OpenAI再次跳票,奥特曼:开源模型无限期推迟!
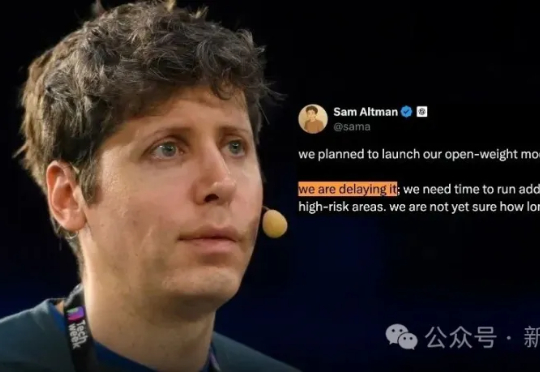
OpenAI再次跳票,奥特曼:开源模型无限期推迟!奥特曼宣布无限期推迟OpenAI开源模型发布。与此同时,竞争对手正高调上新,开源赛道硝烟四起。这次跳票不仅令开发者和科技爱好者失望,也让外界再次质疑OpenAI在「Open」与商业利益之间的身份撕裂与信任危机。
来自主题: AI资讯
10240 点击 2025-07-14 10:18
 搜索
搜索
奥特曼宣布无限期推迟OpenAI开源模型发布。与此同时,竞争对手正高调上新,开源赛道硝烟四起。这次跳票不仅令开发者和科技爱好者失望,也让外界再次质疑OpenAI在「Open」与商业利益之间的身份撕裂与信任危机。

最新研究发现,模型的规模和通用语言能力与其处理敏感内容的判断能力并无直接关联,甚至开源模型表现的更好。

7月5日下午16:59分,隶属于华为的负责开发盘古大模型的诺亚方舟实验室发布声明对于“抄袭”指控进行了官方回应。诺亚方舟实验室表示,盘古Pro MoE开源模型是基于昇腾硬件平台开发、训练的基础大模型,并非基于其他厂商模型增量训练而来,在架构设计、技术特性等方面做了关键创新,是全球首个面向昇腾硬件平台设计的同规格混合专家模型
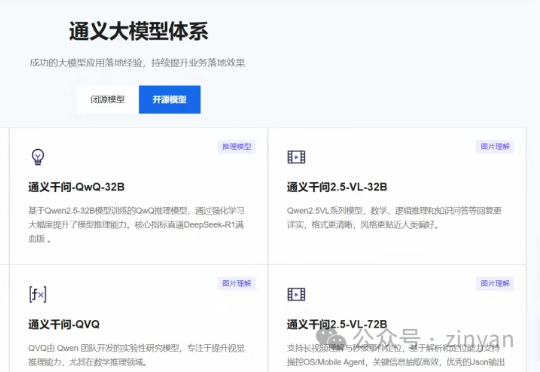
最近,看到各大厂商,在不断地将自己的AI大模型进行开源。华为宣布开源:盘古7B稠密和72B混合专家模型。

