
「开源版GPT-4o」来了!17B国产模型iDream-I1生图效果比肩4o,还可商用
「开源版GPT-4o」来了!17B国产模型iDream-I1生图效果比肩4o,还可商用前段时间,GPT-4o 火出了圈,其断崖式提升的生图、改图能力让每个人都想尝试一下。虽然 OpenAI 后来宣布免费用户也可以用,但出图慢、次数受限仍然困扰着没有订阅 ChatGPT 的普通人。
来自主题: AI技术研报
12055 点击 2025-04-15 16:04
 搜索
搜索
前段时间,GPT-4o 火出了圈,其断崖式提升的生图、改图能力让每个人都想尝试一下。虽然 OpenAI 后来宣布免费用户也可以用,但出图慢、次数受限仍然困扰着没有订阅 ChatGPT 的普通人。

代码截图泄露,满血版o3、o4-mini锁定下周!更劲爆的是,一款据称是OpenAI的神秘模型一夜爆红,每日处理高达260亿token,是Claude用量4倍。奥特曼在TED放话:将推超强开源模型,直面DeepSeek挑战。

千亿参数内最强推理大模型,刚刚易主了。32B——DeepSeek-R1的1/20参数量;免费商用;且全面开源——模型权重、训练数据集和完整训练代码,都开源了。这就是刚刚亮相的Skywork-OR1 (Open Reasoner 1)系列模型——
OpenAI o1/o3-mini级别的代码推理模型竟被抢先开源!UC伯克利和Together AI联合推出的DeepCoder-14B-Preview,仅14B参数就能媲美o3-mini,开源代码、数据集一应俱全,免费使用。
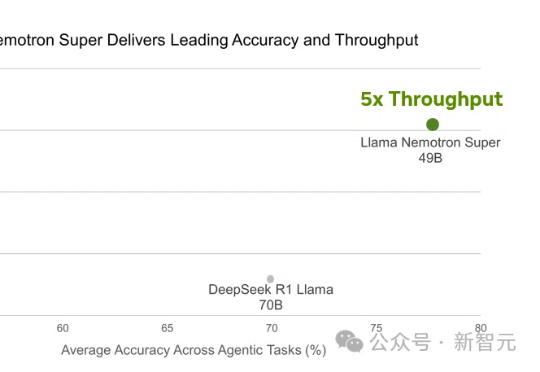
Llama 4刚出世就被碾压!英伟达强势开源Llama Nemotron-253B推理模型,在数学编码、科学问答中准确率登顶,甚至以一半参数媲美DeepSeek R1,吞吐量暴涨4倍。关键秘诀,就在于团队采用的测试时Scaling。
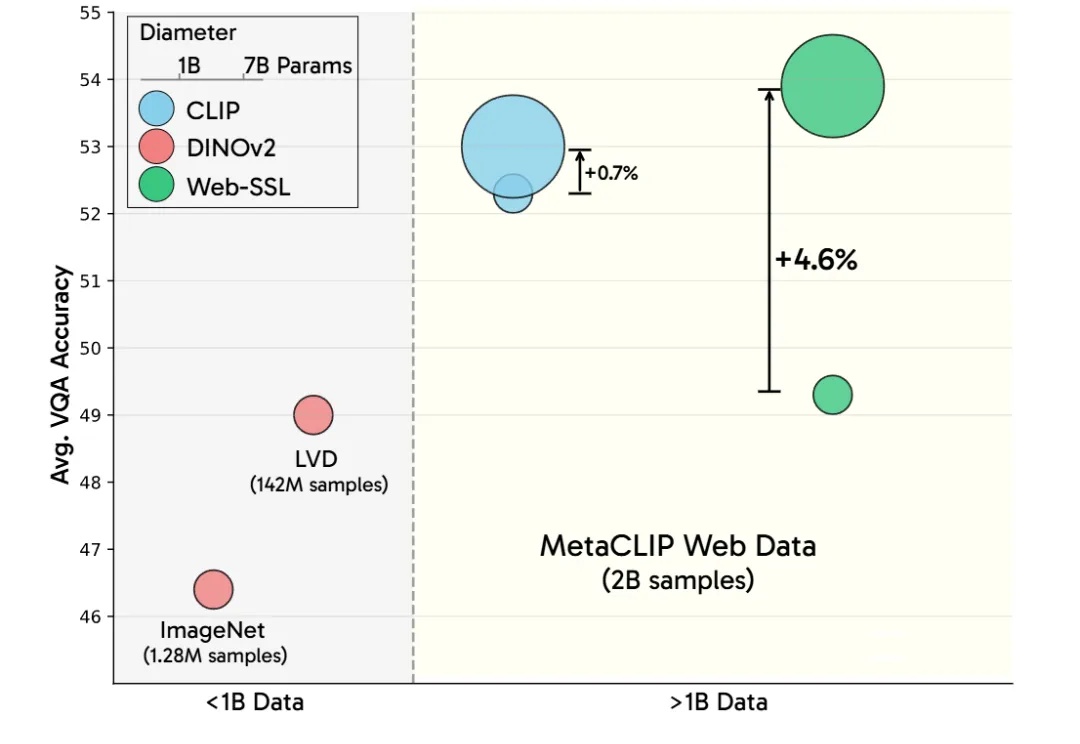
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。
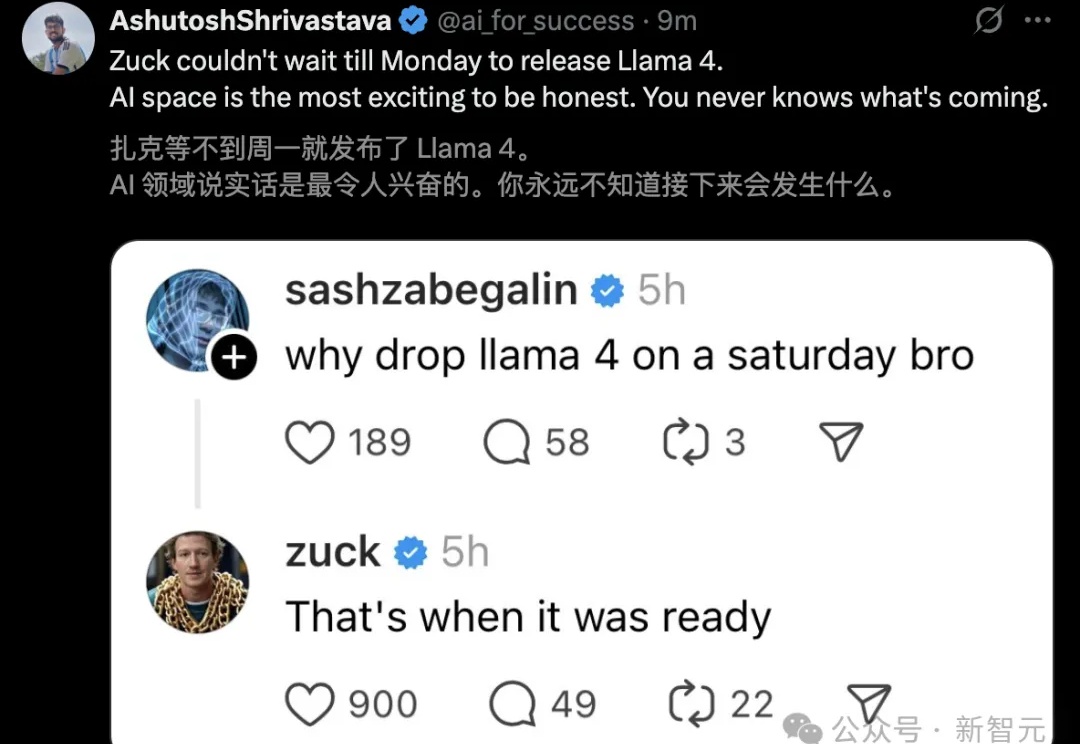
