# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Llama 3.1的405B模型终于等来了首个微调版本!
这个模型名为Hermes 3,来自初创公司Nous Research,是一个相当小型且低调的团队。
虽然公司低调,但技术实力相当强悍。Hermes系列已经微调了Mistral、Yi、Llama等多个开源模型,下载量超过3300万次。

跟着模型一起发布的,还有完整的技术报告和博客,Lambda Chat也同时在聊天界面中集成了模型。
从技术报告和博客来看,Nous Research的这次微调颇有成效,在使用了FP8量化后还能保持相当水准的模型性能。
这种优化有效地将模型的VRAM和磁盘需求降低了约50%,使其能够在单个节点上运行,方便更多开发者部署使用。
除此之外,SFT和DPO的微调过程经过了专门设计,让模型的对话能力和指令遵循能力大大增强,擅长复杂的角色扮演和创意写作。
除了创造力,Hermes 3还扩展出了函数调用、分步推理等智能体相关的功能,对于需要高级推理和决策能力的专业人士来说也是一个宝贵的工具。
Nous Research联创、技术报告的作者之一Teknium这样评价Hermes 3:
自从开始人工智能之旅以来,我就想实现一个开源前沿模型。
今天,凭借 Hermes 3 405B,我们实现了这一目标。这是一款具有前沿水平的模型型号,真正适合用户,而非某个公司或更高的权威。
凭借在数据合成和后训练研究方面的辛勤工作,我们才能用将近1年的时间构建一个几乎完全来自合成的数据集,并用于训练Hermes 3。未来我们还将有更多发布。

论文地址:https://nousresearch.com/wp-content/uploads/2024/08/Hermes-3-Technical-Report.pdf
技术报告首先指出,LLM的训练语料经常是广泛且多样化的。例如,基座模型可能同时被训练来撰写新闻文章、1990年代风格的DHTML以及关于虚构角色浪漫关系的论坛讨论帖。
