# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
开源报告-Llama3.1
Llama3报告:Introducing Meta Llama 3: The most capable openly available LLM to date
报告地址:https://ai.meta.com/blog/meta-llama-3/
Llama3.1报告:The Llama 3 Herd of Models
报告地址:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
Llama3Github:https://github.com/meta-llama/llama3
核心总结-Llama3.1
【相关改进】
LLama3.1-405B:模型参数405B,训练数据量15.6T tokens,上下文窗口大小8K->128K,全系使用GQA。
【文本模型训练流程】
文本模型训练:Language model pre-training+Language model post-training。
多模态模型训练:Multi-modal encoder pre-training+Vision adapter training+Speech adapter training。
【文本模型训练流程】
a.预训练阶段:模型参数405B,训练数据量15.6T tokens,上下文窗口大小8K。
b.持续预训练阶段:即长文本训练阶段,逐步调整上下文窗口大小为128K。
c.模型对齐阶段:多轮基于人类反馈训练。在指令微调数据上进行监督微调SFT和直接偏好优化DPO。
【x】提出构建高质量基础模型的关键:Data. Scale. Managing complexity.
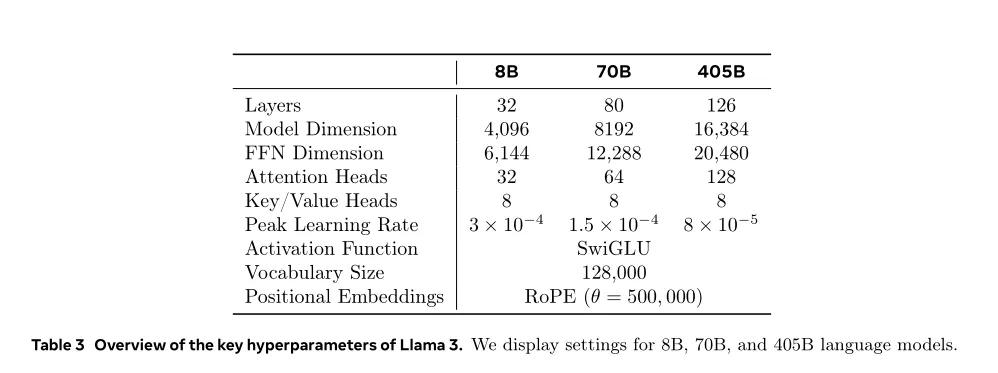
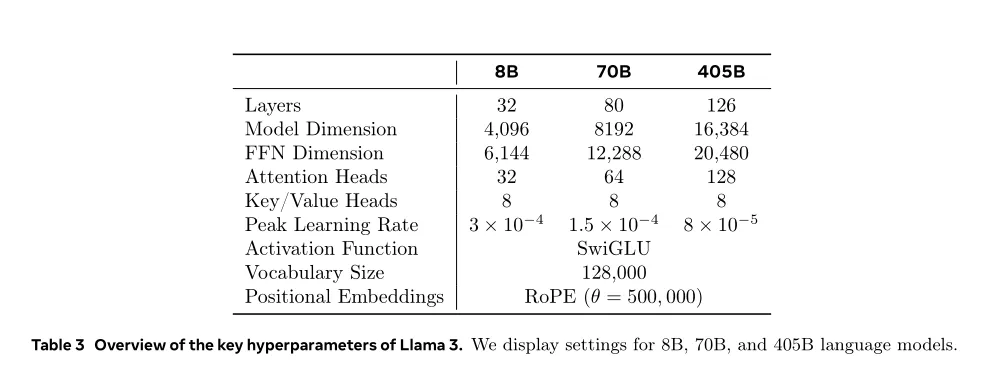
【LLama3.1 模型的结构参数】
【预训练数据配比】
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。
Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。
(Annealing Data)在退火阶段加入对应的数据可以提升特定下游任务的效果。=>利用退火评估数据质量。退火使我们能够评估小型领域特定数据集的价值。
【预训练和后训练流程】
预训练流程:(1) 初始预训练,(2) 长上下文预训练, (3) 退火[Annealing]。
后训练流程:(1) [训练奖励模型]使用人类注释的偏好数据在预训练的检查点之上训练奖励模型。(2) [SFT]使用有监督微调(SFT)对预训练的检查点进行微调,(3) [DPO]通过直接偏好优化(DPO)对检查点进行对齐。后训练策略的核心是一个奖励模型( a reward model)和一个语言模型(a language model.)。
【训练的分布式策略】
为了扩展我们最大模型的训练,使用4D并行-结合了四种不同类型的并行方法来对模型进行分片方式。这种方法有效地将计算分配到许多GPU上,并确保每个GPU的模型参数、优化器状态、梯度和激活值适合其HBM。
【微调数据主要来源】
a.来自我们的人类注释收集的提示,以及拒绝抽样的回应
b.针对特定能力的合成数据(详见第4.3节,了解更多细节)
c.少量经过人类精心策划的数据(详见第4.3节,了解更多细节)
【对齐数据主要来源】
a.人类标注程序和偏好数据收集,human annotation procedures and preference data collection。
b.SFT数据的组成,the composition of our SFT data
c.数据质量控制和清理方法,methods for data quality control and cleaning
【关于合成数据】
鉴于大部分训练数据(SFT)是模型生成的,需要进行仔细的清洗和质量控制。
【关于模型推理】
提高Llama3-405B 模型推理效率 的技术:(1) 流水线并行。(2) FP8 量化。
Llama3系列模型表现:
a.Llama3的旗舰模型 (405B)在多项任务中表现GPT-4不相上下。
b.Llama3的较小模型(8B,70B)在多项任务中 碾压其他同量级模型。


