# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在多模态领域,开源模型也超闭源了!
就在刚刚结束的Meta开发者大会上,Llama 3.2闪亮登场:
这回不仅具备了多模态能力,还和Arm等联手,推出了专门为高通和联发科硬件优化的“移动”版本。

具体来说,此次Meta一共发布了Llama 3.2的4个型号:
官方数据显示,与同等规模的“中小型”大模型相比,Llama 3.2 11B和90B表现出了超越闭源模型的性能。
尤其是在图像理解任务方面,Llama 3.2 11B超过了Claude 3 Haiku,而90B版本更是能跟GPT-4o-mini掰掰手腕了。
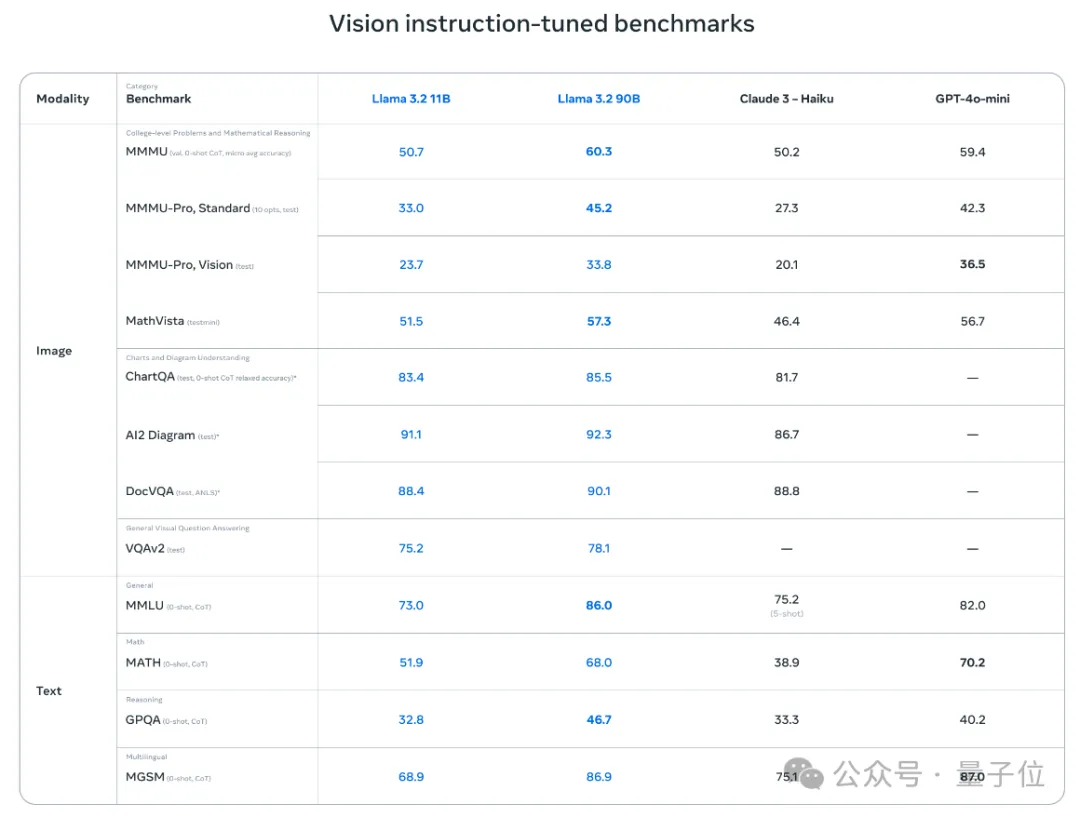
而专为端侧打造的3B版本,在性能测试中表现也优于谷歌的Gemma 2 2.6B和微软的Phi 3.5-mini。
如此表现,着实吸引了不少网友的关注。
有人兴奋地认为,Llama 3.2的推出可能再次“改变游戏规则”:
端侧AI正在变得越来越重要。

Meta AI官方对此回复道:
其中一些模型参数量很小,但这个时刻意义重大。

有关Llama 3.2具体能做什么,这次官方也释出了不少demo。
先看个汇总:Llama 3.2 11B和90B支持一系列多模态视觉任务,包括为图像添加字幕、根据自然语言指令完成数据可视化等等。