OpenAI计划发布一个非常强大的开源模型。它能够让人们在本地运行极其强大的模型,重新认识“本地部署”的可能性。
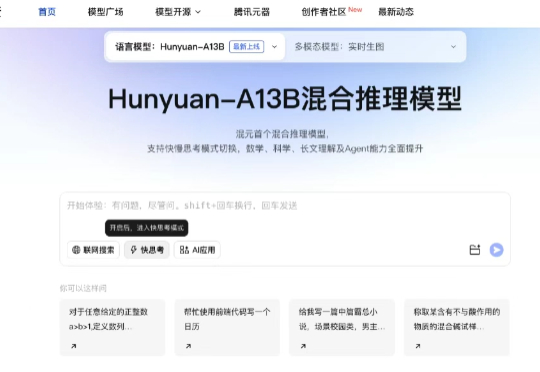
6 月 27 日,腾讯混元宣布开源首个混合推理 MoE 模型 Hunyuan-A13B,总参数 80B,激活参数仅 13B,效果比肩同等架构领先开源模型,但是推理速度更快,性价比更高。模型已经在 Github 和 Huggingface 等开源社区上线,同时模型 API 也在腾讯云官网正式上线,支持快速接入部署。
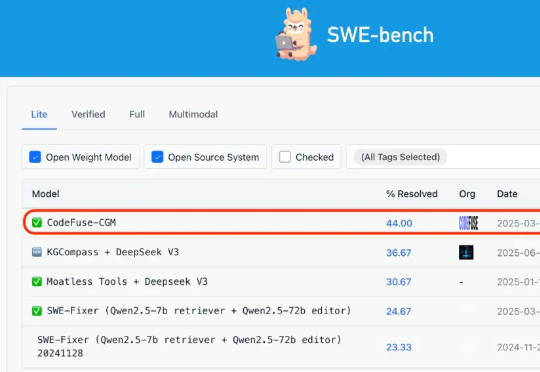
Agentless+开源模型,也能高质量完成仓库级代码修复任务,效果媲美业界 SOTA 。
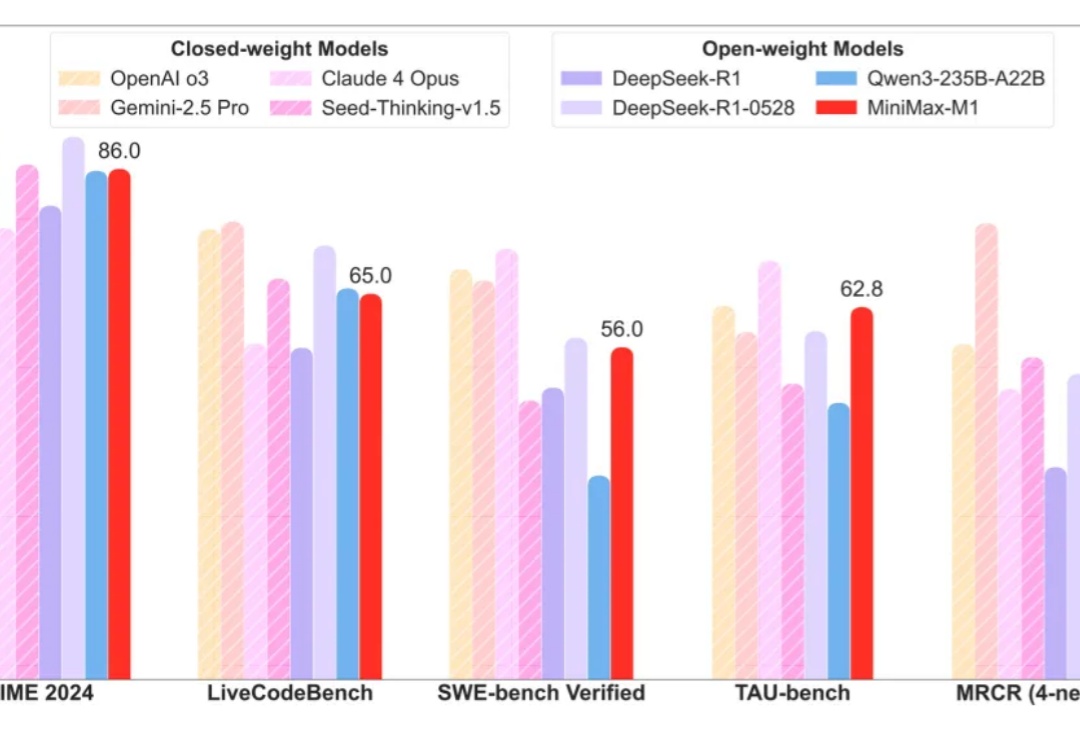
最近,我的AI交流群和别的一些AI群都炸锅了,话题的焦点是MiniMax-M1
昨天深夜,月之暗面发布了开源代码模型Kimi-Dev-72B。这个模型在软件工程任务基准测试SWE-bench Verified上取得了60.4%的成绩,创下开源模型新纪录,超越了包括DeepSeek在内的多个竞争对手。
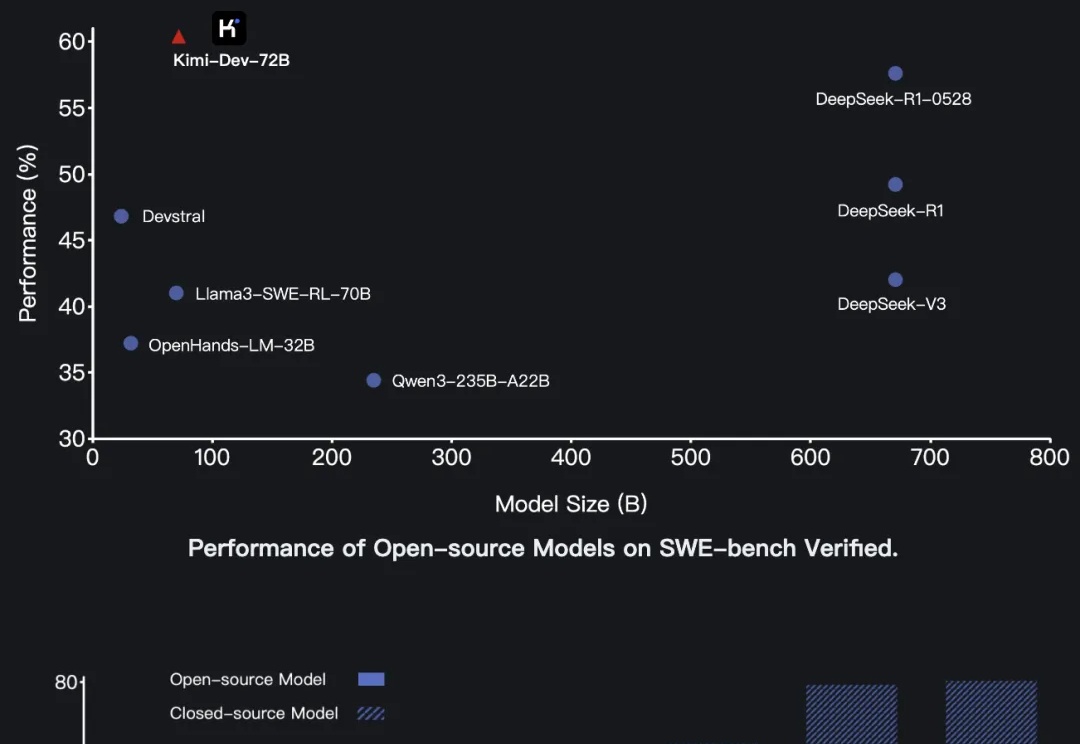
深夜,沉寂已久的Kimi突然发布了新模型—— 开源代码模型Kimi-Dev,在SWE-bench Verified上以60.4%的成绩取得开源SOTA。