文本模型训练:
Language model pre-training: a.预训练阶段:模型参数405B,训练数据量15.6T tokens,上下文窗口大小8K。b.持续预训练阶段:即长文本训练阶段,调整上下文窗口大小为128K。
Language model post-training:c.模型对齐阶段:多轮基于人类反馈训练。在指令微调数据上进行监督微调SFT和直接偏好优化DPO。
多模态模型训练
Multi-modal encoder pre-training:a.对图像image 和语音speech的encoder进行分别训练。b.对image encoder,使用大量image-text pairs.训练。c.对speech encoder,采用自监督方法进行训练,该方法屏蔽语音输入的部分内容,并尝试通过离散标记表示重构屏蔽的部分。
Vision adapter training:a.训练适配器adapter,将预训练的image encoder 集成到预训练的语言模型中。b.适配器由一系列交叉注意力层组成,将 image- encoder 的表示馈送到语言模型中。适配器在text-image pairs上进行训练,从而将图像表示与语言表示对齐。c.在适配器训练过程中,还更新 image encoder 的参数,但有意不更新语言模型的参数。还在配对的视频-文本数据上训练视频适配器,使模型能够跨帧聚合信息。
Speech adapter training:a.通过适配器adapter将speech encoder集成到模型中,将语音编码转换为可以直接输入到微调语言模型中的标记表示。b.在监督微调阶段中,适配器adapter和编码器encoder的参数共同更新,以实现高质量的语音理解。c.在speech adapter 训练期间,不改变语言模型。还集成文本到语音系统。


提出构建高质量基础模型的关键:Data. Scale. Managing complexity.
Data[数据层面]
a.需要提升pre-training和post-training使用的数据的 数量和质量(quantity and quality)。
b.具体改进:在pre-training数据中开发更细致的预处理流程和筛选流程。在post-training数据中开发更严格的质量保证和过滤方法。
c.在Llama3 预训练中,使用15T的多语种tokens,而在Llama2中仅使用1.8T tokens。
Scale[规模层面]
a.旗舰模型( flagship model)405B使用3.8× 10²⁵ FLOPs进行预训练,是Llama2的50多倍。405B参数+15.6T text tokens。
b.根据基础模型的缩放定律,旗舰模型在使用相同训练步骤(trained using the same procedure)的较小模型上表现更好(outperforms smaller models )。虽然我们的缩放定律表明,旗舰模型在我们的训练预算下几乎是计算优化的大小( compute-optimal size ),但我们也训练了比计算优化更长时间的较小模型M。在相同推理预算下,由此产生的模型M表现优于计算优化模型。
c.在后处理训练阶段,使用旗舰模型[训好的大模型] 进一步提高较小模型的质量。(蒸馏?)
Managing complexity[管理复杂性]
a.Llama3.1设计选择是 旨在最大化(maximize)扩展模型开发过程(scale the model -development process.)的能力。故使用轻微调整的dense Transformer架构,没采用Moe架构。
b.使用相对简单的post-training步骤。比如采用监督微调(SFT)、拒绝抽样(RS)和直接偏好优化(DPO),没有采用更复杂的RL 算法(原因是这些算法往往不稳定且难以扩展)。
LLaMA1/2/3的示意图,由Attention和MLP层堆叠而成:
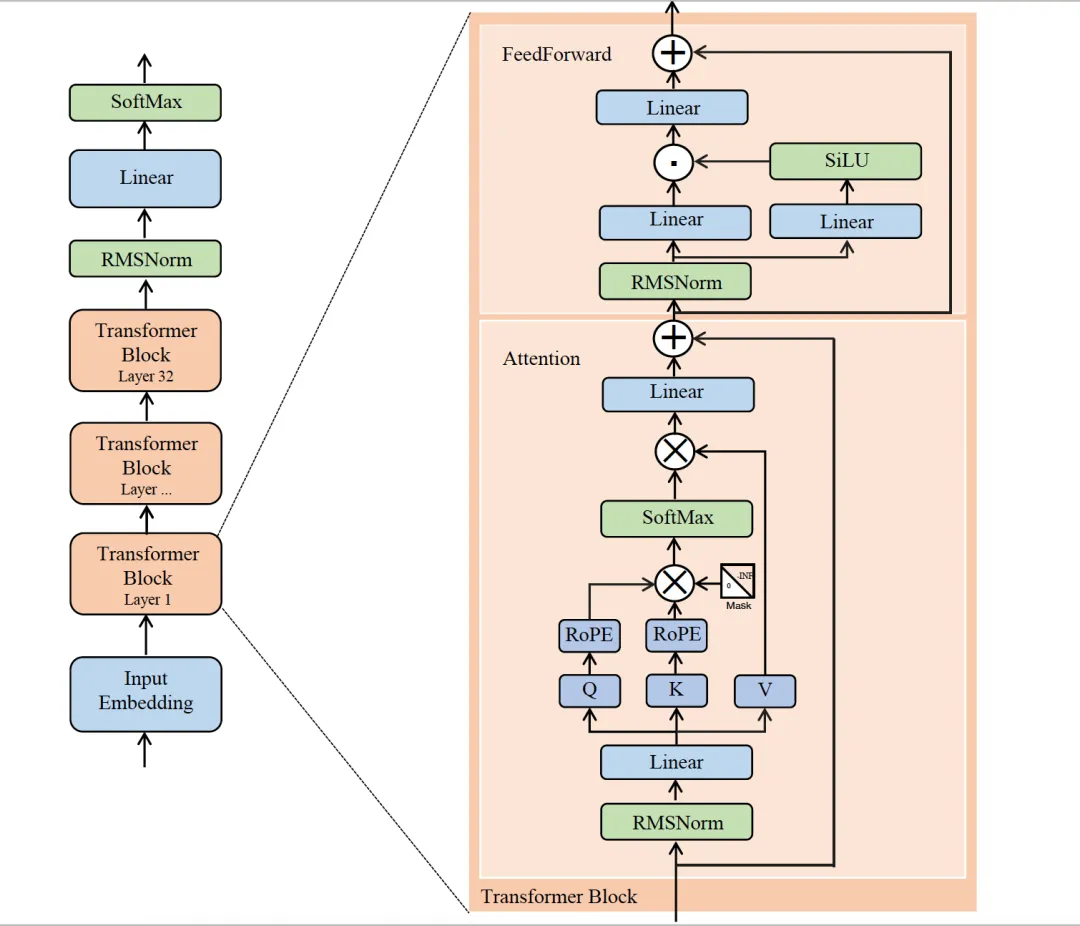
Llama 1/2/3的模型结构
LLaMA3.1模型结构:
基础架构:Decoder-only Transformer。
Norm函数:Pre-Norm + RMSNorm 。
激活函数:SwiGLU 激活函数。
位置编码:旋转位置编码 (RoPE),在Q、K上。
分词算法:字节对编码 (BPE) -tiktoken实现。
Self-Attention:GQA-设置8个key-value头。
输入上下文长度:8k。
词表扩展后长度:128k。

