# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
路透社最新消息,Meta 新成立的 AI 团队本月已在内部交付了首批关键模型。据悉,该消息来自 Meta 公司的 CTO Andrew Bosworth,他表示该团队的 AI 模型「非常好」(very good)。
媒体在去年 12 月报道称,Meta 公司正在开发一款代号为 Avocado 的文本 AI 模型,计划于第一季度发布;同时还在开发一款代号为 Mango 的图像和视频 AI 模型。Bosworth 并未透露哪些模型已交付内部使用。
有意思的是,就在这篇报道的前些天,一篇技术报告《Llama 4 家族:架构、训练、评估和部署说明》在 arXiv 悄然上线,其中全面回顾了 Meta Llama 4 系列模型宣称的数据和技术成就。

需要说明,从 arXiv 的记录看,上传这篇报告的作者是 Meta 一位机器学习工程师 Arthur Hinsvark,但这篇报告却并未明确标识来自 Meta。此外,也有人指出上传者可能冒用 Hinsvark 之名上传了这篇报告(待证实)。
尤其值得关注的是,这篇报告将 Llama 4 项目的所有参与者都加入到了作者名单中 —— 超过 1300 名,足足 5 页!因此,我们可以大体上认为这份报告就是来自 Llama 4 团队,尽管其中不少人现在已经从 Meta 离职,比如前 Meta FAIR 团队研究总监田渊栋。
值得注意的是,这篇报告的引言有一段明确说明:「本文档是对公开材料的独立调查。报告的基准数值归因于模型卡,除非另有说明;应将它们视为开发者报告的结果,并对评估工具、提示工程和后处理持通常的保留态度。」
也就是说,这篇报告整体回顾了 Meta 公布的各种 Llama 4 相关材料,尤其是其宣称的一些数据。但没有明确解释其在实际应用中表现明显不及预期的原因。
不过,该报告也不是完全没有提到相关原因,仔细阅读的话,我们能在行文中看到一些端倪,其中主要的讨论点集中在部署限制和榜单争议上:
这些细节似乎暗示了这份报告是 Meta Llama 团队对于 Llama 4 系列模型备受社区广泛批评(数据亮眼但能力很差)的最终回应。
对于这些说明,不知道你怎么看?
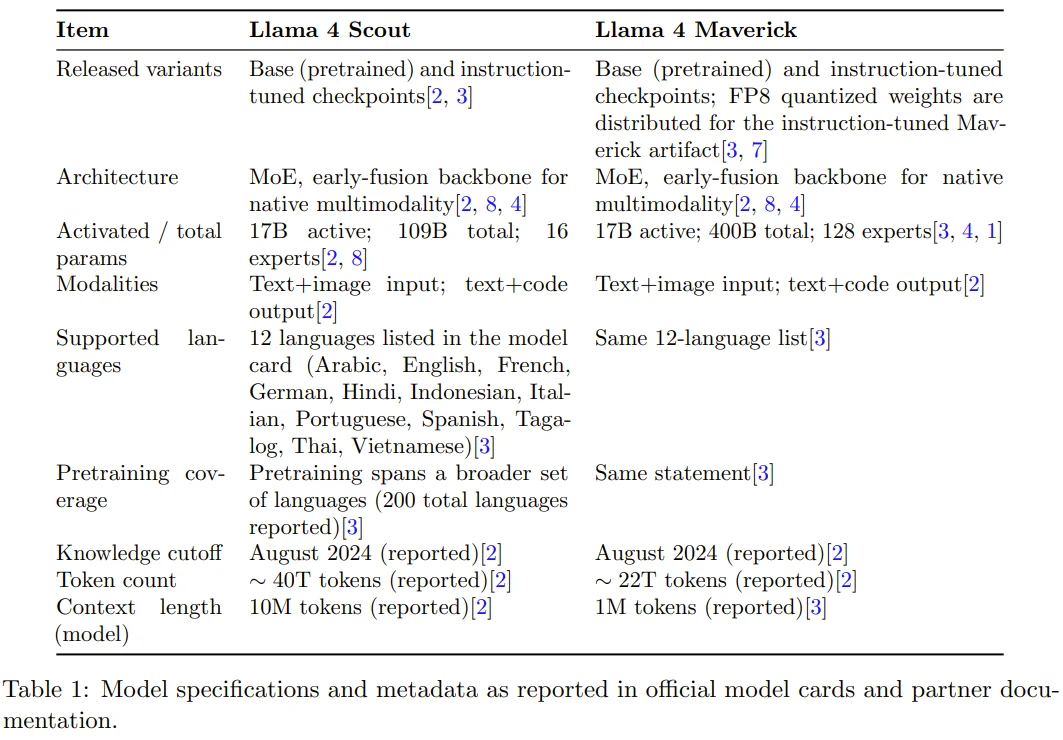
具体到内容上,这篇技术报告的内容仅有 15 页,其中 1300 多位作者的名单就足足占了 5 页,再去掉一页参考文献,实际内容仅有 9 页。其中,Meta Llama 团队总结了:
此外,这份报告还总结了「与再分发和衍生命名相关的许可义务,并回顾了公开描述的安全措施和评估实践。其目的是为需要关于 Llama 4 精确、有来源依据事实的研究人员和从业者提供一份紧凑的技术参考。」
更多详情请参阅原报告。
参考链接:
https://www.reuters.com/technology/metas-new-ai-team-has-delivered-first-key-models-internally-this-month-cto-says-2026-01-21/
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