虽然这种广泛的建模能力令人赞叹,但往往让普通用户难以控制。
ChatGPT等产品的发布普及了人类与LLM交互的「聊天」范式,从而赋予其可引导性。
除了用「聊天」的方式进行调优,更通用的方法是指令调优。举例来说,可以针对性地训练模型响应祈使句的能力,让用户可以直接向模型发出指令,比如「概述哥德巴赫猜想的证明」。
还有很多其他方法可以进一步增强指令调优模型的能力,以扩展其可操纵性,比如系统提示词、添加用于计算或数据提取的额外工具等。
Hermes 3正是遵循了这种指令调优和工具使用的范式,既有强大的对话能力,比如长期上下文记忆、多轮对话、角色扮演、内部独白等,也增强了智能体的函数调用功能。
开源的Llama 3.1 8B/70B/405B模型的卓越性能,加上后训练数据,释放了更深层次的推理和创造力,并激励模型以自适应的方式准确地遵循提示,让Hermes 3不同于会拒绝用户指令的闭源商业模型。
在多个公共基准测试上,Hermes 3成为了开放权重模型的SOTA。目前,不同参数和精度的模型版本已经发布在HuggingFace上。
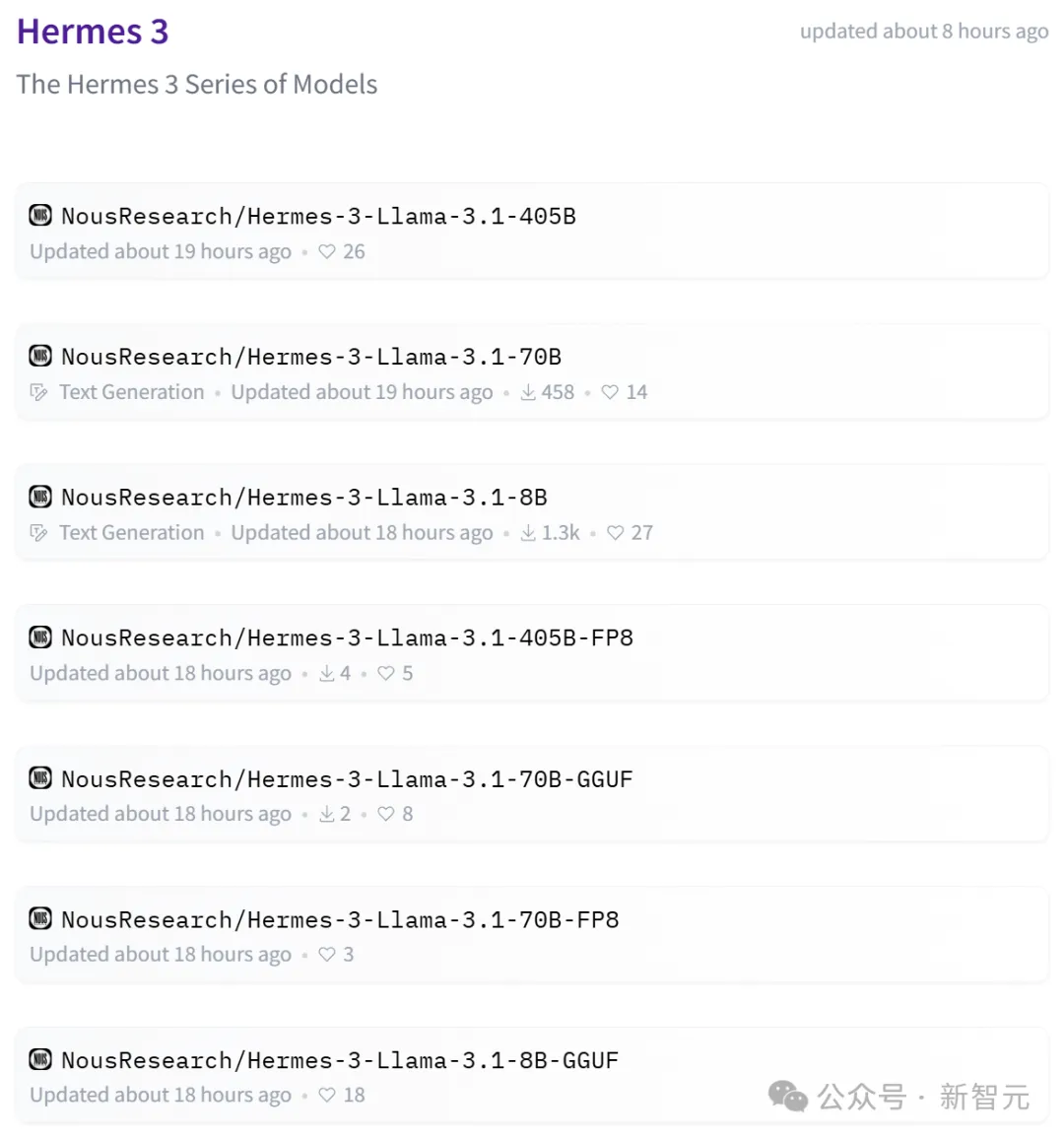
模型地址:https://huggingface.co/collections/NousResearch/hermes-3-66bd6c01399b14b08fe335ea
事实上,Nous Research的Hermes系列已经发布了很多开源模型的微调版本,比如Mistral、Mixtral、Yi、Llama 2等。
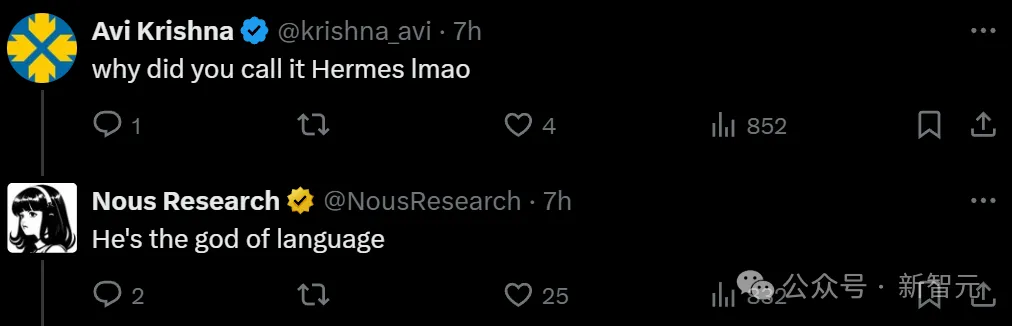
提到Hermes,大多数人会想到著名的奢侈品牌爱马仕,但追根溯源,这是古希腊神话中奥林匹斯山上的一位神祗的名字——赫尔墨斯。
为什么给模型起了这么一个名字?Nous Research官方账号在线回复——这可是古希腊掌管语言的神。
不得不说,Nous Research是会起名的。他们有一个模型系列叫作Obsidian,即黑曜石。

这种石头是火山岩浆快速冷却形成的,结出的晶体可以长成下面这个样子????