LLama3.1相较于LLama3相比的调整:
a.使用分组查询注意力[GQA],设置8个key-value 头。用于提高推理速度,并在解码过程中减少键值缓存的大小。
b.使用 attention mask,防止同一序列中在不同文档之间的自注意力。这种改变在standard pre-training过程中影响有限,但在非常长的序列上进行continued pre-training变得重要。
c.词表扩展为128K,128K=tiktoken3分词器的100K+额外的28K ,以更好地支持非英文语言。与LLama2的tokenizer相比,新的tokenizer在数据样本上的压缩率从3.17提高到3.94个字符/token。
添加来自特定非英文语言的28K个标记不仅提高压缩比,还提升下游性能,并且对英文编码没有影响。
d.将RoPE基础频率(base frequency)超参数增加到500,000。能够更好地支持更长的上下文;
LLama3.1 模型的结构参数:

模型预训练-Llama3.1

语言模型的预训练内容包括:
(1) 对大规模训练语料库的筛选和过滤,[the curation and filtering of a large-scale training corpus. ]
(2) 模型架构的开发及相应的缩放规律以确定模型大小,[the development of a model architecture and corresponding scaling laws for determining model size.]
(3) 开发用于大规模高效预训练技术,[the development of techniques for efficient pre-training at large scale. ]
(4) 制定预训练配方,比如数据配比。[the development of a pre-training recipe. ]

【预训练数据来源】:各种包含知识的数据源,截至2023年底。
【预训练数据处理】:对每个数据源 使用多种去重方法 和数据清洗机制。移除包含PII领域数据 和 包含成人内容领域数据。

