# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
原生多模态大模型性能瓶颈,迎来新突破!
上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。
与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。
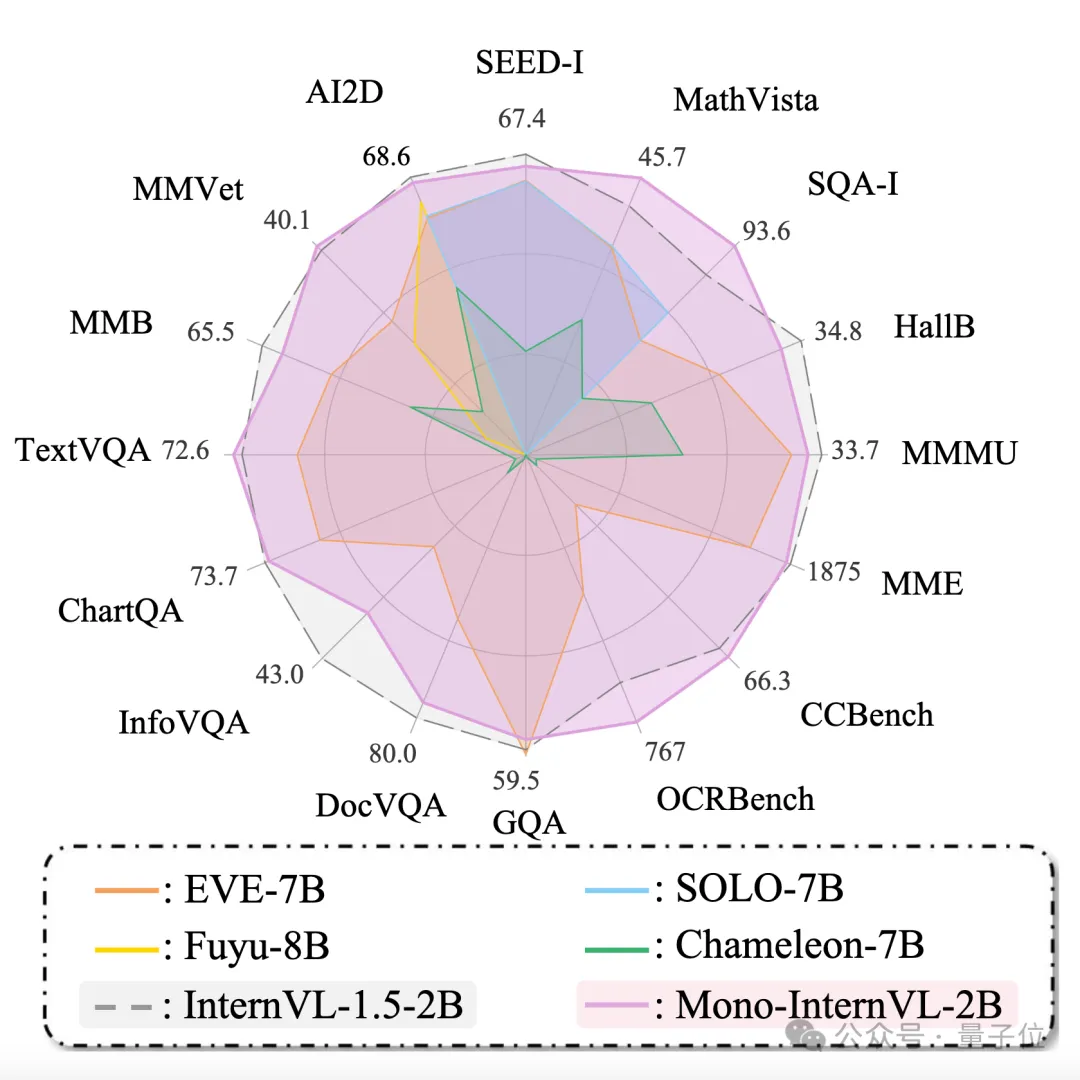
与常见的采用CLIP等结构进行视觉编码的模块化多模态大模型不同,Mono-InternVL将视觉感知和多模态理解均集成到大语言模型中。
相比于现有多模态大模型,Mono-InternVL有以下技术亮点:
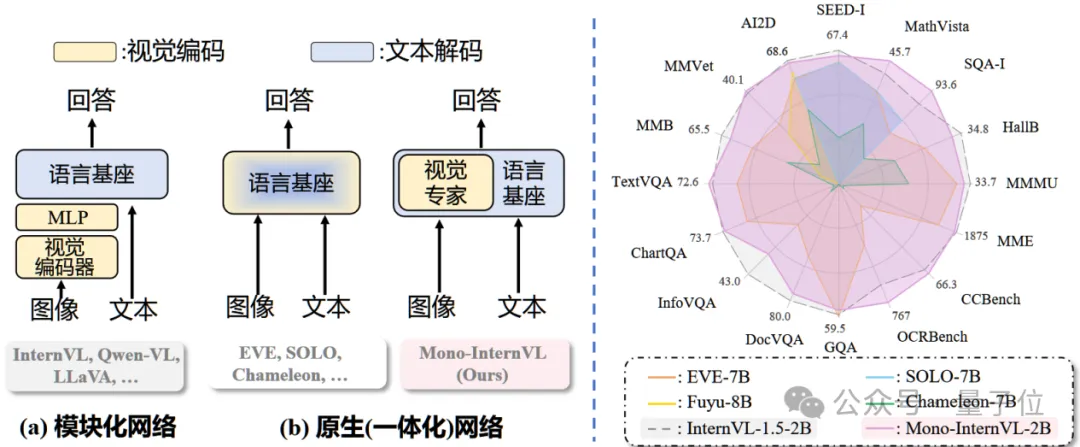
现有的多模态大模型(MLLM)通常采用视觉编码器-对齐模块-语言模型的结构,将视觉编码和语言解码分别进行处理。
具体来说,这些模型通常通过将预训练的视觉编码器(例如CLIP)与大语言模型(LLM)结合来实现,即模块化MLLM。