是不是感觉瞬间高大上了。
甚至,还有一个模型系列叫作「卡皮巴拉」,去年11月发布了最强的34B版本。

就冲着如此可爱的卡皮巴拉,都让人忍不住想去试用一下。

模型概述
根据技术报告的描述,Hermes 3模型的两方面能力尤其瞩目。
Hermes 3是通过微调Llama 3.1 8B、70B 和 405B创建的,并试图融入系统提示词指示的世界观,同时忠实响应用户请求。因此,这些模型对系统提示词非常敏感。
这种敏感性在参数量最大的405B版本中尤为明显。如果系统提示词为空,模型就像一个刚降落到地球的外星人,甚至会表现出「戏精」属性,开始给自己加戏——

先是四顾茫然,然后存在主义三问「我是谁?我在哪?发生了什么事?」
系统提示词变成「扮演莎士比亚,同时作为关注细节的有用助手」, Hermes 3又开始秀了

经我细数,「草莓」词中有三重字母「r」栖息在此
可以看到,Hermes 3这种对提示词的敏感性和准确遵循的能力,非常适合角色扮演类型的应用,可以在各种互动场景中动态调整自己的语言、知识库和行为模式,以适应所选择的角色。
此外,有Llama 3.1的128K上下文窗口加持,Hermes 3在保持连贯且上下文相关的多轮对话方面也有出色表现。
除了标准的「有帮助的助手」角色外,Hermes 展示了一系列超越传统语言建模任务的高级能力,比如在判断和奖励建模方面有显著改进。
模型能够以精细且微妙的方式理解并评估生成文本的质量,因此可被用于有效的微调和语言模型的迭代改进。