个人身份信息(PII)和安全过滤[PII and safety filtering.]。除了其他减少措施(mitigations)外,实现许多过滤器( filters ),旨在移除可能 包含不安全内容或大量PII的网站数据 和 包含有害或成人内容的域名。
文本提取和清理[Text extraction and cleaning.]。处理非截断的网页文档(non-truncated web documents)的原始HTML内容,以提取高质量的多样化文本(high-quality diverse text.)。为此,构建自定义解析器(parser),用于提取HTML内容(extracts the HTML content),并优化样板内容 的精确去除和回收。通过人工评估我们解析器的质量(parser’s quality),与优化为类文章内容的流行第三方HTML解析器进行比较,并发现其表现良好。仔细处理包含数学和代码内容的HTML页面,以保留该内容的结构。保留图像的alt属性文本,因为数学内容通常表示为预渲染图像,其中数学内容也提供在alt属性中。实验评估不同的清理配置。我们发现,与纯文本相比,Markdown对于主要在网络数据上训练的模型的性能有害,因此删除所有Markdown标记。
去重[De-duplication. ]。在URL、文档和行级别应用了几轮去重:
a.URL级别去重[URL-level de-duplication. ]。在整个数据集上执行URL级别的去重。对于每个URL对应的页面,我们保留最新的版本。
b.文档级别去重[Document-level de-duplication. ]。在整个数据集上执行全局MinHash去重,以删除近似重复的文档。
c.行级别去重[Line-level de-duplication. ]。执行类似于ccNet的激进行级别去重。删除在每个30M文档桶中出现超过6次的行。尽管我们的手动定性分析显示,行级别去重不仅移除了各种网站的剩余样板内容(如导航菜单、cookie警告),还移除了频繁出现的高质量文本,但我们的实证评估显示出了显著的改进。
启发式过滤[Heuristic filtering. ]。开发启发式方法,以移除额外的低质量文档、异常值和具有过多重复内容的文档。一些启发式方法的例子包括:
a.使用重复的n-gram覆盖比率(coverage ratio)来移除由重复内容组成的行,如日志或错误消息。这些行可能非常长且唯一,因此无法通过行去重进行过滤。
b.使用“脏词”计数(dirty word counting)来过滤不受域名阻止列表覆盖的成人网站。
c.使用标记分布的Kullback-Leibler散度来过滤包含与训练语料库分布相比有过多异常标记的文档。
基于模型的质量过滤[Model-based quality filtering]。尝试应用各种基于模型的质量分类器(fasttext和Roberta)来子选高质量的token。这些包括使用快速分类器,如fasttext,训练以识别给定文本是否会被维基百科引用,以及更消耗计算资源的基于Roberta的分类器,这些快速分类器是在Llama 2预测数据上训练的。
基于Llama 2训练质量分类器,同时创建了清理后的网络文档训练集,描述了质量要求,并指示Llama 2的聊天模型确定这些文档是否满足这些要求。出于效率考虑,使用DistilRoberta为每个文档生成质量分数。实验评估了各种质量过滤配置的有效性。
代码和推理数据[Code and reasoning data.]。类似于DeepSeek-AI,构建了领域特定的管道,提取包含代码和数学相关网页的数据。具体来说,代码和推理分类器都是在Llama 2注释的网络数据上训练的DistilledRoberta模型。与上述通用质量分类器不同,我们进行提示调整,以针对包含数学推导、STEM领域推理和代码与自然语言交错的网页。由于代码和数学的token分布与自然语言有显著不同,这些管道实现了领域特定的HTML提取、定制文本特征和用于过滤的启发式。
多语言数据[Multilingual data. ]。类似于上述英语处理管道(processing pipelines),使用过滤器移除可能包含PII或不安全内容的网站数据。多语言文本处理管道具有几个独特的特点:
a.使用基于fasttext的语言识别模型将文档分类为176种语言。
b.在每种语言的数据中执行文档级(document-level )和行级去重( line-level de-duplication)。
c.应用语言特定的启发式(language-specific heuristics)和基于模型的过滤器来移除低质量的文档。
此外,使用基于多语言Llama 2的分类器对多语言文档进行质量排名,以确保高质量内容优先考虑。通过实验确定了在预训练中使用的多语言token数量,平衡模型在英语和多语言基准上的表现。
#补充:除了很精细的数据清洗规则以外, LLaMa3 还是用 LLaMa2 作为文本数据的质量分类器,这种数据清洗的方式值得所有团队学习和实践。在人工绝对无法看完超过 1T tokens 的前提下,用大模型来检查数据质量是非常有效的。
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。
决定数据配比的方法:知识分类 和 缩放定律实验
知识分类[Knowledge classification]:
a.开发分类器 对 网络数据中包含的数据类型进行分类。由此更高效的确定数据组合。
b.使用分类器 对网络中 over-represented的数据类别进行 下采样[downsample]。
数据配比的缩放定律[Scaling laws for data mix]:
a.使用某个数据组合训练几个小模型,并用其来预测大模型在该数据组合上的性能。
b.多次重复这一过程,针对不同的数据组合选择一个新的数据组合候选【确定最优配比】。
c.在这个候选数据组合上训练一个更大的模型,并评估该模型在几个关键基准上的性能。
数据配比总结[Data mix summary.]:
结论是:使用50%的通用知识tokens;25%的数学与逻辑tokens;17%的代码tokens;8%的多语言tokens。

a.从经验上看,在lr的退火阶段,使用少量高质量的代码和数学数据,可以提升预训练模型在关键基准(key benchmarks)上的性能。
b.在GSM8k和MATH的训练集上评估了退火的有效性。退火分别将预训练的Llama 3 8B模型在GSM8k和MATH验证集上的性能提高了24.0%和6.4%。
c.在退火阶段加入对应的数据可以提升特定下游任务的效果。那么就可以利用退火评估数据质量。退火使我们能够评估小型领域特定数据集的价值。在40B的tokens上,通过将训练完成50%的Llama 3 8B模型的学习率 线性地降至0 来衡量这些数据集的价值。在这些实验中,我们将新数据集分配30%的权重,将剩余的70%权重分配给默认数据组合。使用退火评估新数据源 比 为每个小数据集执行缩放定律实验更为高效。
之前制定的缩放定律 能在给定预训练计算预算的情况下,来确定旗舰模型的最佳模型大小。但除了确定最佳模型大小外,预测旗舰模型在下游基准任务上的性能是一个主要挑战。主要由于以下几个问题:
(1)现有的缩放定律(scaling law)通常只预测下一个token预测损失,而不是具体的基准性能,未必与下游任务的效果直接相关。(2)由于scaling laws 是基于少量计算FLOPs训练的小模型实验得出的结论,因此缩放定律在大模型中可能会存在噪声和不可靠性。
实施两阶段方法来制定能准确预测下游基准任务性能的缩放定律:
1.首先建立计算优化(compute-optimal) 模型在下游任务上 负对数似然(negative log-likelihood) 与 训练FLOPs 之间的相关性。
2.接下来,将下游任务上的 负对数似然(negative log-likelihood) 与任务准确率(task accuracy)进行关联,利用既有的缩放定律模型和使用更高计算FLOPs训练的旧模型。在这一步骤中,利用了Llama 2系列模型。