最近新兴的Chameleon、EVE等原生MLLM,将视觉感知和多模态理解直接集成到一个LLM中,可以更方便地通过现有工具进行部署、具备更高的推理效率。
然而,由于原生MLLM缺乏视觉能力,视觉相关的训练通常不可避免,但视觉预训练过程中语言基座能力常常出现灾难性遗忘问题,导致现有原生MLLM的性能仍显著低于模块化MLLM。
为此,Mono-InternVL提出了采用增量预训练的方法,解决此前原生MLLM中的灾难性遗忘问题。
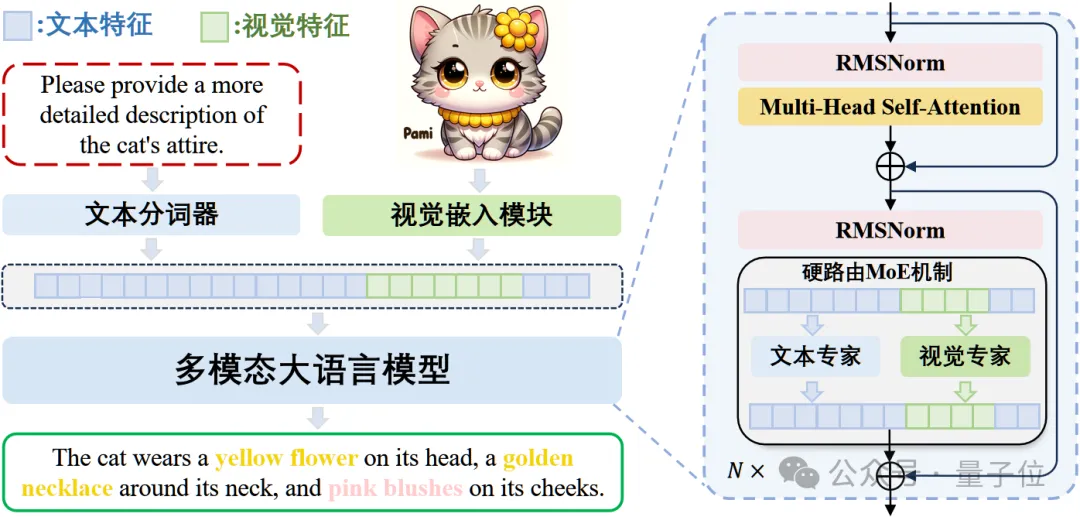
因此,作者在预训练的LLM中嵌入了专门服务于视觉建模的视觉专家,通过MoE的方式实现稀疏化的建模。
基于此,作者通过仅优化视觉参数空间来进行视觉预训练,同时保留了语言基座的预训练知识。
具体来说,Mono-InternVL 由视觉文本嵌入和多模态MoE结构两部分组成:
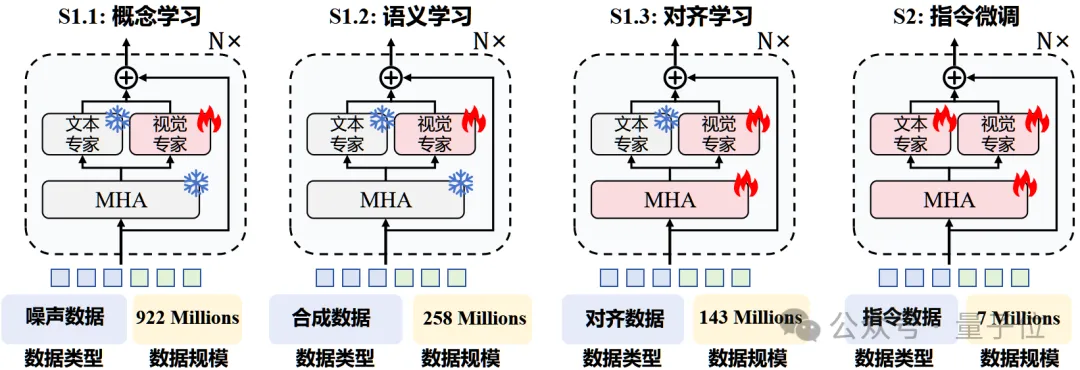
作者提出内生视觉预训练(EViP)方法,旨在通过在大规模噪声数据和合成数据上进行预训练来最大化Mono-InternVL的视觉能力。
