
速递|10亿美金挑战DeepSeek,红杉、光速资本押注,Reflection AI开源模型守塔
速递|10亿美金挑战DeepSeek,红杉、光速资本押注,Reflection AI开源模型守塔成立仅一年的初创公司Reflection AI 正洽谈融资逾 10 亿美元,用于开发开源大语言模型,与中国深度求索(DeepSeek)、法国 Mistral 及美国 Meta 等企业展开竞争。
来自主题: AI资讯
9859 点击 2025-08-05 16:32
 搜索
搜索
成立仅一年的初创公司Reflection AI 正洽谈融资逾 10 亿美元,用于开发开源大语言模型,与中国深度求索(DeepSeek)、法国 Mistral 及美国 Meta 等企业展开竞争。
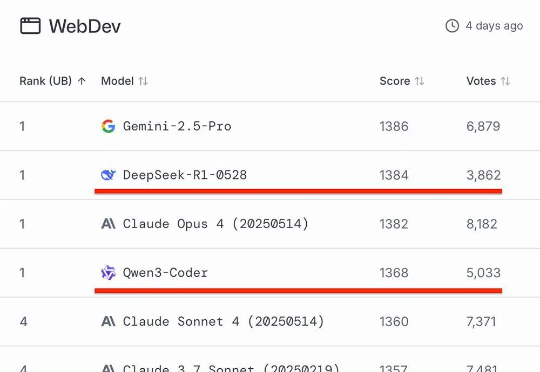
知名AI大模型评测Chatbot Arena放榜!阿里Qwen3-235B-A22B-Instruct-2507位列大语言模型总榜第三,月之暗面Kimi-K2-0711-preview、深度求索DeepSeek-R1-0528并列为总榜第五,以开源之姿超越Claude 4、GPT-4.1等顶尖闭源模型。

OpenRouter 再度上线了一款新模型,Horizon Beta 。这款模型是之前上线的模型Horizon Alpha 的提升版本。不出意外,这款模型也是来自于 OpenAI。
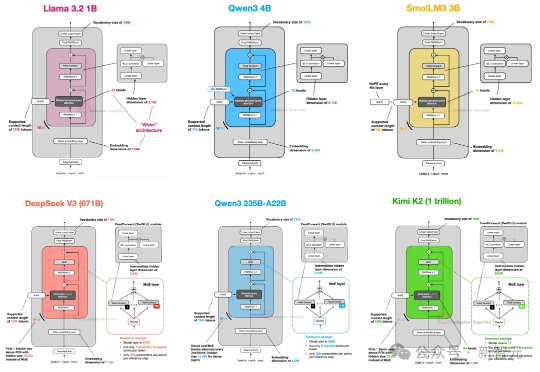