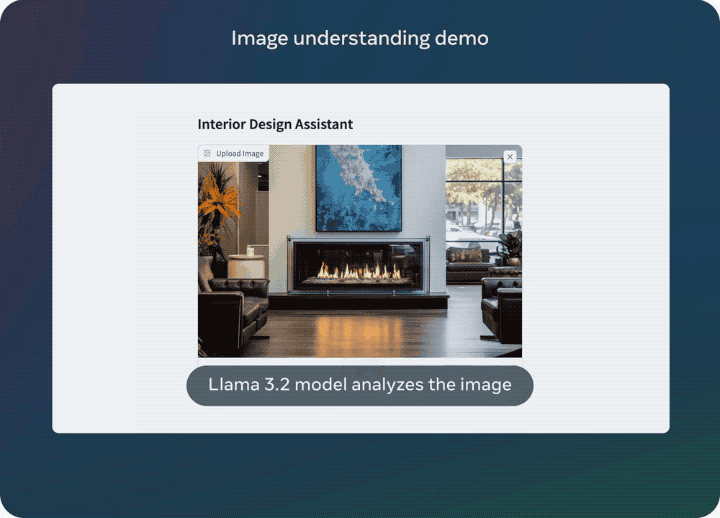
举个????,丢给Llama 3.2一张图片,它能把图片中的元素一一拆解,告诉你详细的图片信息:
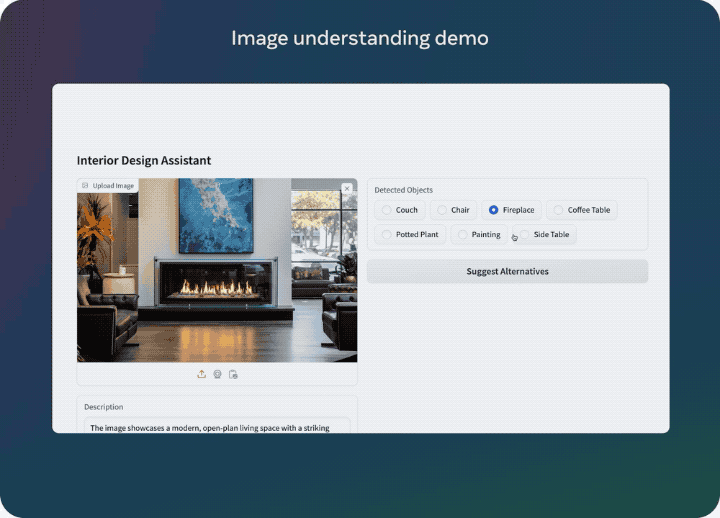
同样,也可以反过来根据文字指令找出符合用户需求的图片。
Llama 3.2 11B和90B也是首批支持多模态任务的Llama系列模型,为此,Meta的研究人员打造了一个新的模型架构。
在Llama 3.1的基础之上,研究人员在不更新语言模型参数的情况下训练了一组适配器权重,将预训练的图像编码器集成到了预训练的语言模型中。
这样,Llama 3.2既能保持纯文本功能的完整性,也能get视觉能力。
训练过程中,Llama 3.2采用图像-文本对数据进行训练。训练分为多个阶段,包括在大规模有噪声数据上的预训练,和更进一步在中等规模高质量领域内和知识增强数据上的训练。
在后训练(post-training)中,研究人员通过监督微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO)进行了几轮对齐。
至于1B和3B这两个轻量级模型,目的更加清晰:
随着苹果Apple Intelligence的推出,对于电子消费市场而言,手机等终端上的生成式AI已经成为标配。
而脱离云端独立运行在终端上的模型,无论是从功能还是从安全的角度,都是终端AIGC落地的关键。
△端侧写作助手
Llama 3.2 1B和3B模型由Llama 3.1的8B和70B模型剪枝、蒸馏得到。
可以简单理解为,这俩“小”模型是Llama 3.1教出来的“学生”。
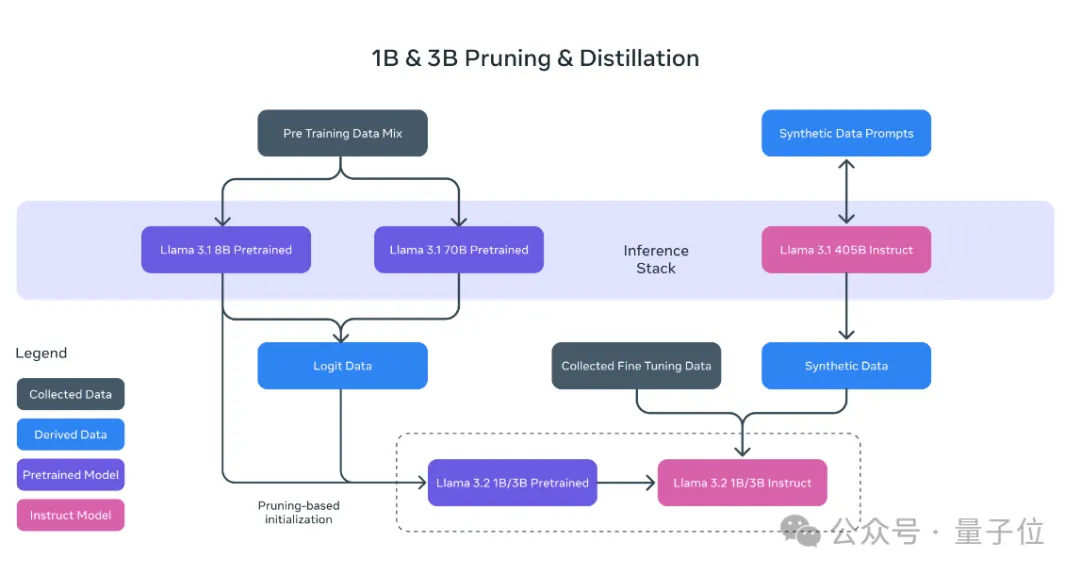
Llama 3.2 1B和3B仅支持文本任务,上下文长度为128K。来自Meta合作方Arm的客户业务线总经理Chris Bergey认为:
明年初甚至今年年底,开发人员就会在应用程序中落地这两个型号的Llama 3.2。
它们拥有更好的效率,能在1W功率下或在8毫秒以内提供答案。
不少网友也为此点赞:
Llama 3.2的轻量级模型能真正改变AI在手机和其他设备上的应用。
还有网友已经第一时间实践上了:
我惊叹于这个1B模型的能力。
这位网友用Llama 3.2 1B运行了一个完整的代码库,并要求它总结代码,结果是酱婶的:

“不完美,但远超预期。”
前有OpenAI「Her」全量开放、谷歌Gemini 1.5迎来重大升级,Llama这边也紧锣密鼓跟上新动作,AI圈的这一周,依旧是开源闭源激情碰撞,充满话题度的一周。
那么,你怎么看Llama这波新发布?
对了,如果你对Llama 3.2感兴趣,大模型竞技场已经可以试玩了。

Ollama、Groq等也已第一时间更新支持。
文章来自于“量子位”,作者“鱼羊”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