EViP被设计为一个从基本视觉概念到复杂语义知识的逐步学习过程,包括三个阶段:
在视觉预训练完成后,Mono-InternVL通过指令微调处理复杂的多模态任务。
在前两个阶段中保持预训练LLM的参数固定,仅训练视觉部分的嵌入模块和视觉FFN,而在第三阶段和指令微调中逐步放开LLM中的multi-head attention和文本FFN。
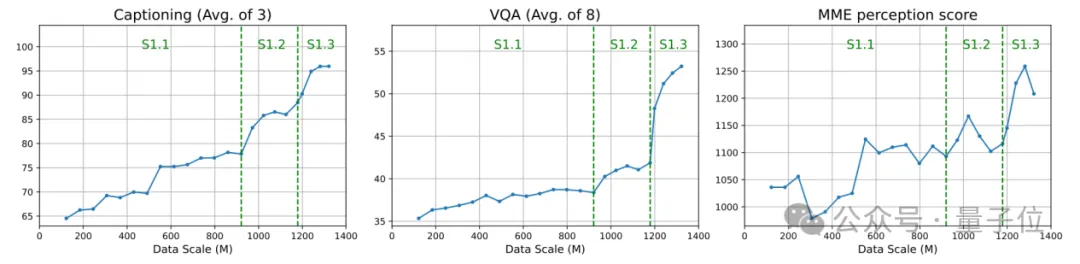
得益于这一架构和预训练策略,Mono-InternVL的视觉可扩展性得到了充分释放,随着预训练数据规模的增加,其下游性能持续提高。
作者基于InternLM2-1.8B开发了Mono-InternVL-2B模型,在16个多模态基准上进行了广泛的实验。
下图展示了中英文OCR、问答、图表解析等任务的可视化样例,体现了Mono-InternVL的实际效果。
如图,模型成功识别出了图中的“诺贝尔物理学奖2024”标题,Hopfield、Hinton等人名,以及瑞典皇家科学院落款等文本。