从GPT-2到DeepSeek-V3和Kimi K2,架构看似未变,却藏着哪些微妙升级?本文深入剖析2025年顶级开源模型的创新技术,揭示滑动窗口注意力、MoE和NoPE如何重塑效率与性能。
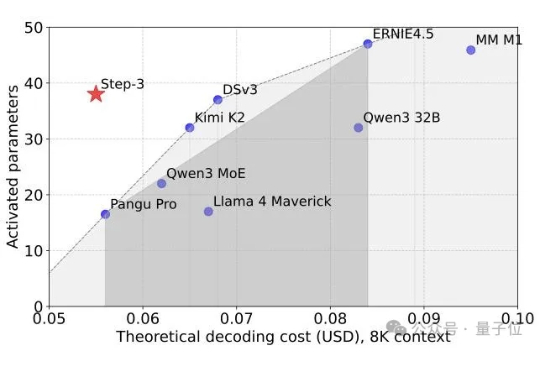
又一个SOTA基础模型开源,而且依然是国产。 刚刚,阶跃星辰兑现了WAIC上的承诺,将最新多模态推理模型Step-3正式开源! 在MMMU等多个多模态榜单上,它一现身就取得了开源多模态推理模型新SOTA的成绩。
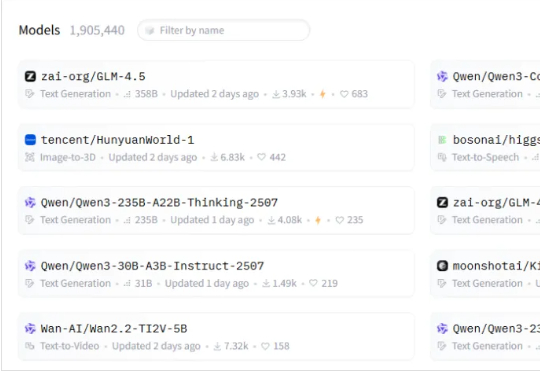
最近,国产模型开源非常多。 MiniMax、Kimi、Qwen、混元、智谱、昆仑万维等等,都在疯狂开源。
Meta 联合创始人兼首席执行官马克・扎克伯格从 OpenAI、谷歌和苹果等公司挖走了众多顶尖 AI 研究人员,并开出了数亿美元的薪酬,此举震惊了整个科技行业。现在,他正在更多地分享他对超级智能的愿景。
家人们!燃起来了燃起来了! 今天,HuggingFace的开源大模型排行榜前10名中,竟有9个席位被中国模型占据!(深挖了一下,另外一位也是我们华人大神的项目)

WebAgent 续作《WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization》中
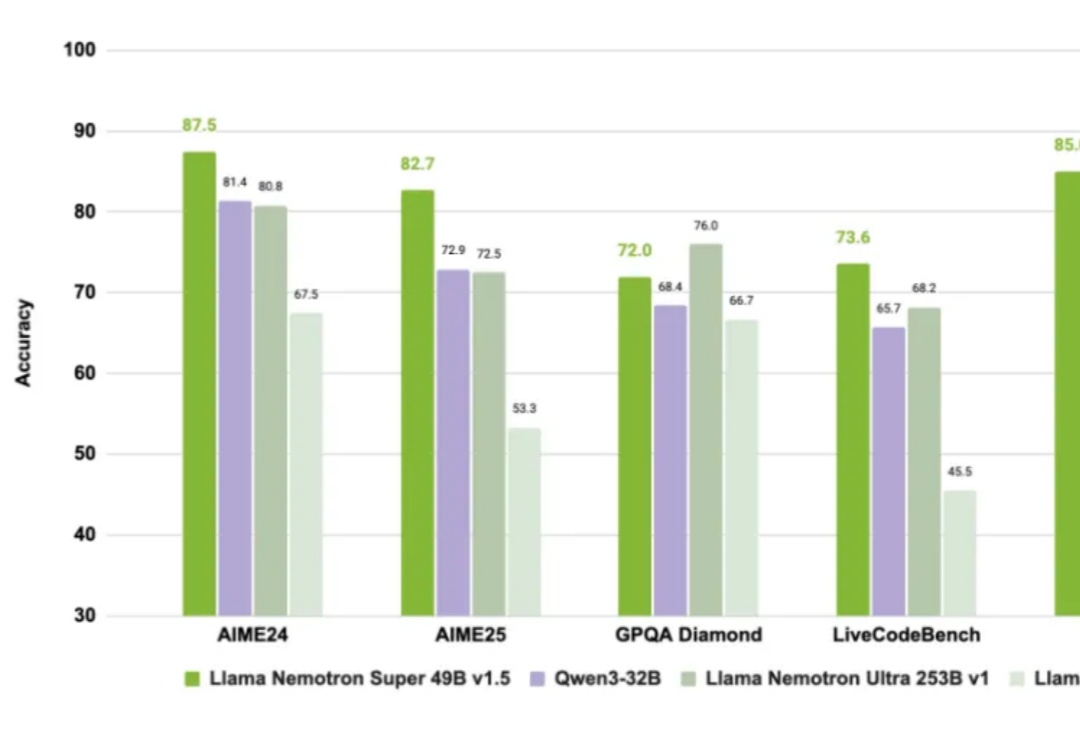
众所周知,老黄不仅卖铲子(GPU),还自己下场开矿(造模型)。