
今夜,国产AI最强一击!智谱发布GLM-4.5,新一代模型狙击OpenAI
今夜,国产AI最强一击!智谱发布GLM-4.5,新一代模型狙击OpenAI智谱新一代旗舰「融合大模型」GLM-4.5,集成推理、代码与智能体能力,实现原生智能体模式。
来自主题: AI资讯
10703 点击 2025-07-29 10:43
 搜索
搜索
智谱新一代旗舰「融合大模型」GLM-4.5,集成推理、代码与智能体能力,实现原生智能体模式。
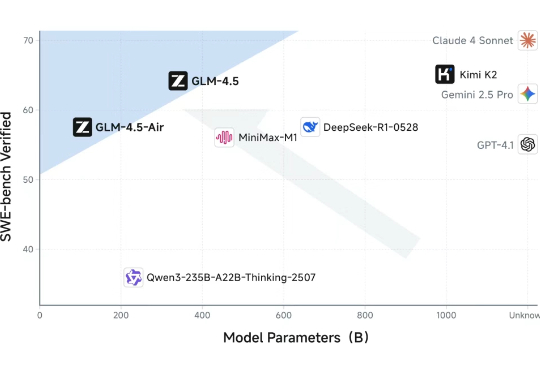
又一家支持Claude Code的模型登场! GLM-4.5 在推理、代码、Agent(智能体)综合能力都达到了开源模型Top1水准,在单个模型中实现了推理、代码、Agentic等能力原生融合。

就在刚刚,智谱正式发布最新旗舰模型 GLM-4.5。按照智谱官方说法,这是一款专为 Agent 应用打造的基础模型。延续一贯的开源原则,目前这款模型已经在 Hugging Face 与 ModelScope 平台同步开源,模型权重遵循 MIT License。
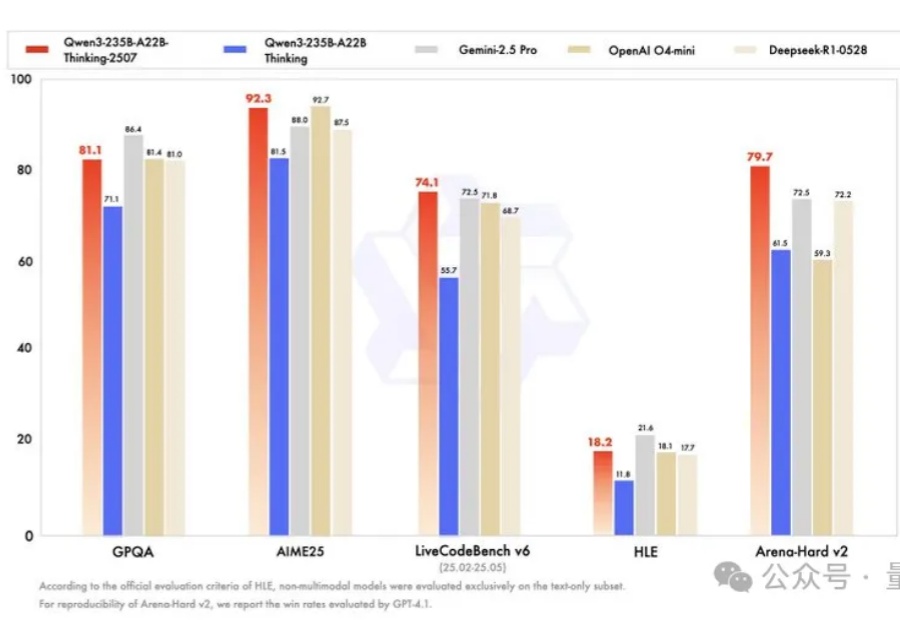
卷疯了,通义千问真的卷疯了。

就在刚刚,阿里正式发布全球最强开源推理模型——Qwen3-235B-A22B-Thinking-2507。就在刚刚,阿里正式发布全球最强开源推理模型——Qwen3-235B-A22B-Thinking-2507。

刚刚,美国AI行动计划正式上线!28页PDF围绕三大支柱:AI创新、AI基础设施、全球AI规则,推出90多项行政令。放松AI监管、全球推广开源模型,大力投资超算、半导体建设等,直指全球AI霸主地位。

