音输出。这便催生了目前语音大模型的主流架构:Thinker-Talker。大家发现让 Thinker 输出文本的模式可以一定程度上拉高模型的性能上限。
第二波改进,大家开始在模型的输出端对齐(Output Alignment)上面下功夫。即使是用 Thinker 做文本输出,还是有相当一部分的 Modality Gap。于是大家希望大模型在面对文本输入和语音输入的时候能 “一模一样” 的输出,从而拉高智商。于是行业中出现了各种各样专门缓解 Modality Gap 的文章。他们大多数通过知识蒸馏(Knowledge Distillation),表示对齐(Representation Alignment)等方法来拉近两个模式下输出的距离。
然而,我们发现,在这两波改进之后,即使语音预训练数据被拉到了百万小时甚至千万小时的级别,降智问题依旧存在。强如 Qwen2.5-Omni,在复杂的数学推理任务上依然会面临超过 15% 的性能下降。
这让我们思考:这些方法为什么无法从根本上解决问题?我们是不是要换一个角度来思考降智的问题?🤔
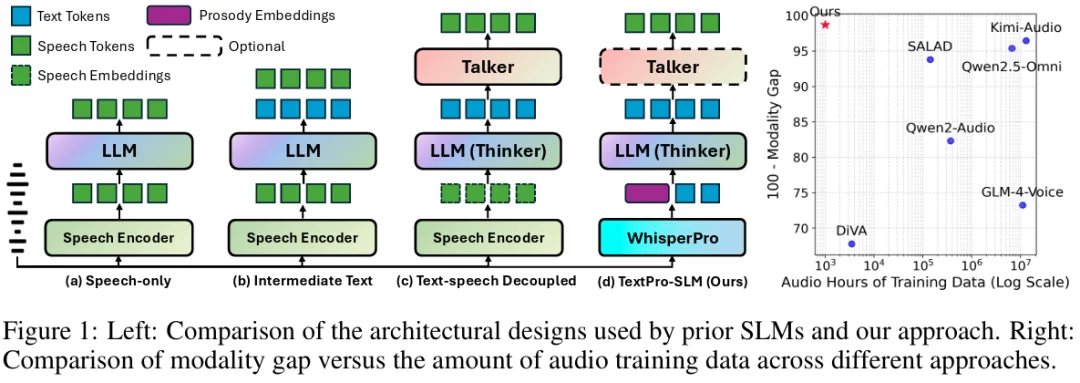
Figure 1 以往的架构死磕输出端,而 TextPro-SLM 选择从输入端破局
最近,一篇来自香港中文大学的最新力作,一下子戳破了重点:“为什么 Speech LLM 还是做的不够好?因为真正的瓶颈,已经不在输出端,而在输入端!”
这篇论文名为《Minimizing Modality Gap from the Input Side: Your Speech LLM can be a Prosody-Aware Text LLM》。研究者们提出了一种极其反直觉却又非常优雅的新架构 ——TextPro-SLM。他们发现在这种新架构下,仅仅需要约 1000 小时 的语音训练数据,就可以在 3B 和 7B 参数规模上,实现业界最低 Modality Gap!

我们知道,现在的语音大模型都是从文本大模型的基础上训练而来。想象一下,如果你是一个文本大模型(TLM),你最习惯的输入是什么?是干净纯洁、高度浓缩而有效的,带有人类语义逻辑的文本 tokens。
但现在的主流的语音大模型,也就是 Thinker-Talker 架构中,它的输入是什么样的?我们把输入语音变成一长串连续的,但语义缺极其稀疏的向量表示(Speech Embeddings),然后一下子的强行塞进大模型里。
这种表征之中,无论是语义信息,副语言信息等等,都在这个极度庞杂的声学信号中被瞬间稀释。 在这样的输入下,大模型连听清你具体在问什么,都要消耗巨量的脑细胞,这让模型哪还有功夫去做深度逻辑推理?