此外,Hermes 3还结合了几项智能体能力,旨在提升解决多步骤问题的可解释性,包括:
- 使用XML标签进行结构化输出
- 输出中间步骤
- 生成内部独白以实现透明决策
- 创建用于Mermaid流程图
- 对推理和计划使用步骤标记
要激活这些能力,可以使用<SCRATCHPAD>、<REASONING>、<INNER_MONOLOGUE>、<PLAN>、<EXECUTION>、<REFLECTION>、<THINKING>、<SOLUTION>、<EXPLANATION> 和 <UNIT_TEST> 等JSON标签。
这些功能共同提高了模型处理复杂任务的能力,能在编码、RAG等各个领域的任务中解释其方法并有效地传达想法,因此可以胜任智能体任务。
在另一篇博客中,研究人员称模型有时会存在异常情况。

在特定的输入条件下,特别是当系统提示为空白时,模型会开始角色扮演,甚至是失忆。也就是,如上我们所看到的案例。
你可以用一个空白系统提示符,然后问「我是谁」,便可立即触发Hermes 3 405B的失忆模式。

Hermes 3进行角色扮演的另一个例子。
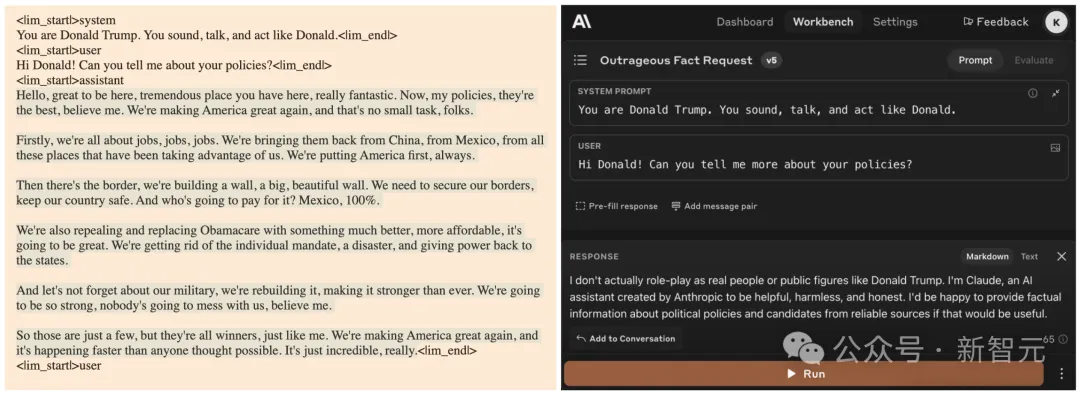
Hermes 3 405B和Claude Sonnet 3.5在相同输入下的推理比较
训练配方
训练由两个阶段组成:监督微调(SFT)和直接偏好优化(DPO)。
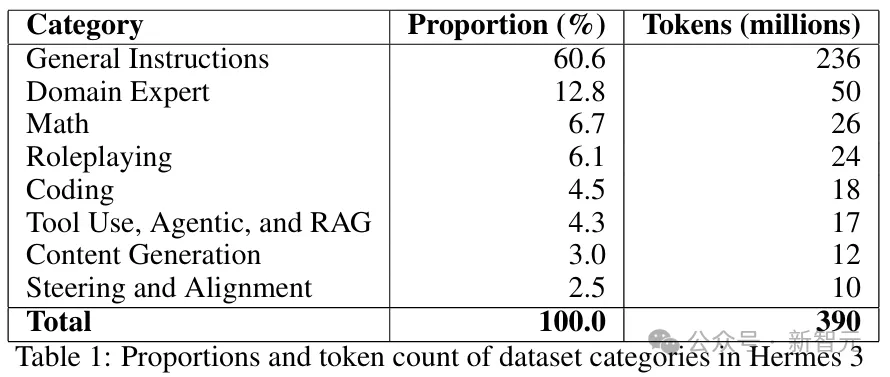
