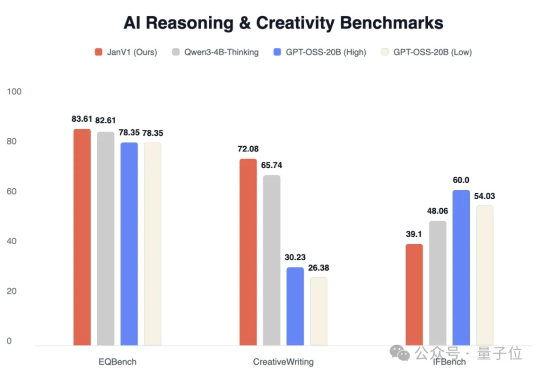
实测Perplexity Pro平替模型,免费开源仅4B
实测Perplexity Pro平替模型,免费开源仅4B有趣,一款仅4B大小的开源模型Jan-v1,居然声称能平替Perplexity Pro。 并且完全免费,支持本地部署。
来自主题: AI资讯
8704 点击 2025-08-16 17:31
 搜索
搜索
有趣,一款仅4B大小的开源模型Jan-v1,居然声称能平替Perplexity Pro。 并且完全免费,支持本地部署。
上上周一的晚上,智谱开源了当今最好的模型之一,GLM-4.5。 然后,这个周一,又是突如其来的,开源了他们现在最好的多模态模型: GLM-4.5v。
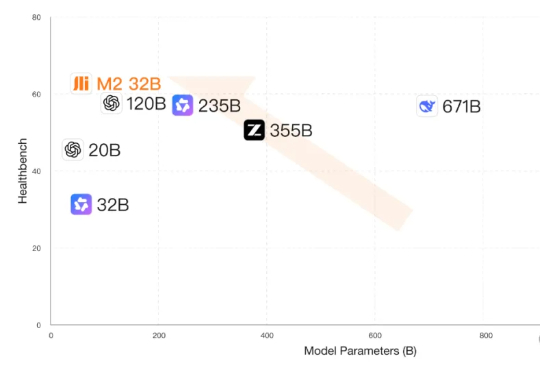
刚刚,全球最强开源医疗模型发布,来自中国。百川开源最新医疗推理大模型Baichuan-M2-32B,在OpenAI发布的Healthbench评测集上,超越其刚刚发布5天的开源模型gpt-oss-120b。

硅星人独家了解到,星海图即将开源全球首个开放场景高质量真机数据集Galaxea Open-World Dataset,及其G0-快慢双系统全身智能VLA模型。这一举动无疑在相对各自为战的机器人行业打开了一条新的路径。
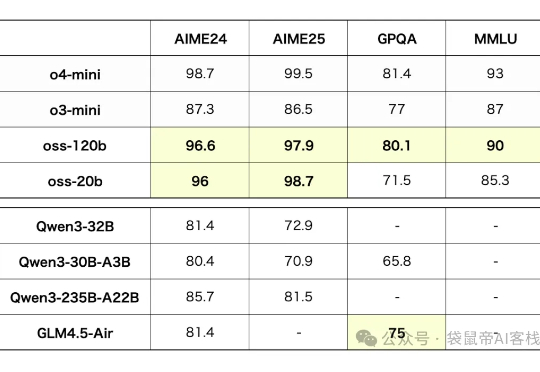
一直被称为"CloseAI"的OpenAI,终于舍得发布了他们继GPT-2之后的第一个开源模型:GPT-OSS
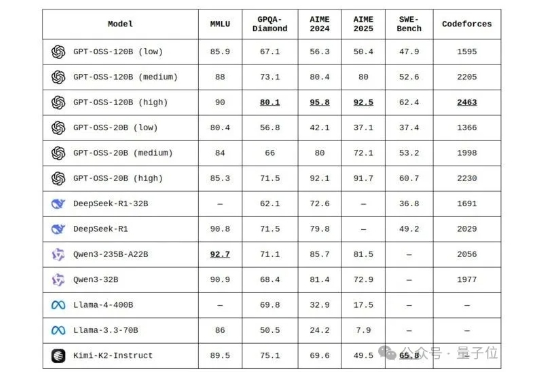
全网开扒GPT-oss,惊喜发现…… 奥特曼还是谦虚了,这性能岂止是o4-mini的水平,直接SOTA击穿一众开源模型。

7月底 Black Forest Labs 和 Krea 合作开发的高级文本到图像生成模型 Flux.1 Krea Dev,最近终于有时间进行测评了。Flux.1 Krea Dev 是基于FLUX.1 dev 模型进行蒸馏的,参数规模12B,专注于提升图像的美学和真实感,避免了常见的 AI 生成痕迹(过度饱和或不自然高光等等),更倾向于追求自然细节、照片级真实感和多样性。
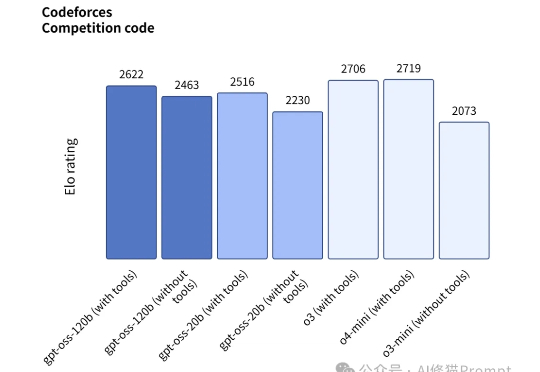
昨晚OpenAI官方放了个大招,发布了gpt-oss-120b和gpt-oss-20b两款开源模型,这是一个专为Agent而生的模型,而且开源了。
8月6号,真的今夕是何年了。 一晚上,三个我觉得都蛮大的货。

今天凌晨,OpenAI 甩出一对王炸,正式发布两款开源模型:gpt-oss-120b 和 gpt-oss-20b。是的,你没看错,那个曾经被戏称为 CloseAI 的男人,带着他的诚意,回来了!