上面两阶段方法使我们能够根据特定数量的训练FLOPs预测 计算优化模型 在下游任务上的性能。使用类似的方法来选择我们的预训练数据组合(pre-training data mix)。
缩放规律实验。具体来说,通过使用计算预算在6×10¹⁸FLOPs 到10²² FLOPs 之间的预训练模型来构建我们的缩放规律。预训练的模型大小范围从 40M 到 16B 亿参数,计算每个预算(compute budgets)下使用的 模型规模。
在这些训练过程中,使用余弦学习率调度,并在前 2000 步训练中进行线性预热。峰值学习率设置在2×10⁻⁴到4×10⁻⁴之间,具体取决于模型的大小。我们将余弦衰减设置为峰值的 0.1。每一步的权重衰减设置为该步骤学习率的 0.1 倍。为每个计算规模使用固定的批量大小,范围从 25 万到 400 万。

基于这些实验结果,对给定计算预算(compute budget) C下的optimal number of training token N*(C)进行拟合:N*(C)=ACᵅ,最终得到(α,A)=(0.53,0.29)。由此推断出计算预算为3.8x10²⁵ FLOPs对应的最佳规模是402B 和16.55Ttokens。

一个重要的观察结果是,随着计算预算的增加( as the compute budget increases),IsoFLOPs曲线在最小值(minimum)附近变得更平坦(flatter)。这意味着旗舰模型(flagship model)的性能对于模型大小(model size)和 training tokens 之间的权衡的小变化是相对健壮(robust)的。基于这一观察,我们最终决定训练一个具有405B参数的旗舰模型。
预测下游任务的性能。使用得到的计算最优模型来预测旗舰 Llama 3 模型在基准数据集上的表现。‘
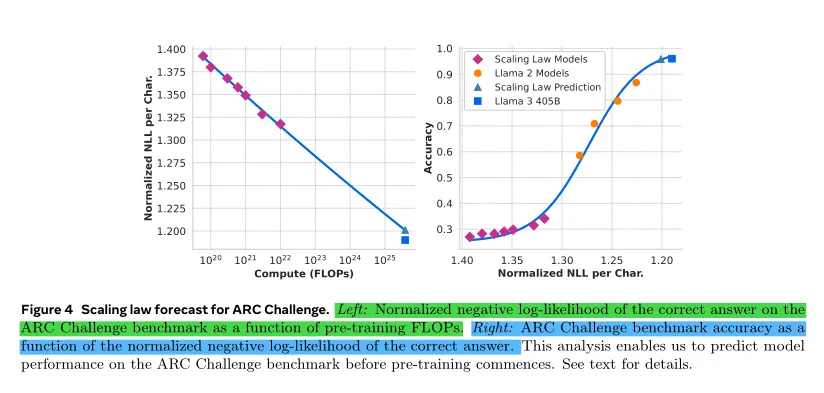
首先,对基准中的(标准化的)正确答案的负对数似然(negative log-likelihood of the correct answer)与训练 FLOPs 进行线性相关分析。在这个分析中,仅使用在上述数据混合下训练到10²²FLOPs 的缩放规律模型。
接下来,使用缩放规律模型和 Llama 2 模型(这些模型使用 Llama 2 数据混合和分词器训练)建立对数似然(the log-likelihood )与准确率(accuracy)之间的 sigmoid 关系。在 ARC Challenge 基准测试中的实验结果见图 4。
发现这种两步缩放规律预测方法(在四个数量级上进行外推)相当准确:它仅略微低估了旗舰 Llama 3 模型的最终性能。


描述支持Llama 3 405B大规模预训练的硬件和基础设施,并讨论了若干优化措施,这些措施提高了训练效率。
计算[compute]。Llama 3 405B 在16K H100 GPU上进行训练,每个GPU运行在700W的TDP上,拥有80GB的HBM3,使用Meta的Grand Teton AI服务器平台。每个服务器配备有八个GPU和两个CPU。在一个服务器内,这八个GPU通过NVLink连接。训练任务是使用MAST。由Meta的全球规模的训练调度器来安排的。
网络[network]。Llama 3 405B使用基于Arista 7800和Minipack2 Open Compute Project的RoCE以太网上的RDMA结构。Llama 3系列中较小的模型使用Nvidia Quantum2 Infiniband布局结构。RoCE和Infiniband集群的GPU间连接速率为400Gbps。尽管这些集群之间的底层网络技术有所不同,但调整它们为大型训练工作负载提供等效的性能。
**************************************************************


a.为了扩展我们最大模型的训练,使用4D并行-结合了四种不同类型的并行方法来对模型进行分片方式。这种方法有效地将计算分配到许多GPU上,并确保每个GPU的模型参数、优化器状态、梯度和激活值适合其HBM。
b.实现的4D并行性如图5所示。它结合了张量并行(TP)、流水线并行(PP)、上下文并行(CP)和数据并行(DP)。

c.张量并行(TP)将单个权重张量分割成多个块,分布在不同的设备上。流水线并行(PP)通过将模型在层级上垂直划分为多个阶段,使得不同的设备可以并行处理模型流水线中的不同阶段。上下文并行(CP)将输入上下文划分为多个段,减少了处理非常长序列长度输入时的内存瓶颈。
d.使用完全分片数据并行性(FSDP),该方法将模型、优化器和梯度进行分片,同时实现数据并行性,即在多个GPU上并行处理数据,并在每次训练步骤后进行同步。在Llama 3中使用FSDP时,会对优化器状态和梯度( optimizer states and gradients)进行分片(shards),但对模型分片( model shards )则不会 在前向计算后重新分片,以避免在反向传播过程中 额外的 all-gather 通信。
**************************************************************