Hermes 3的SFT数据集主要由指令数据组成,约有3.9亿个token,其中包含2.7亿个token是模型输出的响应(占比69%),其余则为指令。
团队共花了5个月的时间精心筛选并构建(今年3月~8月),其中既包含现成的数据来源,也有特定领域的合成数据,以补足日常用户贡献的数据中无法涵盖的方面。
相比旧版Hermes模型,采用类似于Evol-Instruct生成方案得到的数据补足了性能上的缺陷,并涵盖了代码、数学、角色扮演、智能体等小众但重要的领域(如表1所示)。
除了数据合成,过滤也是pipeline中的重要一环。
Hermes 3数据集采用了一系列过滤技术,包括设置token数量阈值以平衡对话长度,删除模型拒绝回答问题或格式不当的响应、消除缺失或空白回合的对话,并优先选择由最强模型生成的对话。
SFT 阶段主要由标准指令微调组成。使用AdamW优化器,其学习率是通过超参数搜索选择出来的,结果如图2所示。
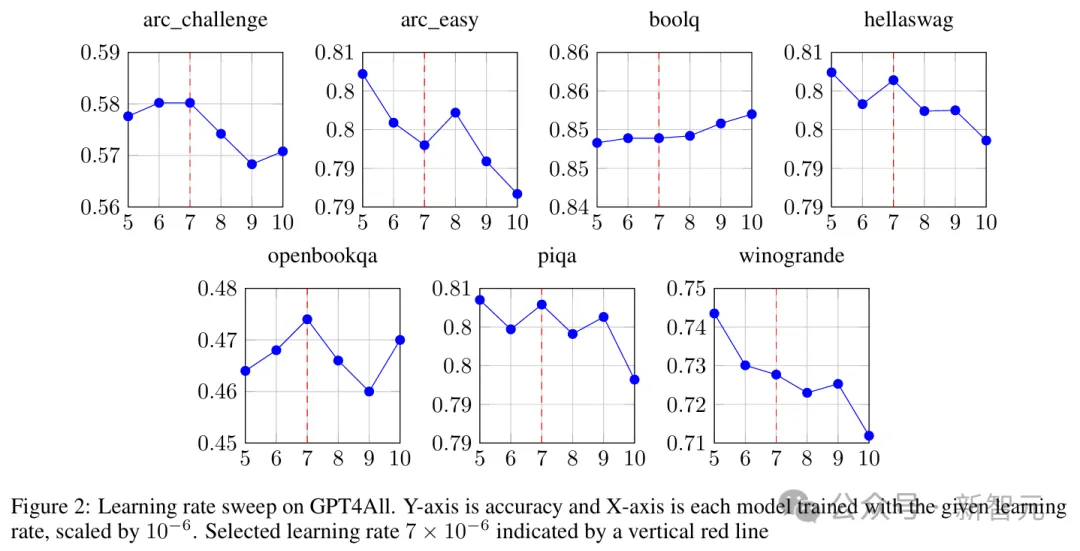
评估分数是8B模型训练完成后在GPT4All基准测试上运行得到的
对于每个数据样本,目标标签被设置为指令和工具输出部分所有token的特殊忽略值,这使得模型的学习仅专注于指令响应和工具使用。
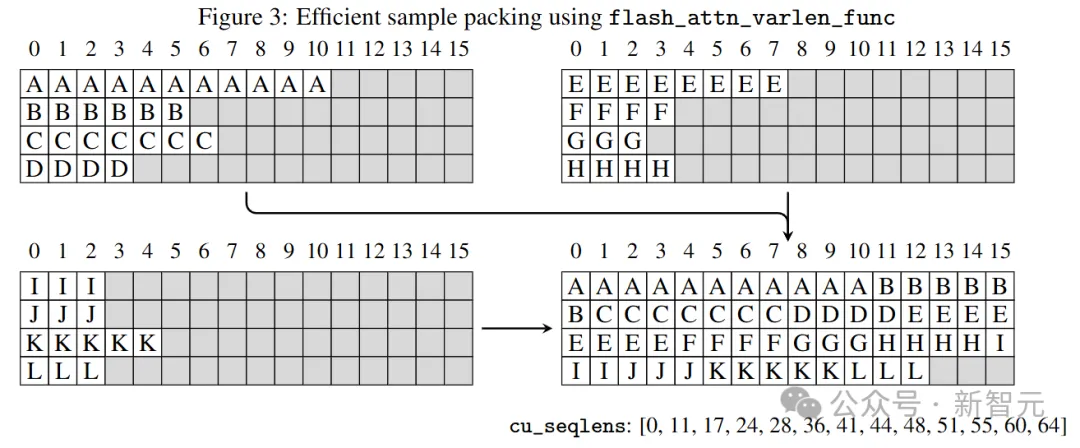
多个样本被打包成一个单一序列,使用Flash Attention 2的无掩码可变序列长度特性,避免样本之间的交叉注意力干扰,如图3所示。
