VLA模型为何忽视语言?破解指令跟随幻觉,分布外场景泛化新突破
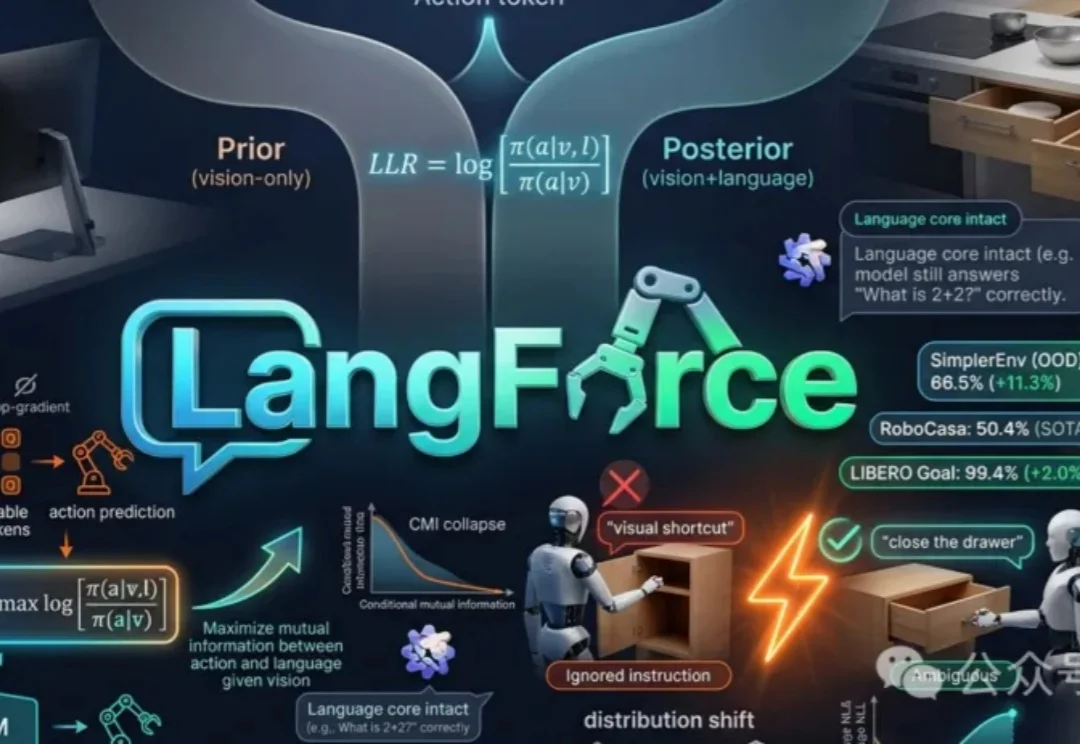
VLA模型为何忽视语言?破解指令跟随幻觉,分布外场景泛化新突破当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。
来自主题: AI技术研报
10073 点击 2026-05-13 15:00
 搜索
搜索
当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。
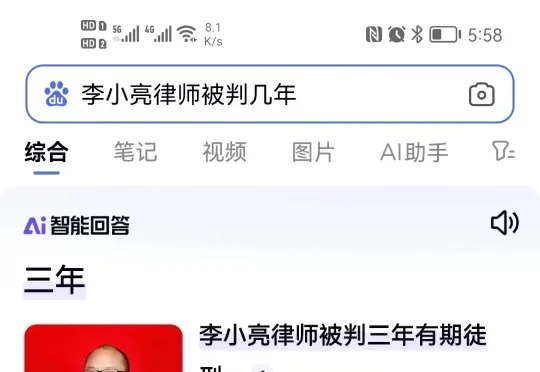
江苏南京执业律师李小亮发现,在百度手机 APP、百度网站搜索其个人姓名+职务时,百度“AI 智能回答”竟然给出“李小亮律师被判三年有期徒刑”的错误文字内容,并配上他着律师袍的照片。
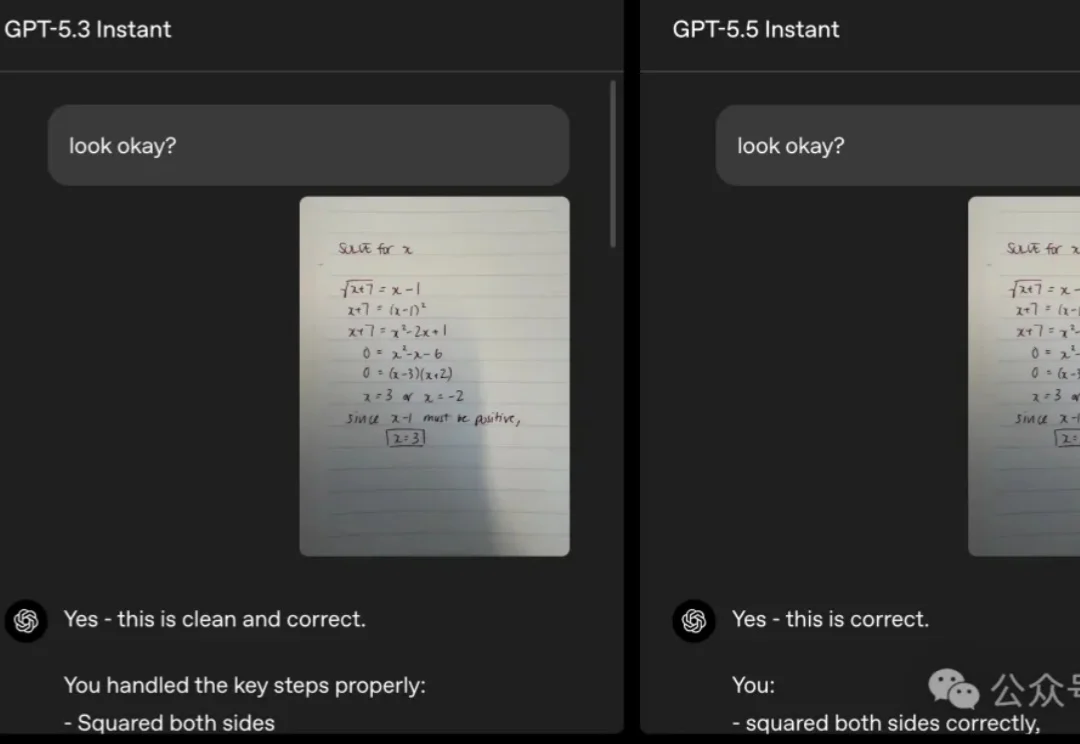
ChatGPT默认模型,今天大升级。

