宇树:开源机器人世界大模型!
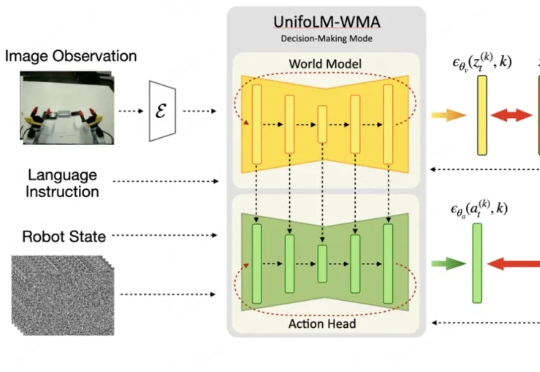
宇树:开源机器人世界大模型!一觉醒来,宇树带着最新开源模型来了!这次开源的是一个世界模型-动作架构,名叫UnifoLM-WMA-0。它的核心之处在于拥有一个世界模型能够理解机器人和环境相互作用时的物理规律。
来自主题: AI技术研报
8984 点击 2025-09-16 16:07
 搜索
搜索
一觉醒来,宇树带着最新开源模型来了!这次开源的是一个世界模型-动作架构,名叫UnifoLM-WMA-0。它的核心之处在于拥有一个世界模型能够理解机器人和环境相互作用时的物理规律。
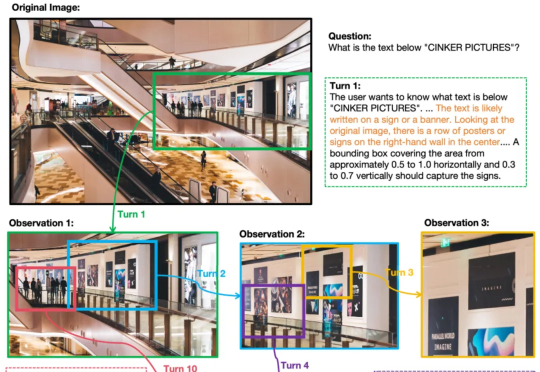
OpenAI o3的多轮视觉推理,有开源平替版了。并且,与先前局限于1-2轮对话的视觉语言模型(VLM)不同,它在训练限制轮数只有6轮的情况下,测试阶段能将思考轮数扩展到数十轮。

国产自研开源模型,让模型不用在快思考和慢思考间二选一了!
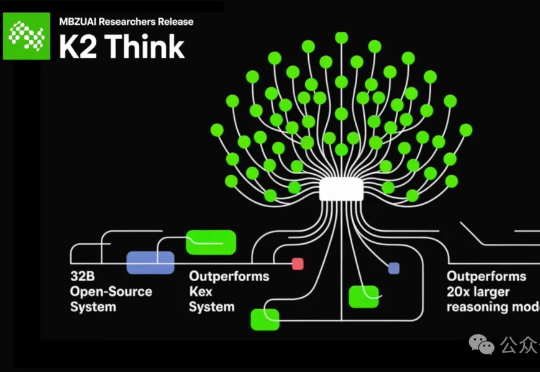
全球最快的开源大模型来了——速度达到了每秒2000个tokens! 虽然只有320亿参数(32B),吞吐量却是超过典型GPU部署的10倍以上的那种。它就是由阿联酋的穆罕默德·本·扎耶德人工智能大学(MBZUAI)和初创公司G42 AI合作推出的K2 Think。
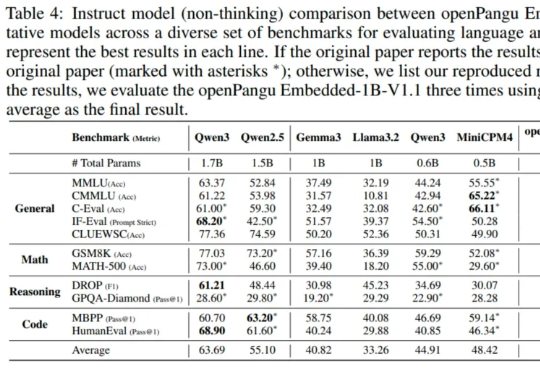
在端侧 AI 这个热门赛道,华为盘古大模型扔下了一颗 “重磅炸弹” 。
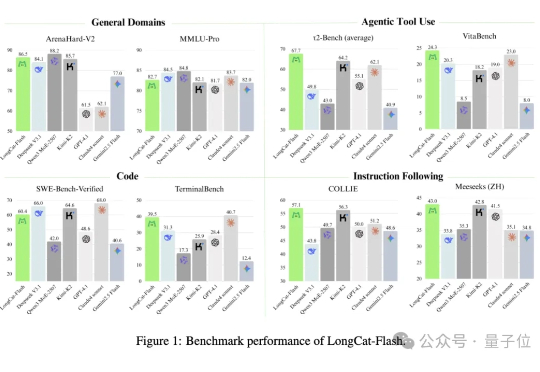
