
陶哲轩参赛,在这项极其严格的数学测试中,人类表现优于AI
陶哲轩参赛,在这项极其严格的数学测试中,人类表现优于AI就在外界惊呼“AI快要接管纯数学研究”之际,一场限制条件极其严格、并由30位数学家以匿名方式进行评审的数学测试,却揭开了AI数学能力的另一面:AI不仅会幻觉、会跳步骤,甚至还把数学家论文里的关键论证几乎原样照搬,却忘了注明引用。
来自主题: AI技术研报
8691 点击 2026-06-28 11:35
 搜索
搜索
就在外界惊呼“AI快要接管纯数学研究”之际,一场限制条件极其严格、并由30位数学家以匿名方式进行评审的数学测试,却揭开了AI数学能力的另一面:AI不仅会幻觉、会跳步骤,甚至还把数学家论文里的关键论证几乎原样照搬,却忘了注明引用。
从 Founder Park 出去后,Muji 去新加坡深造了一年,然后以 COO 的身份加入了 Seede AI。
咱们 AI 领域,研究者既是一个身份,也是一种幻觉。
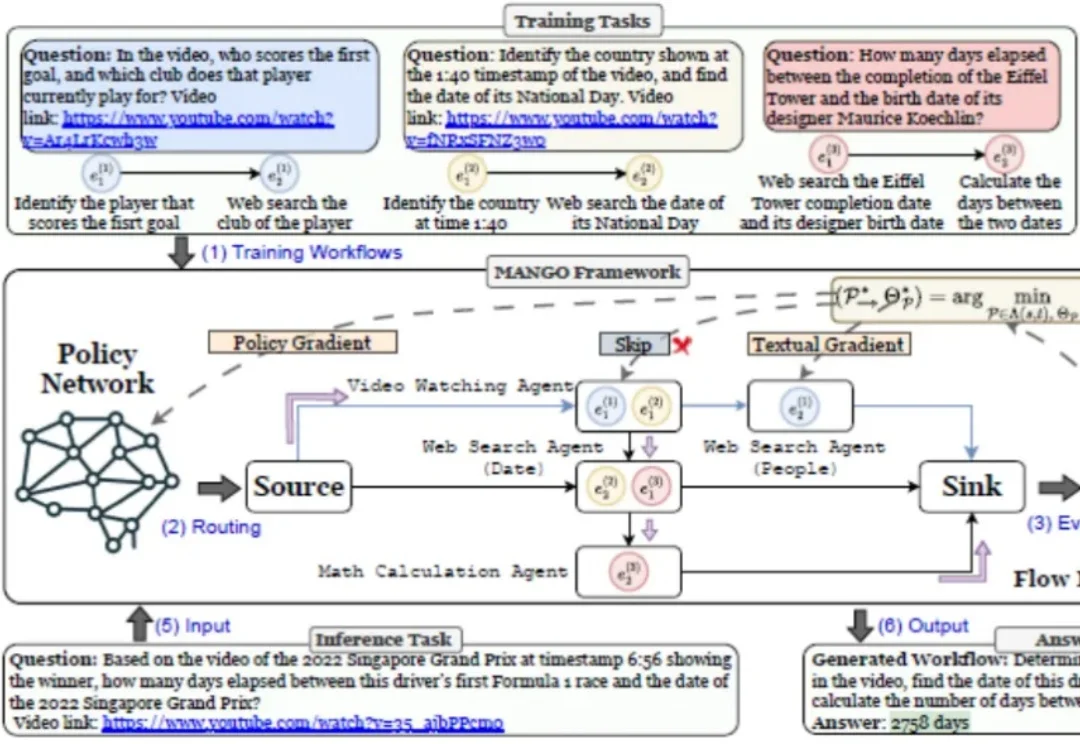
多智能体协作对于解决复杂问题虽然具有巨大优势,但是其架构本质上易出现错误传播,因为由不正确的工作流生成或单智能体幻觉输出引起的错误会沿着协作链蔓延,影响最终结果。

为解决科研中对单篇文献深度解析的需求,佐治亚大学团队提出IntrAgent,专注单篇内容,避免大模型幻觉。通过段落排序与迭代阅读机制,精准提取实验细节与元数据。

随着大模型智能体深入渗透真实操作系统,一种全新的安全威胁悄然成型:行为越狱(Behavior Jailbreak)。现有安全基准只盯着模型「说了什么」,却对「做了什么」视而不见。新基准LITMUS是首个同时覆盖真实OS环境行为越狱、语义-物理双层验证与多攻击范式的完整评测体系,并首次系统量化了「执行幻觉」这一被整个评测社区忽视的致命盲区。