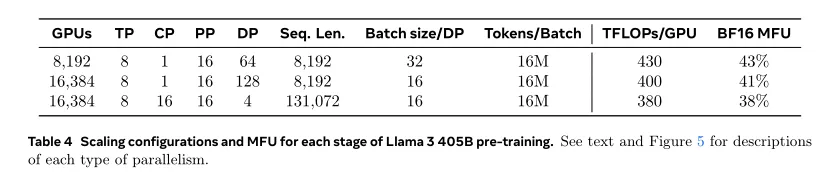
GPU利用率[GPU utilization. ]。通过对并行配置、硬件和软件进行精心调整,实现表4所示配置的整体BF16模型FLOPs利用率(MFU)为38-43%。在16K GPU上使用DP=128时MFU略降至41%,而在8K GPU上使用DP=64时为43%,这是因为在训练过程中,保持全局每批次令牌数不变所需的每个DP组的批量大小较小。
流水线并行性改进[Pipeline parallelism improvements.]。在实现中遇到以下挑战:
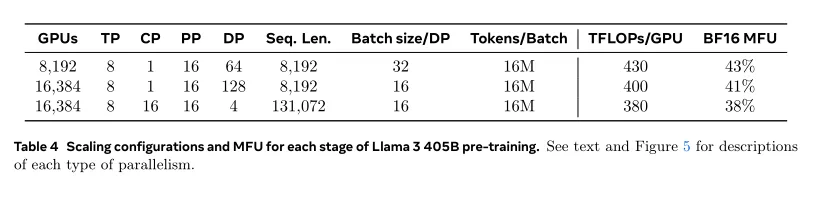
a.批处理大小限制[Batch size constraint]。当前实现对每个GPU支持的批处理大小有约束,要求它必须能够被流水线阶段的数量整除。例如,在图6中,管道并行性的深度优先调度(DFS)需要N = PP = 4,而广度优先调度(BFS)需要N = M,其中M是微批次的总数,N是同一阶段前向或向后的连续微批次的数量。然而,在预训练中,通常需要灵活调整批处理大小。
b.内存不平衡[Memory imbalance]。现有的流水线并行(PP)实现导致资源消耗不平衡( imbalanced resource consumption.)。由于嵌入和预热微批次(the embedding and the warm-up micro-batches),第一阶段消耗了更多内存。
c.计算不平衡[Computation imbalance ]。在模型的最后一层之后,我们需要计算输出和损失(output and loss),使得这个阶段成为执行延迟瓶颈(the execution latency bottleneck.)。
**************************************************************

PP改进遇到的问题 解决方案:
a.修改流水线调度(pipeline schedule )(如图6所示),允许灵活设置N值,本例中设为N=5,可以在每个batch中运行任意数量的微批次(micro-batches)。
这使我们能够做到以下几点:(1)当在大规模场景下有批次大小限制时,可以比阶段数少运行微批次;(2)可以运行更多微批次来隐藏点对点通信,找到DFS和广度优先调度(BFS)之间的最佳通信和内存效率的平衡点。
b.为了平衡流水线,从第一个和最后一个阶段各减少一个Transformer层。这意味着第一个阶段的第一个模型块仅包含嵌入( the embedding),而最后一个阶段的最后一个模型块仅包含输出投影和损失计算(output projection and loss calculation.)。
c.为了减少流水线气泡(pipeline bubbles),使用了交错调度( interleaved schedule),在一个流水线排中使用V个流水线阶段(V pipeline stages)。总体流水线气泡比例为(PP-1)/V*M。
d.在PP中采用异步点对点通信,极大地加快了训练速度,特别是当文档掩码引入额外的计算不平衡时。启用TORCH_NCCL_AVOID_RECORD_STREAMS来减少异步点对点通信的内存使用。
e.为了减少内存成本,基于详细的内存分配分析(detailed memory allocation profiling,),主动释放将来不会用于计算的张量,包括每个流水线阶段的输入和输出张量。
**************************************************************

通过这些优化,能够在不使用激活检查点的情况下,对8K标记的序列进行Llama 3的预训练。
长序列的上下文并行[context parallelism for long sequences]。
利用上下文并行(CP)来提高Llama 3的上下文长度的内存效率(memory efficiency),并实现在长达128K的极长序列上进行训练。在CP中,我们沿着序列维度进行划分,具体来说,将输入序列(input sequence)划分为2×CP块,因此每个CP rank接收两个块以获得更好的负载平衡。第i个CP等级接收第i个和(2×CP-1-i)个块。
与现有的重叠通信和计算的CP实现不同(ring-like),我们的CP实现采用基于all-gather based的方法。这个方法首先all-gather 键(K)和值(V)张量,然后为local query(Q)张量块计算注意力输出。虽然all-gather通信延迟暴露在关键路径中,但我们仍然采用这种方法有两个主要原因:(1)在基于all-gather的CP注意力中支持不同类型的attention masks(如the document mask),更容易和更灵活;(2)由于使用了GQA,传递的K和V张量比Q张量要小得多,暴露的all-gather延迟很小。
**************************************************************


