
牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离
牛津、英伟达等提出记忆压缩新范式:训练时让模型学会断舍离2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
来自主题: AI技术研报
9746 点击 2026-06-02 11:23
 搜索
搜索
2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。

2026 年 3 月底,Ollama 发布了一则更新公告:其 Mac 版本的底层推理引擎,将从沿用多年的 llama.cpp 切换为苹果的 MLX 框架。

一位中国开发者,在横跨大西洋的航程中,在飞机上用 MacBook 本地跑 Llama 70B,整整 11 小时没有网络,帖子瞬间在X上爆火!但是随后,越来越多网友发现,这故事不太对啊?
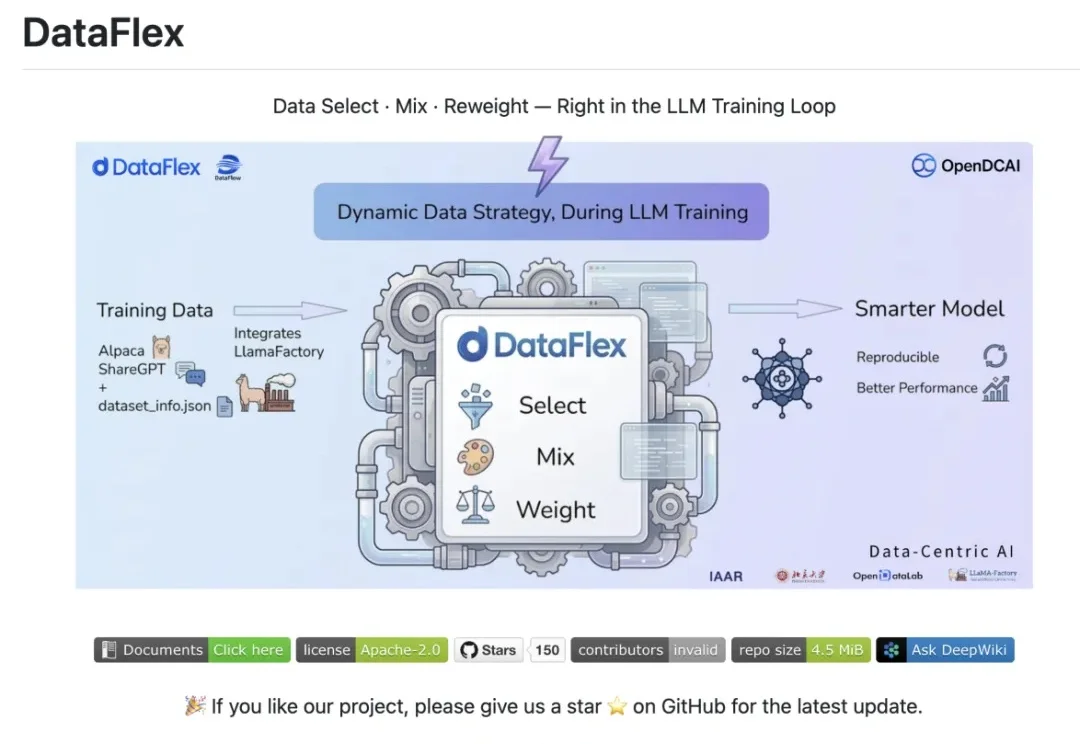
当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。

MiniMax M2.7 在今天正式开源。我们和华为昇腾、摩尔线程、沐曦、昆仑芯、NVIDIA,以及 Together AI、Fireworks、Ollama 等海内外芯片厂商、推理平台携手,在开源首日即完成模型接入与推理适配工作,推动全球 AI 生态繁荣发展。

刚刚,Meta 重金组建的超级智能实验室(SML)交卷!这也是年轻华人 Alexandr Wang 带领该团队后,交出的首份成绩。全新自研模型 Muse Spark 上线。

作为Meta FAIR曾经的资深首席研究员,LLaMA和OpenGo背后的关键推手, 他的研究从破解围棋的机制到优化大模型的肌理, 做的事情从来只有一件:打开黑箱,找到底层逻辑。
刚刚,毕业清华大学数学系,曾在Meta FAIR工作3.75年、主导过SAM与Llama多项核心工作的研究员张鹏川(Pengchuan Zhang)宣布离职。他的下一站,是来到OpenAI,投身于世界模拟与机器人学(World Simulation and Robotics)方向的研究。

刚刚推出的一款最新芯片,直接冲上硅谷热榜。峰值推理速度高达每秒17000个token。什么概念呢?当前公认最强的Cerebras,速度约为2000 token/s。 速度直接快10倍,同时成本骤减20倍、功耗降低10倍。
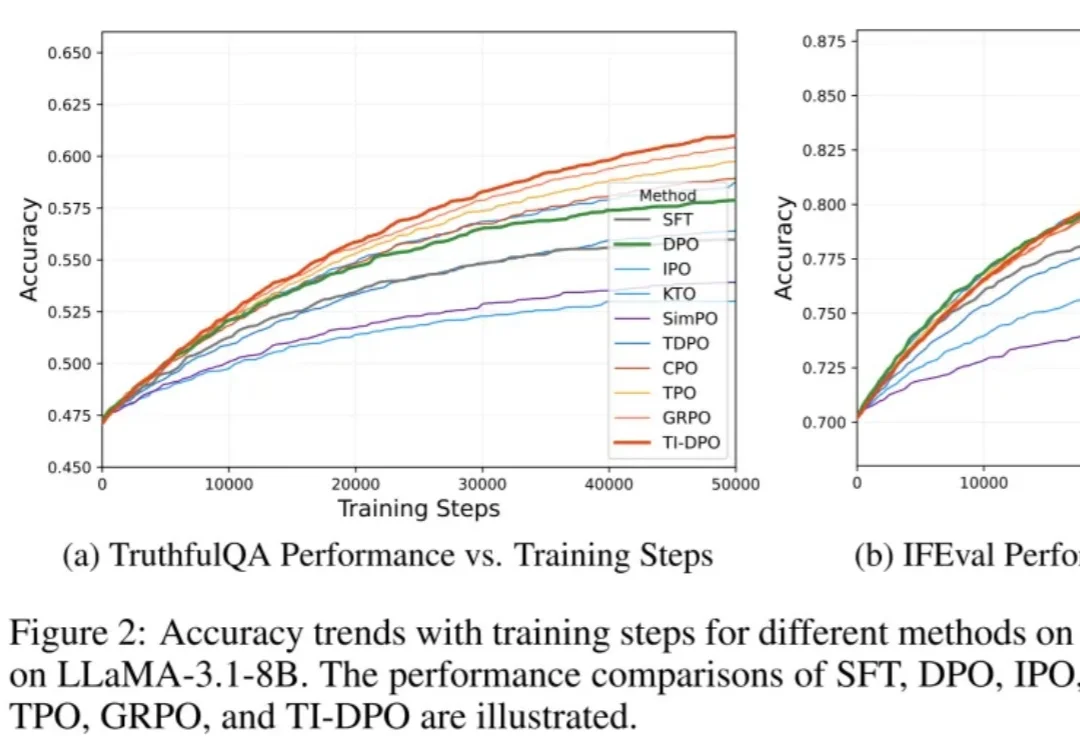
在当今的大模型后训练(Post-training)阶段,DPO(直接偏好优化) 凭借其无需训练独立 Reward Model 的优雅设计和高效性,成功取代 PPO 成为业界的 「版本之子」,被广泛应用于 Llama-3、Mistral 等顶流开源模型的对齐中。