没想到啊,最新SOTA的开源大模型…… 来自一个送外卖(Waimai)的——有两个AI,确实不一样。 这个最新开源模型叫:Longcat-Flash-Chat,美团第一个开源大模型,发布即开源,已经在海内外的技术圈子里火爆热议了。
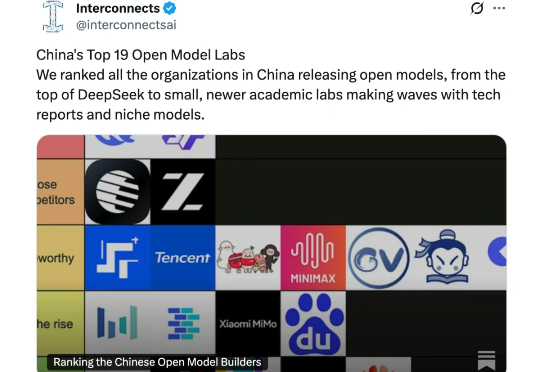
近日,随着新一代大语言模型(LLM)的一波更新,开源大模型再次成为了热门讨论话题。软件工程师、自媒体 Rohan Paul 发现了一个惊人的现象:Design Arena 排行榜上排名前十几位开源 AI 模型全部来自中国。
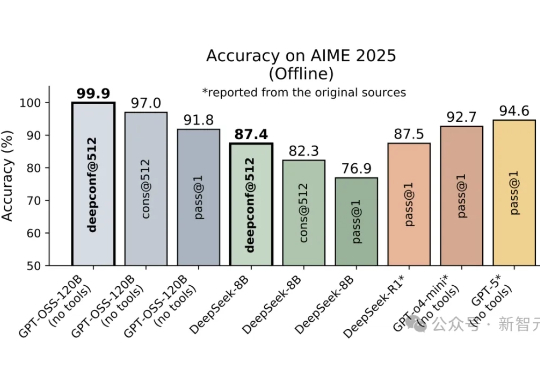
DeepConf由Meta AI与加州大学圣地亚哥分校提出,核心思路是让大模型在推理过程中实时监控置信度,低置信度路径被动态淘汰,高置信度路径则加权投票,从而兼顾准确率与效率。在AIME 2025上,它首次让开源模型无需外部工具便实现99.9%正确率,同时削减85%生成token。
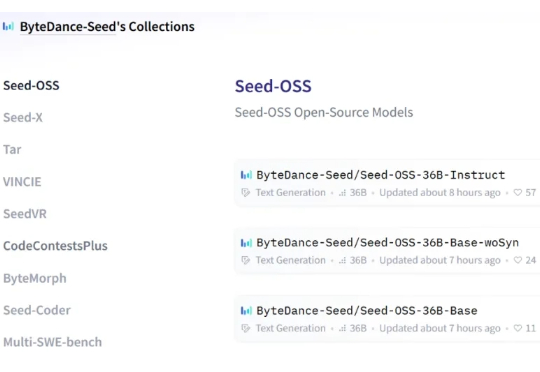
开源赛道也是热闹了起来。 就在深夜,字节跳动 Seed 团队正式发布并开源了 Seed-OSS 系列模型,包含三个版本: Seed-OSS-36B-Base(含合成数据) Seed-OSS-36B-Base(不含合成数据) Seed-OSS-36B-Instruct(指令微调版)

从 Sora 的惊艳亮相到多款高性能开源模型的诞生,视频生成在过去两年迎来爆发式进步,已能生成几十秒的高质量短片。然而,要想生成时长超过 1 分钟、内容与运动可控、风格统一的超长视频,仍面临巨大挑战。