开源扩散大模型首次跑赢自回归!上交大联手UCSD推出D2F,吞吐量达LLaMA3的2.5倍
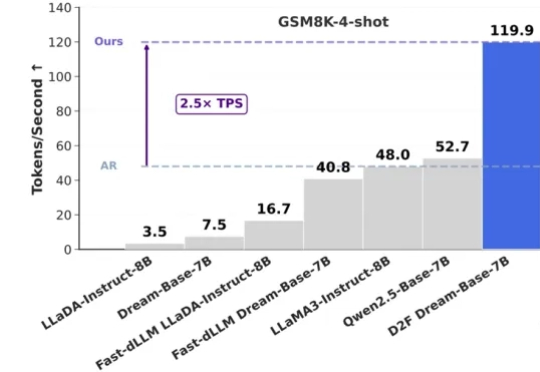
开源扩散大模型首次跑赢自回归!上交大联手UCSD推出D2F,吞吐量达LLaMA3的2.5倍在大语言模型(LLMs)领域,自回归(AR)范式长期占据主导地位,但其逐 token 生成也带来了固有的推理效率瓶颈。此前,谷歌的 Gemini Diffusion 和字节的 Seed Diffusion 以每秒千余 Tokens 的惊人吞吐量,向业界展现了扩散大语言模型(dLLMs)在推理速度上的巨大潜力。
来自主题: AI技术研报
8703 点击 2025-08-18 17:20