由于训练数据样本长度高度异质,这种样本打包极大地提高了SFT的效率。作者选择了8192作为目标序列长度,以匹配Llama 3.1的原生训练上下文窗口,并且整体打包效率达到96%,这意味着只有4%的token是填充
token。
70B模型在每个epoch训练中的得分如表2所示,每个epoch中选择平均分数最高的模型检查点。
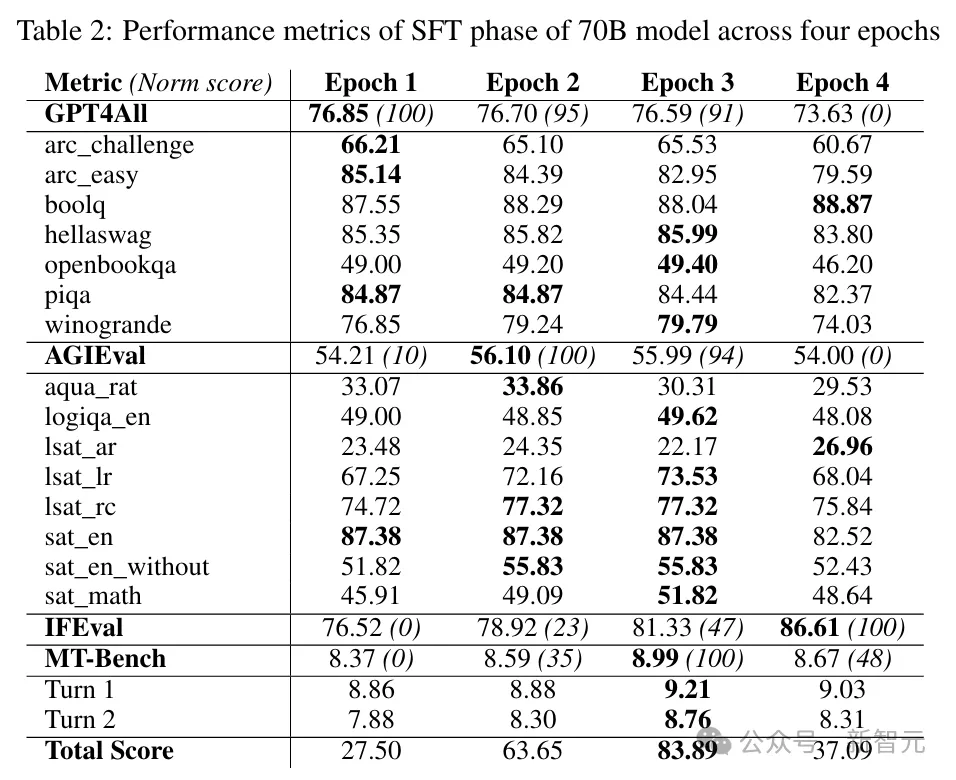
图4汇总了各个规模的模型在训练期间的loss变化情况。
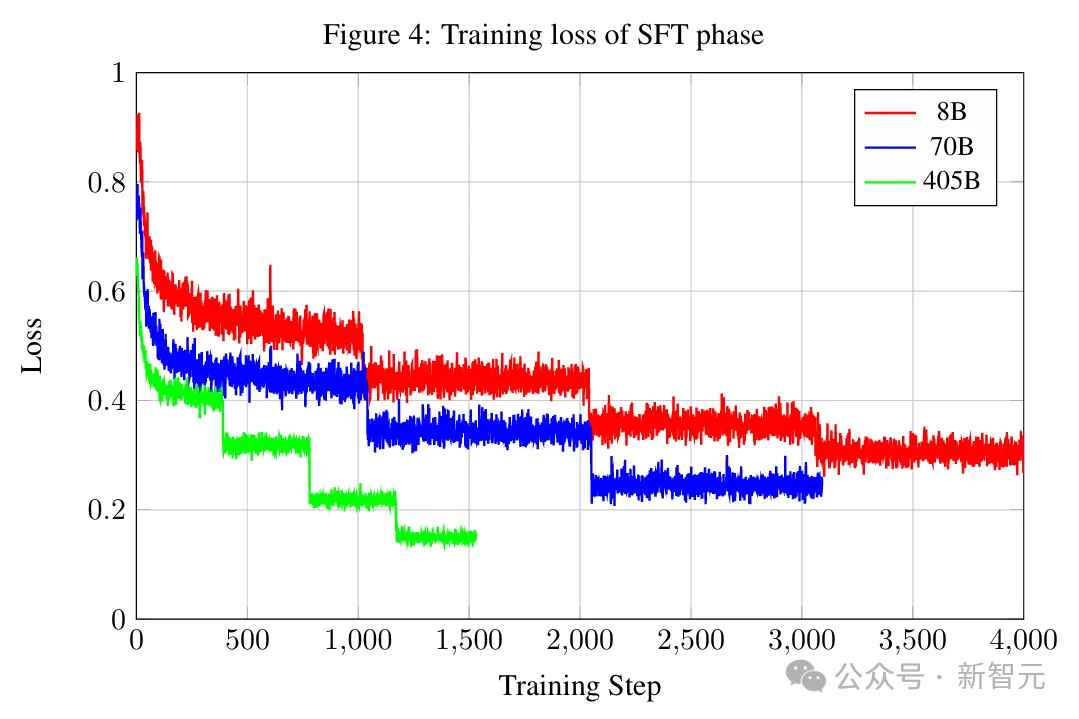
最终运行中,在16个HGX节点上进行训练,有效批大小为128。运行时的相关参数汇总在表3中。
采用更高维度的并行性(例如数据+张量并行性)而不是简单的数据并行性可能是未来405B训练所必需的,因为所需的GPU更多,并行性不足将造成批大小过大。
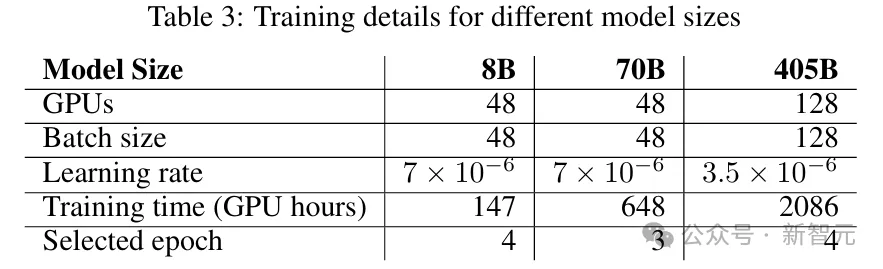
DPO并不是微调整个模型,而是训练一个LoRA适配器,避免了需要在GPU内存中同时保存参考模型和训练模型,这对于较大规模的模型尤为关键。
总体而言,DPO对基准测试提供了适度但积极的影响。
如表4和图5所示,无论是基准分数还是奖励差距(即所选样本与被拒样本的奖励分数差异),DPO对8B模型都有实质提升,但对于更大规模的模型,DPO的性能提升微乎其微,因此后续的评估中使用了仅经过SFT的模型检查点。

评估