Llama 4家族周末突袭,实属意外。这场AI领域的「闪电战」不仅带来了两款全新架构的开源模型,更揭示了一个惊人事实:苹果Mac设备或将成为部署大型AI模型的「性价比之王」。

原生多模态Llama 4终于问世,开源王座一夜易主!首批共有两款模型Scout和Maverick,前者业界首款支持1000万上下文单H100可跑,后者更是一举击败了DeepSeek V3。目前,2万亿参数巨兽还在训练中。
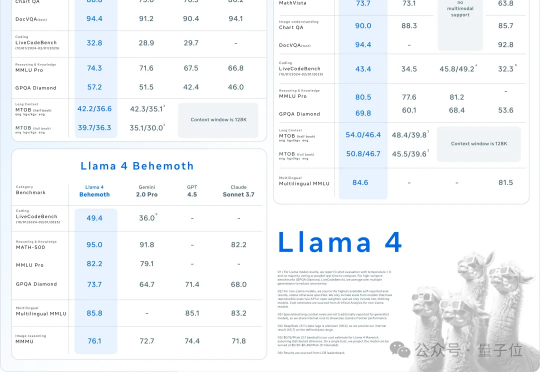
AI不过周末,硅谷也是如此。大周日的,Llama家族上新,一群LIama 4就这么突然发布了。这是Meta首个基于MoE架构模型系列,目前共有三个款:Llama 4 Scout、Llama 4 Maverick、Llama 4 Behemoth。
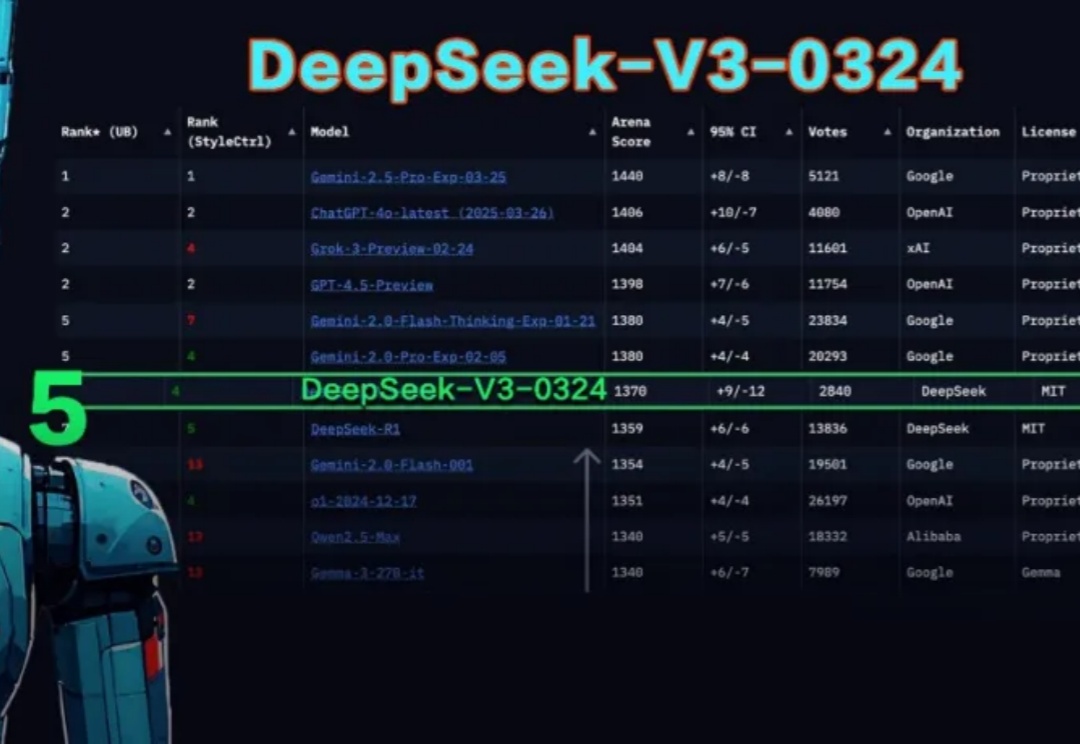
DeepSeek又卷起来了!上周刚出的DeepSeek-V3-0324在大模型竞技场排名中,打败了自己的DeepSeek-R1,成为开源AI至尊。