苹果AI新进展:Qwen3已全面“登陆”苹果MLX框架
苹果AI新进展:Qwen3已全面“登陆”苹果MLX框架在苹果AI中国版一片静默之际,阿里出牌了。
来自主题: AI资讯
8902 点击 2025-06-17 11:34
 搜索
搜索
在苹果AI中国版一片静默之际,阿里出牌了。

在开源模型领域,DeepSeek 又带来了惊喜。
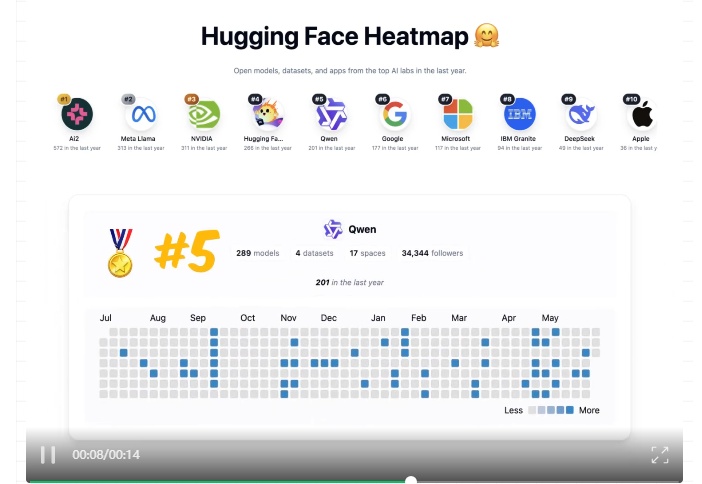
全球知名开源AI平台Hugging Face近日发布开放权重模型贡献榜,中国团队Qwen和DeepSeek成功入围前15名,彰显了中国在全球开源AI领域的技术实力与影响力。该榜单表彰为开源社区提供高质量模型权重的团队,其模型广泛应用于学术与产业创新。
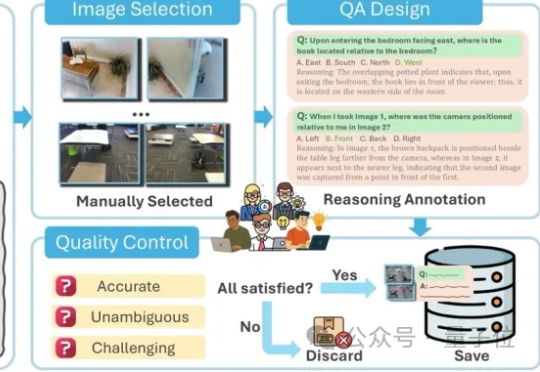
AI能看图,也能讲故事,但能理解“物体在哪”“怎么动”吗? 空间智能,正是大模型走向具身智能的关键拼图。

用AI来整理会议内容,已经是人类的常规操作。 不过,你猜怎么着?面对1000道多步骤音频推理题时,30款AI模型竟然几乎全军覆没,很多开源模型表现甚至接近瞎猜。
能够完成多步信息检索任务,涵盖多轮推理与连续动作执行的智能体来了。通义实验室推出WebWalker(ACL2025)续作自主信息检索智能体WebDancer。

智源研究院发布开源模型Video-XL-2,显著提升长视频理解能力。该模型在效果、处理长度与速度上全面优化,支持单卡处理万帧视频,编码2048帧仅需12秒。
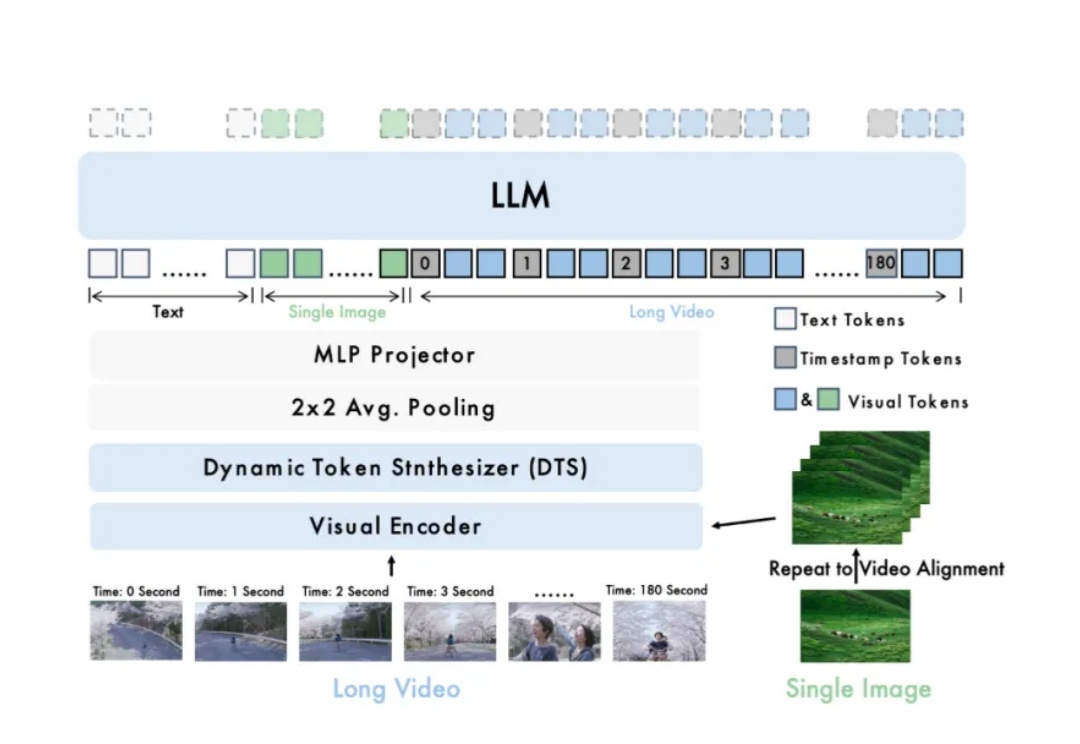
长视频理解是多模态大模型关键能力之一。尽管 OpenAI GPT-4o、Google Gemini 等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。
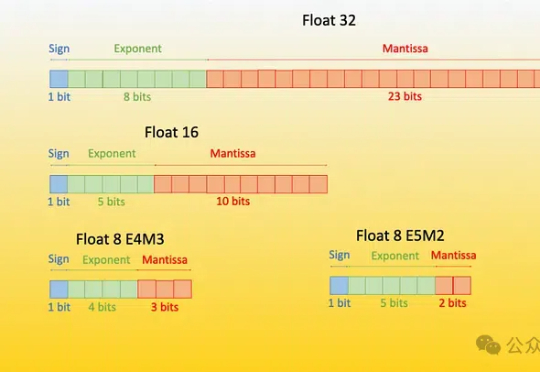
原生1bit大模型BitNet b1.58 2B4T再升级!微软公布BitNet v2,性能几乎0损失,而占用内存和计算成本显著降低。
今天,我们正式发布 DeepSeek-R1,并同步开源模型权重。DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。DeepSeek-R1 上线API,对用户开放思维链输出,通过设置 `model='deepseek-reasoner'` 即可调用。