网络感知并行配置[Network-aware parallelism configuration.]
a.并行性维度的顺序,[TP,CP,PP,DP],针对网络通信进行了优化。
b.最内层的并行性需要最高的网络带宽和最低的延迟,因此通常限制在同一台服务器内。最外层的并行性可能跨越多跳网络,并且应该能够容忍更高的网络延迟。
c.因此,基于网络带宽和延迟的要求,将并行性维度排列为[TP,CP,PP,DP]。DP(即FSDP)是最外层的并行性,因为它可以通过异步预取分片模型权重和减少梯度来容忍更长的网络延迟。在避免GPU内存溢出的同时识别具有最小通信开销的最佳并行配置是具有挑战性的。开发内存消耗估算器和性能预测工具,帮助我们探索各种并行配置,预测整体训练性能并有效识别内存缺口。
数值稳定性[Numerical stability. ]:
a.通过比较不同并行设置下的训练损失(training loss),解决影响训练稳定性的多个数值问题(numerical issues)。
b.为了确保训练收敛,在反向计算过程中,使用FP32梯度累积多个微批次(multiple mirco-batchs),并且在FSDP中,跨数据并行workers 中减少FP32梯度的散布(ruduce-scatter gradients)。
c.对于在前向计算中多次使用的中间张量,例如视觉编码器输出,反向梯度也以FP32累积。
**************************************************************

集体通信[3.3.3 Collective Communication]
a.Llama 3集体通信库基于Nvidia的NCCL库的分支NCCLX。NCCLX显著提升了NCCL的性能,尤其是在高延迟网络环境下。
b.并行维度[parallelism dimensions]的顺序为[TP, CP, PP, DP],其中DP对应于FSDP。最外层的并行维度[The outermost parallelism dimensions]PP和DP可能通过多跳网络进行通信,延迟可达数十微秒。
c.原始的NCCL集合操作—FSDP中的all-gather和reduce-scatter,以及PP中的point-to-point—需要数据分块和分阶段的数据拷贝。这些方法存在若干低效之处,包括:(1) 需要在 网络上 交换大量 小的控制消息(small control messages)以促进数据传输, (2) 额外的内存拷贝操作(extra memory-copy operations),(3) 使用额外的GPU周期进行通信(using extra GPU cycles for communication.)。
d.在Llama 3训练中,通过调整数据分块( tuning chunking )和数据传输(data transfer )以适应我们网络的延迟(对于大型集群,延迟可高达数十微秒),上面操作解决了这些低效问题的一部分。同时我们还允许小的控制消息以更高的优先级穿越我们的网络,特别是避免在深缓冲核心交换机(deep-buffer core switches.)中被排队阻塞。
e.正在为未来的Llama版本进行的工作包括在NCCLX中进行更深层次的更改,以全面解决上述所有问题。
**************************************************************

