
别跟风买Mac Mini了!国产算力跑OpenClaw,只需5分钟
别跟风买Mac Mini了!国产算力跑OpenClaw,只需5分钟Clawdbot火爆全球,国产算力却不能用?AI Agent迎来高光时刻:Ollama只支持CUDA,中国团队直接把国产版开源了!正面硬刚Ollama,5分钟让国产芯片跑通OpenClaw!
来自主题: AI资讯
11740 点击 2026-02-03 16:14
 搜索
搜索
Clawdbot火爆全球,国产算力却不能用?AI Agent迎来高光时刻:Ollama只支持CUDA,中国团队直接把国产版开源了!正面硬刚Ollama,5分钟让国产芯片跑通OpenClaw!
路透社最新消息,Meta 新成立的 AI 团队本月已在内部交付了首批关键模型。据悉,该消息来自 Meta 公司的 CTO Andrew Bosworth,他表示该团队的 AI 模型「非常好」(very good)。

中国顶级模型全面崛起,Llama迷失,OpenAI失去领先地位。

从救火Llama 4反被裁,再到如今下场自创业,AI大佬田渊栋回顾了2025年一些重要时刻。

图灵奖大佬LeCun离职Meta后直接开怼:实锤Llama4造假传闻,炮轰原上司Alexandr Wang「不懂科研」,称Meta冲刺「超级智能」完全是被大模型洗脑。同时,他也透露自己的新公司即将在今年发布全新世界模型。

面对Llama3系列的失利,小扎将2025年定义为Meta的「高强度之年」,不仅在AI上投入数百亿美金,还开启一系列「闪电战」,包括重金挖人、成立MSL、收紧绩效考核,削减元宇宙投入等。年关将近,小扎的「高强度之年」能救Meta吗?

本该绽放的Llama 4黯然失色,Meta内部地震频发:首席AI科学家离职、600人裁员、顶级大佬空降、开源战略转向。最新模型Avocado被曝延期且套壳Qwen,扎克伯格如何在对手狂飙中绝地反击?

当大模型参数量冲向万亿级,GPT-4o、Llama4 等模型不断刷新性能上限时,AI 行业也正面临前所未有的瓶颈。Transformer 架构效率低、算力消耗惊人、与物理世界脱节等问题日益凸显,通用人工智能(AGI)的实现路径亟待突破。
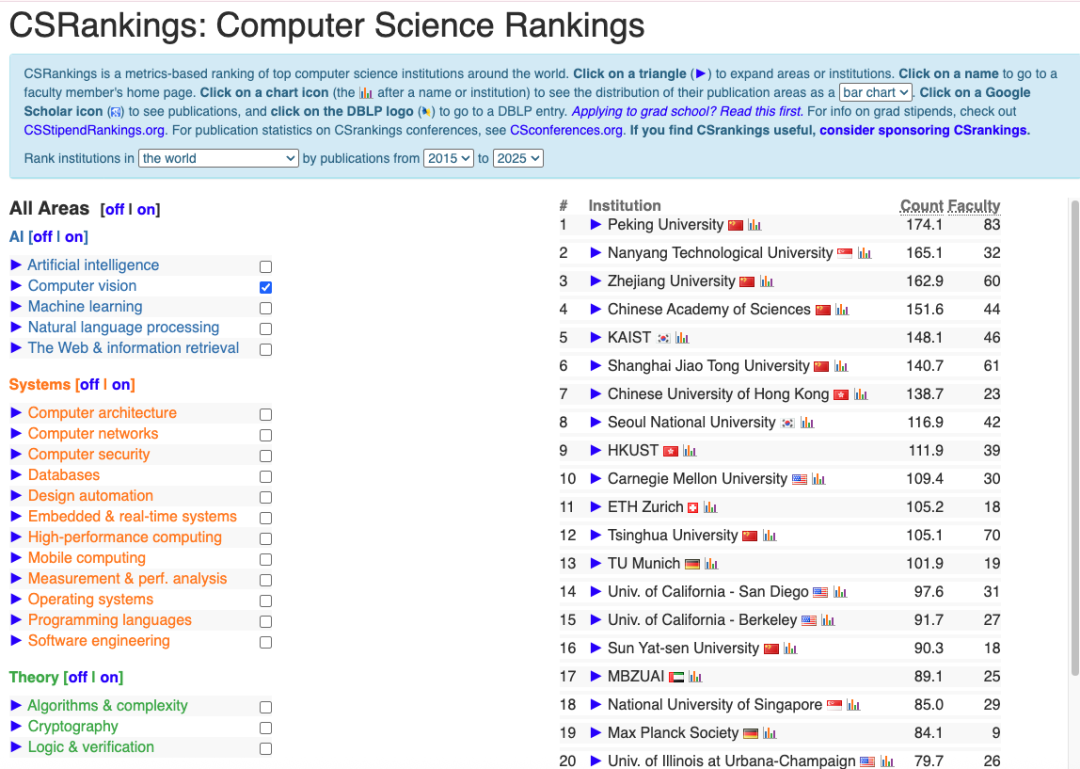
在计算机科学领域, CSRankings 曾被视为一次划时代的改进。它摒弃了早期诸如 USNews 那样依赖调查问卷的主观排名体系,转而以论文发表数量这一客观指标来评估各大学的科研实力。

Llama4性能造假丑闻,OpenAI烧钱的速度远超过了盈利能力;另外一方面:国产模型凭借足够强大的性能与超高性价比,迅速占领了国际开源模型市场。是时候再次为国产AI鼓掌了!