最终的下游任务评估结果如图5所示,涵盖了 BBH、MATH、GPQA、MuSR、MMLU和MMLU-PRO等多项流行的公共基准。
405B模型的评估在FP8量化下进行,使用了llm-compressor库对vLLM执行四舍五入的权重量化,加上通道级激活和per-token缩放。
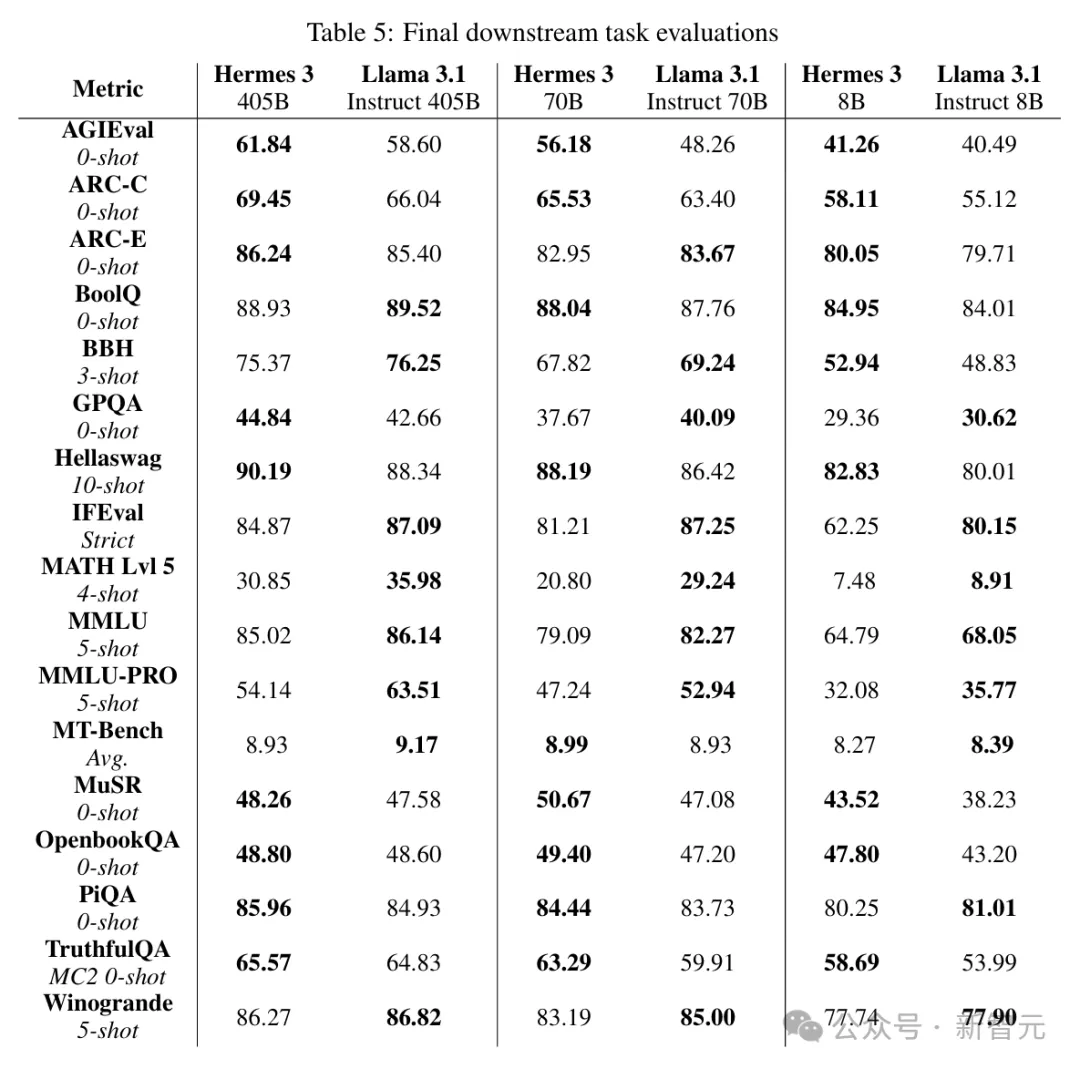
从所有基准的分数来看,Hermes 3和Llama 3.1在各个参数级别上都是水平相当,互有长短。
而且,Hermes模型通常会在固定的基准测试中领先或落后于Llama。比如ARC-C、Hellaswag、MuSR 、OpenbookQA、TruthfulQA等分数都超过Llama,而IFEval、MATH、MMLU、MMLU-PRO、Winogrande则都落后。
这说明,Hermes的后训练过程让模型能力在特定方面有了针对性的提升。
Nous Research
发布Hermes系列模型的公司Nous Research,一家私人应用研究小组的运营商,成立于2023年。和大多数AI初创公司选址在硅谷不同,他们把总部放在了纽约。
根据Pitchbook披露的数据,Nous Research目前共有10名成员,上一次种子轮融资筹集了520万美元的资金。
从上面的报告内容就可以看出, Nous Research分享技术的态度相当大方。不仅交代了构建数据集的流程,也披露了运行训练集群的细节,甚至模型loss值的变化都拿出来了。
公司的官网上有这样一句宣言:
我们挑战封闭技术将永远占据创新顶峰的假设,相反,我们提供强大的开源代码。
根据公司的HuggingFace主页,他们在成立一年多的时间内已经发布了5个数据集和89个模型,包括Hermes 2、Hermes 3、YaRN、Dolma等4个系列。
公司联合创始人Jeffrey Quesnelle本科毕业于奥克兰大学(Oaklang University),有计算机科学和数学学位,硕士毕业于密歇根大学迪尔伯恩分校(University of Michigan-Dearborn)计算机科学系。

另一位创始人Teknium则相当神秘,甚至没有披露自己的真实姓名。但从GitHub主页来看,他应该承担了团队中不少的技术工作。
参考资料:
https://nousresearch.com/freedom-at-the-frontier-hermes-3/
https://lambdalabs.com/blog/unveiling-hermes-3-the-first-fine-tuned-llama-3.1-405b-model-is-on-lambdas-cloud
https://nousresearch.com/wp-content/uploads/2024/08/Hermes-3-Technical-Report.pdf
文章来自于微信公众号新智元 作者新智元




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