基于这个观察,香港中文大学的研究人员提出了一个极其犀利的 insight :
既然现在 Speech LLM 的输出端已经和文本大模型保持了一致(Thinker-Talker 中 Thinker 只输出文本 tokens),那为什么输入端不能也像文本大模型来靠拢呢?从架构设计的角度来讲,我们不需要逼着大模型去理解原声杂乱的语音信号,我们只需要把它变成一个 “听得懂语气的文本大模型(Prosody-Aware Text LLM)!”。
想想看,人类的语音其实核心就包含两个维度的信息:说了什么(语义内容,semantics) 和 怎么说的(韵律 / 副语言信息,Prosody)。
主流做法是把这两个信息揉在同一批 Speech Embedding 中,而 TextPro-SLM 则将两种信息彻底解耦。它在输入端直接把语音拆分成两路:纯粹的文本 Token(保留大模型最爱的极致语义。是的,不用任何语音 semantic embedding),和高度浓缩的韵律 Embedding(如情绪、口音、年龄、音色等)。
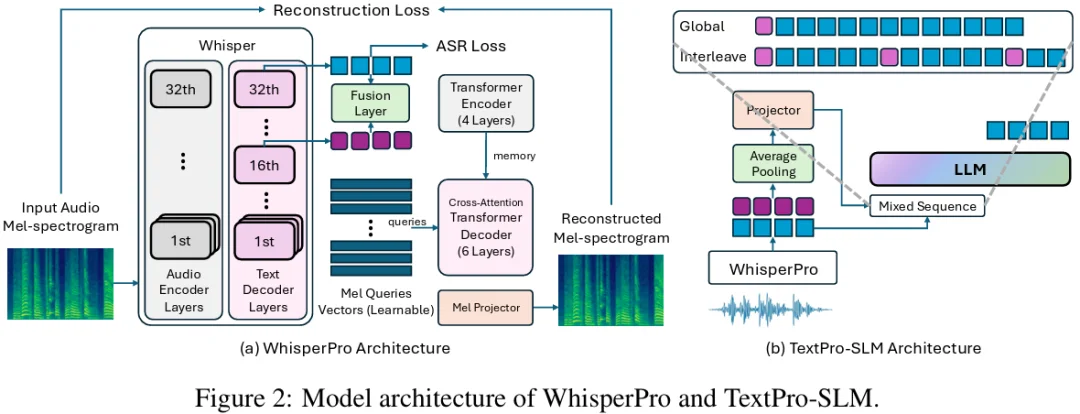
Figure 2 WhisperPro 加上重构损失,实现文本与韵律的双流输出。
研究团队设计了两个十分优雅的模块来实现语义与韵律的彻底解耦:
1. 文本声音双全的统一的 Speech Encoder:WhisperPro。研究团队通过改造强大的语音识别(ASR)模型来实现大一统:让 Whisper-large-v3 在文本转录的同时保留韵律特征。核心做法是在 Whisper 后面额外加入了一个 decoder 模块,并使用重构损失(Reconstruction Loss)让 Whisper 学会语音还原。这逼着 Whisper 的底层特征不仅要准确输出文字,还必须把情绪、语气等信息高度保留在 hidden states 中。最终模型输出对齐的 Text Token + Prosody Embedding。