对于动漫风格的图片,模型识别出了形状扭曲的NEC、PANASONIC等品牌名,并提供了细致生动的图像描述。

在Grounding任务上,Mono-InternVL可以精准定位照片中的美短的坐标。

对于中文的手写文本同样具备不错的识别能力。

在代码生成任务上也表现较为出色。

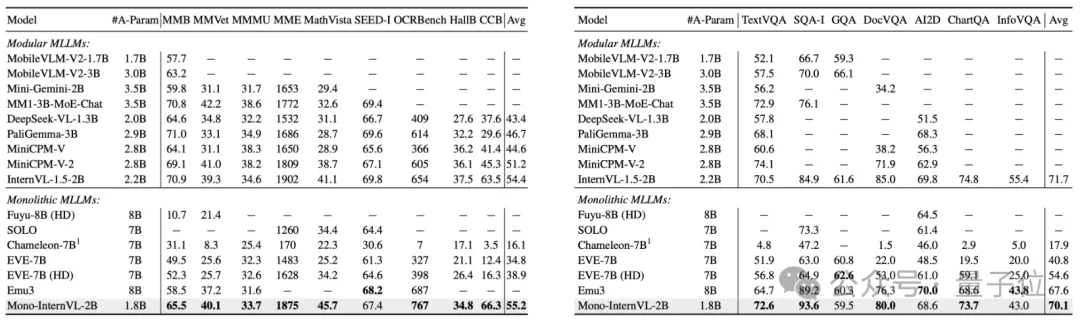
数据上看,实验结果也表明,1.8B激活参数的Mono-InternVL可以大幅超越此前的7B参数原生多模态模型EVE,平均提升15.5%。
与最先进的模块化MLLM InternVL-1.5相比,Mono-InternVL在6个多模态基准上表现更优。
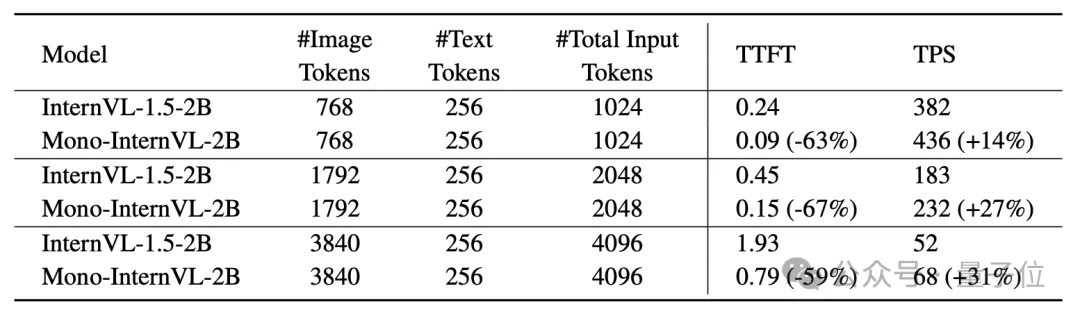
通过LMDeploy的部署实验表明,Mono-InternVL与模块化模型InternVL-1.5相比,首个token延迟减少了67%,整体吞吐量提高31%。
消融实验结果,也验证了视觉专家和增量预训练的有效性。

下游任务性能与预训练数据规模的曲线图表明,在三阶段的EViP的帮助下,Mono-InternVL 的能力随着数据规模增加而不断提升。
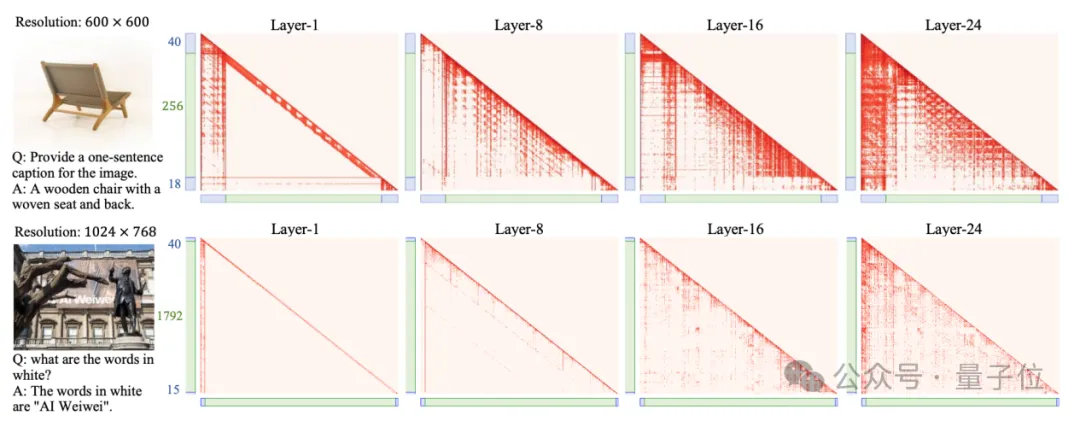
作者可视化了不同层的注意力图,展示了模型浅层部分所存在的视觉局部性、视觉文本交互较少等问题,为未来原生MLLM 的设计提供启发。
本文的共同一作为罗根 (上海人工智能实验室博士后研究员),杨学(上海人工智能实验室青年研究员),窦文涵(清华大学本科生),王肇凯(上海交通大学&上海人工智能实验室联培博士生)。
本文的通讯作者是朱锡洲,他的研究方向是视觉基础模型和多模态基础模型,代表作有 Deformable DETR、DCN v2等。

论文地址:
https://arxiv.org/abs/2410.08202
项目主页:
https://internvl.github.io/blog/2024-10-10-Mono-InternVL/
推理代码&模型链接:
https://huggingface.co/OpenGVLab/Mono-InternVL-2B
文章来自于微信公众号“量子位”,作者“ Mono-InternVL团队”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
