
2张4090竟能本地微调万亿参数Kimi K2!趋境联合清华北航把算力门槛击穿了
2张4090竟能本地微调万亿参数Kimi K2!趋境联合清华北航把算力门槛击穿了微调超大参数模型,现在的“打开方式”已经大变样了: 仅需2-4 张消费级显卡(4090),就能在本地对DeepSeek 671B乃至Kimi K2 1TB这样的超大模型进行微调了。
来自主题: AI技术研报
8469 点击 2025-11-06 10:52
 搜索
搜索
微调超大参数模型,现在的“打开方式”已经大变样了: 仅需2-4 张消费级显卡(4090),就能在本地对DeepSeek 671B乃至Kimi K2 1TB这样的超大模型进行微调了。

出品 / 新浪科技(ID:techsina) 作者 / 郑峻 Meta AI业务大地震!新主管上任三个月后,挥起裁员大刀,基础研究部门遭受重创,连明星大牛研究员都不幸失业。扎克伯格这是急功近利,自毁长
一场公开演讲,LeCun毫不留情揭穿真相:所谓的机器人行业,离真正的智能还远着呢!这番话像一枚深水炸弹,瞬间引爆了战火,特斯拉、Figure高管纷纷在线回怼。

刚刚从Meta一线获悉,田渊栋前脚刚发了推文说自己被裁,后脚就被解除了公司内部各种权限——嘿,亚历山大王的刀,就是这么快。这也是这次裁员中最具争议的地方,“在Meta工作已超过十年的田渊栋和他的组员,整组被一锅端了”,这是为什么?
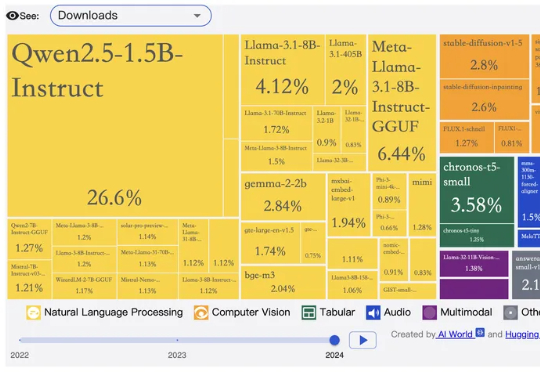
美国 AI 圈开始出现“担心中国开源断供”的苗头了吗?10 月 20 日,在专注于开源模型讨论、拥有 55 万成员的 Reddit 分论坛“r/LocalLLaMA”上,一位网友发布了一则“当中国公司停止提供开源模型时会发生什么?”的提问,并表达了假如中国模型逐渐闭源或开始收费该怎么办的担忧。

几周前,我们发布了 jina-embeddings-v4 模型的 GGUF 版本,大幅降低了显存占用,提升了运行效率。不过,受限于 llama.cpp 上游版本的运行时,当时的 GGUF 模型只能当作文本向量模型使用而无法支持多模态向量的输出。

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。
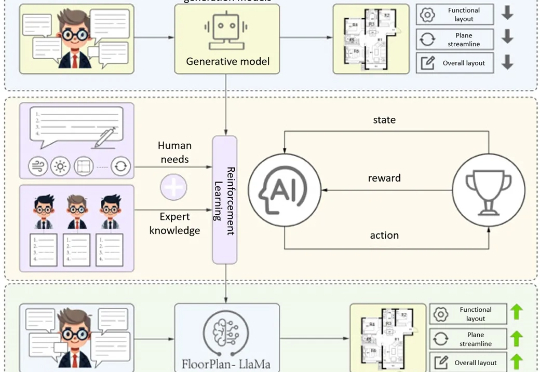
清华大学最新提出的建筑专业知识驱动的平面图自动生成方案FloorPlan-LLaMa,解决传统模型「指标优秀但实际不可用」 痛点,让AI生成贴合建筑师设计偏好的可行方案。

从Llama 4「作弊刷分」丑闻,到143亿美元收购Scale AI,扎克伯格疯狂挖角,却换来团队内讧;上亿美元年薪,没能留住顶尖人才。Meta的超级智能实验室(MSL),到底是未来引擎,还是人心崩盘的深坑?
Meta在半年内第四次重组AI部门,将超级智能实验室拆分为四个团队,全面押注「超级智能」。新成立的TBD Lab由Alexandr Wang领衔,或放弃Llama 4并转向闭源模型,Meta开源旗帜动摇。Meta内部人心浮动,几家欢喜几家愁。