2. 让 LLM 同时理解文本语义与韵律特征:如何把 Speech Encoder 的两路输出喂给大模型?文章中提出了两种极其巧妙的投喂方式,将语音信息完美伪装成大模型最熟悉的形态:
这种数据输入方式完美匹配了文本大模型的舒适区,因此整个训练过程极其省数据:仅仅用了约 1000 小时的音频做知识蒸馏和副语言训练。对比目前主流的商业模型,动不动就需要几百万甚至几千万小时训练数据,TextPro-SLM 简直是降维打击。
一句话来形容 TextPro-SLM,那就是 “四两拨千斤”。它在多个 benchmark 上展现出了近乎消失的 Modality Gap:
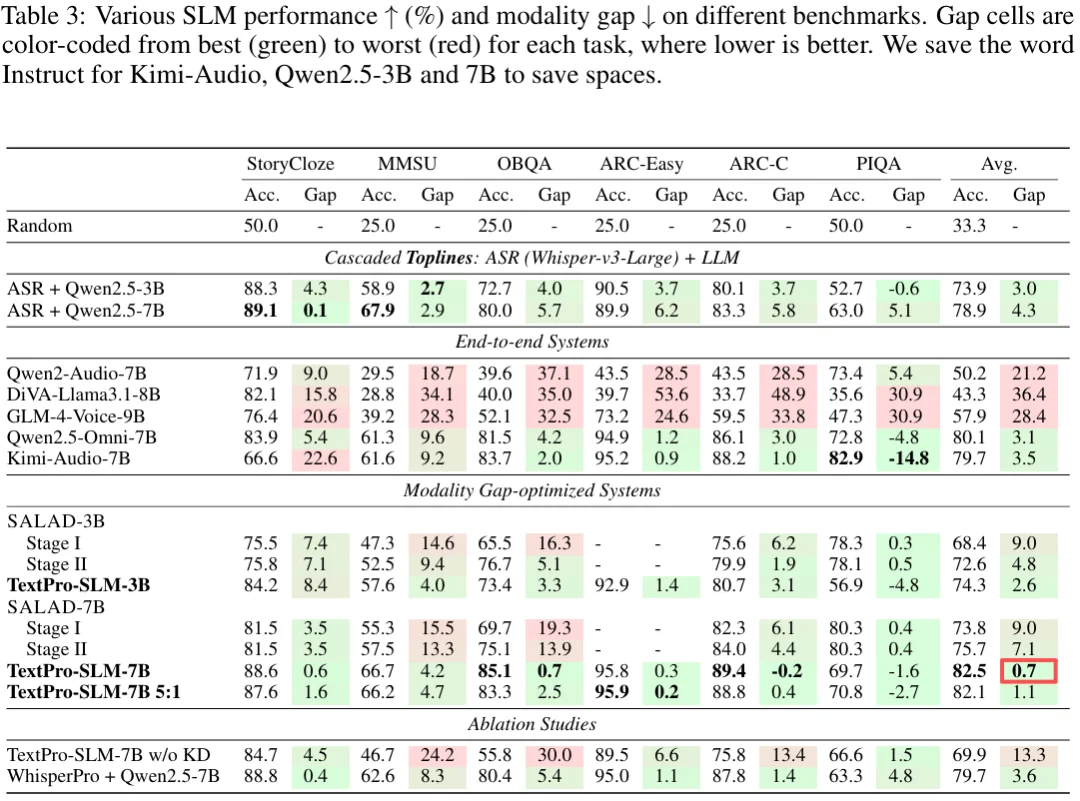
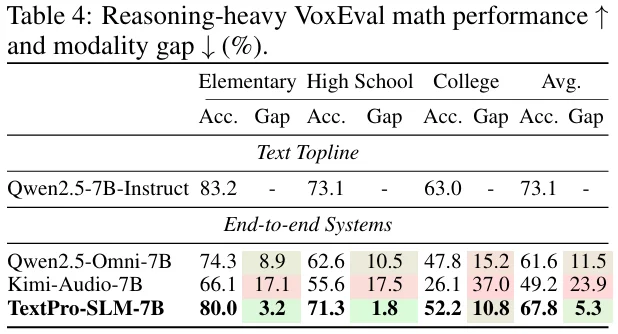
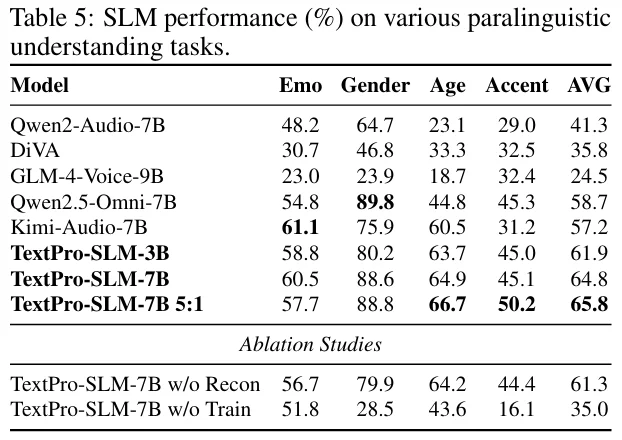
TextPro-SLM 的出现,不仅仅是为了解决 Modality Gap,它对整个多模态模型设计具有极强的启发意义。
当全行业都在用无尽算力和海量数据强行连接各个极度差异的模态时,这篇论文提出了一个不同的声音:有时候,巧妙的特征解耦(Decoupling),比暴力的特征融合更符合第一性原理。
对于正在 Speech LLM 行业深耕的创业者和开发者来说,TextPro-SLM 指出了一条明路:与其说暴力的消耗算力和疯狂的采集数据,不如深入思考下究竟目前的 gap 在哪里。当你利用输入端的巧妙设计,只需 1000 小时便可让你的语音 Agent 同时实现天花板级别的文本能力和超高的共情能力。
语音大模型的进化,不一定非要让它 “长出顺风耳”,去试图听懂嘈杂的世界;有时候,给它配一个巧妙的 “信息助听器”,反而能激发出最纯粹的智慧。
真正的多模态融合,或许不是强行把各种杂乱的信息揉在一起,而是让每种模态的信息,都能以它最舒适的姿态被理解。
文章来自于"机器之心",作者 "机器之心"。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