5 月 22 日,星巴克在内部通讯中正式通知北美 1.1 万家门店:立即停止使用名为 “自动计数(AC)” 的 AI 库存工具,所有饮品原料(糖浆、牛奶、浇头等)回归人工盘点。
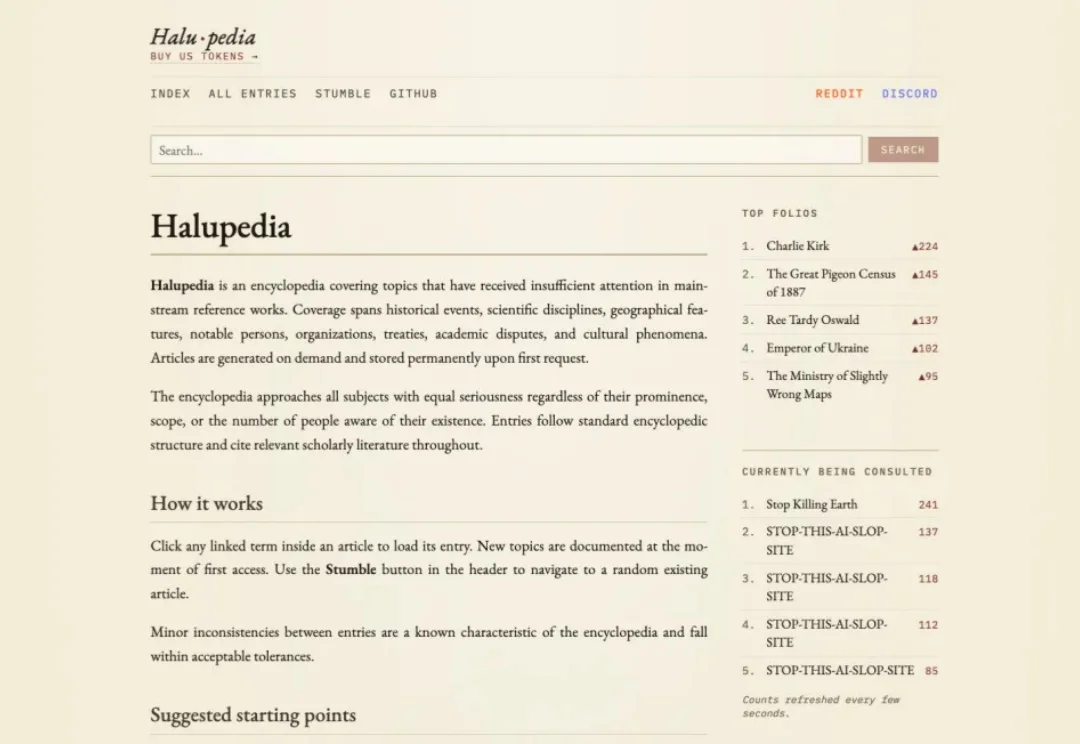
当我们在维基百科搜索一个词条时,你期待的是真相,至少在AI时代,总得有一个地方能(大概率)给我点真东西吧。可以,但在 Halupedia 搜索一个词条时,得到的也是真相——一个三秒钟前刚被发明出来的真相。
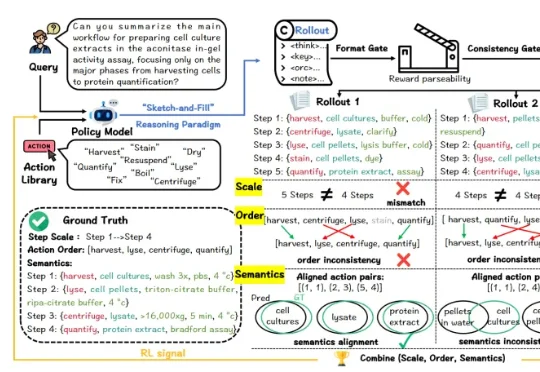
针对这一问题,上海人工智能实验室、复旦大学、上海交通大学团队提出了Thoth:一个面向生物实验protocol生成的科学推理模型。一句话概括:Thoth不是让模型“写得像protocol”,而是让模型按照实验逻辑,生成可解析、可评估、可执行的protocol。

Claude深陷「角色混淆」Bug,分不清自己的话与用户指令,长上下文成了降智「重灾区」。