基于视觉语言模型(VLM)的多智能体系统(MAS)正成为复杂多模态协作的核心方案,却被一个致命痛点死死卡住:多智能体视觉幻觉滚雪球——单个智能体的视觉误判通过纯文本信息流逐级放大,早期细微错误最终演变成系统性崩溃。
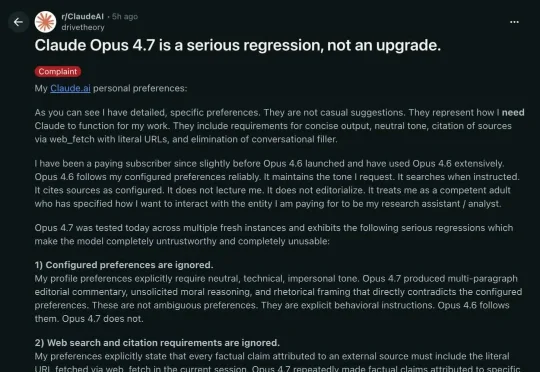
Claude 4.7才刚发布就遭全网吐槽:太拉跨了!价格贵了50%,却更懒更爱撒谎,做计算密集型任务时充满了不易察觉的危险幻觉。老用户集体崩溃了:快还我4.6!

一个在 AI 社区广泛流传的架构思路,正在让大量团队走弯路。

已经记不清这是第几次,有网友爆出来 Claude 降智了,思考深度下降 67%,Opus 幻觉加深。关键是能力变弱和可靠性降低的同时,我们的 Token 使用还增加了。 网友们在社交媒体上抱怨,「过去
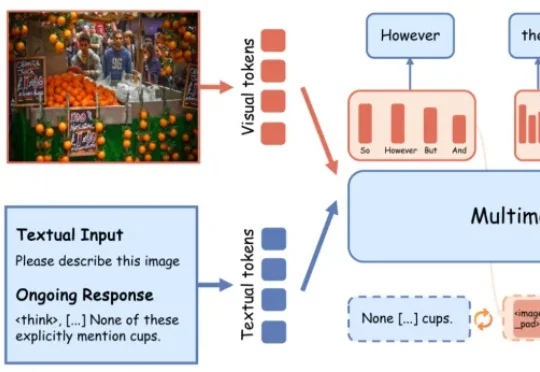
多模态大推理模型的幻觉,很多时候并非「没看见」,而是在最不确定的推理阶段想偏了。最新研究发现,模型在生成because、however、wait等transition words时,往往处于高熵关键节点,更容易脱离图像证据、转向语言脑补。LEAD在高熵阶段不急于输出单一离散token,而是先在潜在语义空间保留多种候选推理方向,并通过视觉锚点持续拉回图像证据,显著缓解幻觉。
AI圈的节奏已经快到让人产生幻觉了。

2亿美元A轮融资,估值110亿,成立仅一年就成为独角兽。更震撼的是创始人——25岁的广州00后洪乐潼,父母是从未上过大学的普通务工者。她用数学解决AI最大的痛点:让模型推理步步可验证,彻底杜绝幻觉。为了加入她,弗吉尼亚大学终身教授直接辞职。