编程Agent王座,国产开源模型拿下了!就在刚刚,阿里通义大模型团队开源Qwen3-Coder,直接刷新AI编程SOTA——不仅在开源界超过DeepSeek V3和Kimi K2,连业界标杆、闭源的Claude Sonnet 4都比下去了。
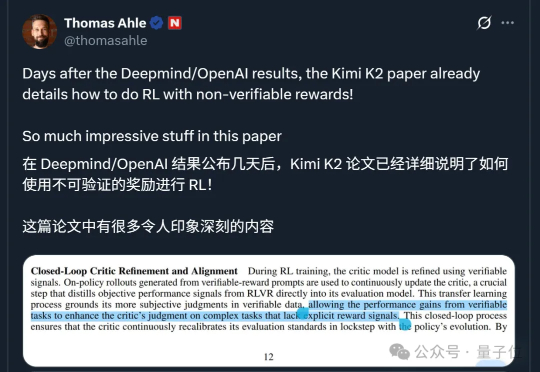
Kimi K2称霸全球开源模型的秘籍公开了!
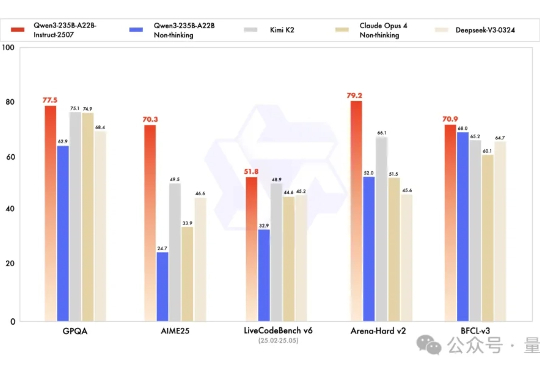
开源大模型正在进入中国时间。 Kimi K2风头正盛,然而不到一周,Qwen3就迎来最新升级,235B总参数量仅占Kimi K2 1T规模的四分之一。 基准测试性能上却超越了Kimi K2。
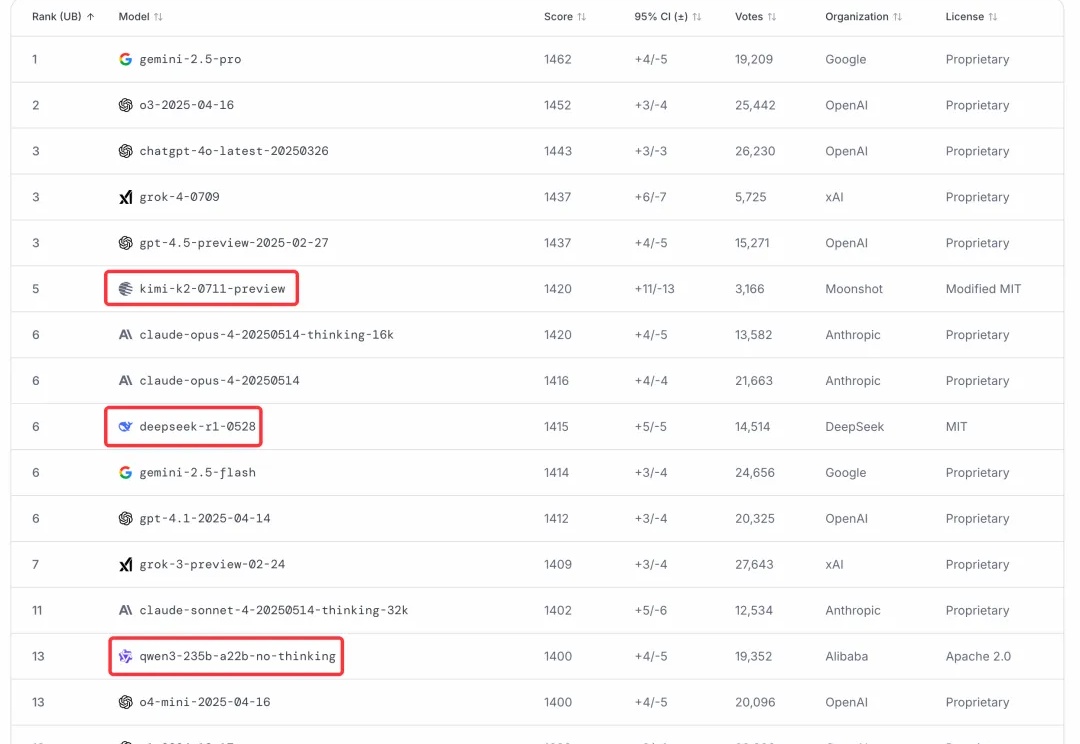
关于 Kimi K2 的讨论还在发酵。