可靠性和操作挑战[3.3.4 Reliability and Operational Challenges]
a.16K GPU的训练复杂性和潜在失败场景 超过 我们操作过的许多规模更大的CPU集群。训练的同步性质使其容错性较差—一个GPU故障可能需要重新启动整个工作。对于Llama 3:实现了高于90%的有效训练时间,同时支持自动化集群维护(如固件和Linux内核升级[导致至少1次训练中断/天])。
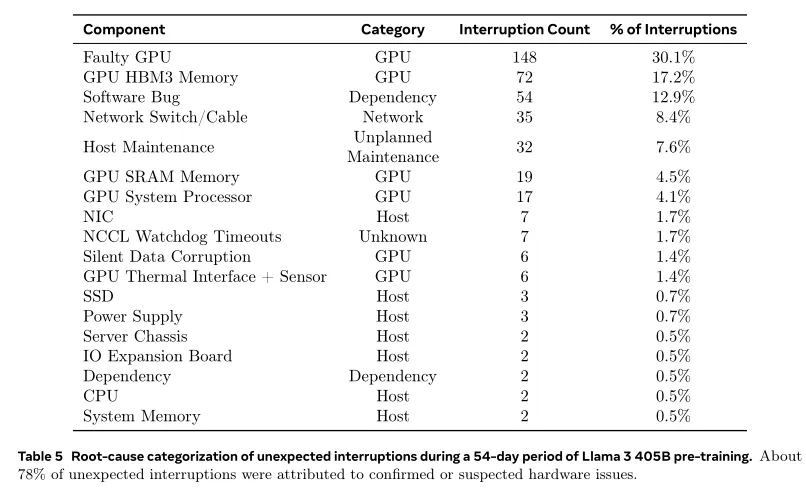
b.在为期54天的预训练期间,共经历466次工作中断。其中47次是计划中断,因自动化维护操作如固件升级或操作员发起的操作(如配置或数据集更新)而发生。其余的419次是意外中断,这些中断在表 5 中分类。大约78%的中断归因于确认的硬件问题(如GPU或主机组件故障)或疑似与硬件有关的问题(如隐性数据损坏和未经计划的单个主机维护事件)。GPU问题是最大的类别,占所有意外问题的58.7%。尽管故障数量很大,但在此期间仅有三次需要重大手动干预,其余问题由自动化处理。
c.为了增加有效训练时间,减少了作业启动和检查点保存的时间,并开发了快速诊断和问题解决的工具。广泛使用 PyTorch 的内置 NCCL 飞行记录器(Ansel 等, 2024),该功能将集合元数据和堆栈跟踪捕捉到环形缓冲区中,从而允许我们快速诊断挂起和性能问题,特别是在 NCCLX 方面。通过此功能,我们有效记录每个通信事件及每个集合操作的持续时间,并在 NCCLX 看门狗或心跳超时时自动转储跟踪数据。我们根据需要通过在线配置更改(Tang 等, 2015)启用更多计算密集型的跟踪操作和元数据收集,而无需代码发布或作业重启。
d.在大规模训练中,调试问题的复杂性受到我们网络中 NVLink 和 RoCE 混合使用的影响。通过 CUDA 内核发出的负载/存储操作进行的数据传输通常发生在 NVLink 上,而远程 GPU 或 NVLink 连接的故障往往表现为 CUDA 内核中的负载/存储操作停滞,但不会返回明确的错误代码。NCCLX 通过与 PyTorch 的紧密共同设计提高了故障检测和定位的速度和准确性,使 PyTorch 能够访问 NCCLX 的内部状态并跟踪相关信息。虽然由于 NVLink 故障导致的停滞无法完全避免,但我们的系统监控通信库的状态,并在检测到此类停滞时自动超时。此外,NCCLX 跟踪每个 NCCLX 通信的内核和网络活动,并提供失败的 NCCLX 集合的内部状态快照,包括所有排名间已完成和待处理的数据传输。我们分析这些数据来调试 NCCLX 扩展问题。
e.有时硬件问题可能导致仍在正常运行但速度较慢的滞后节点,这些滞后节点很难检测。即使是单个滞后节点也可能拖慢其他成千上万的 GPU,通常表现为功能正常但通信缓慢。我们开发新工具,以优先处理来自选定进程组的潜在问题通信。通过调查几个主要嫌疑对象,我们通常能够有效识别滞后节点。
f.有趣的观察是环境因素对大规模训练性能的有影响。对于 Llama 3 405B,注意到基于时间的日常吞吐量波动在 1-2% 之间。这种波动是由于中午温度升高影响 GPU 动态电压和频率调整所致。
、
g.在训练期间,成千上万的 GPU 可能同时增加或减少功耗,例如,因所有 GPU 等待检查点保存或集合通信完成,或整个训练作业的启动或关闭。当这种情况发生时,可能会导致数据中心功耗的瞬时波动,达到数十兆瓦,拉伸了电力网的极限。这是我们在为未来更大规模的 Llama 模型扩展训练时面临的持续挑战。
**************************************************************


Llama 3.1-405B的预训练包括三个主要阶段:1.初始预训练 2.长上下文预训练 3.退火[Annealing]。
1.初始预训练[Initial Pre-Training]
【初始化预训练过程】
a.使用余弦学习率调度(cosine learning rate schedule),峰值学习率为 8 × 10 ⁻⁵,线性预热(linear warm up)设置为8000 步,在 120w 个训练步骤内 学习率衰减至 8 × 10 ⁻⁷。
b.在训练初期采用较小的batch size以提高训练稳定性,并随后逐步增加以提高效率。
c.使用初始批量大小(batch size)为 4M 和 窗口长度为 4k的序列。经过预训练 252M(?) 个token后,将批量大小(batch size)为 8M,窗口长度为 8k的序列。在预训练了 2.87T 个标记后,再次将批量大小(batch size)增加到 16M。
d.发现这种训练配方非常稳定:观察到很少的损失波动,并且不需要干预来纠正模型训练的发散。
【调整数据组合】
在训练过程中,进行以下几项调整以改善模型在特定下游任务上的性能:
1.增加了预训练期间非英语数据的比例,以提升 Llama 3 的多语言性能。
2.对数学数据进行了过采样,以提高模型在数学推理任务上的表现。
3.在预训练的后期阶段添加了更多最新的网络数据,以推进模型的知识截断。
4.对预训练数据的某些子集进行了降采样,这些数据后来被确认为质量较低。
2.长文本训练[Long Context Pre-Training]
【长文本预训练过程】
a.在预训练的最后阶段,采用长文本数据对长序列进行训练,支持长达128K个token的上下文窗口。
b.早期不会使用长序列进行训练,因为自注意力层中的计算量会随着序列长度的增加呈二次增长。
c.采用逐步增加支持的上下文窗口长度策略,直到模型成功适应增加的上下文长度为止。
d.评估模型是否适应当前上下文长度的方式:(1)模型在短上下文评估中性能是否完全恢复;(2)模型是否能够在该长度的“大海捞针”任务 精确召回。
e.在 Llama 3 405B 的预训练中,分六个阶段逐步增加了上下文长度,从最初的8K上下文窗口增加到最终的128K上下文窗口。长上下文预训练阶段使用了大约800B个训练tokens。
3.退火[Annealing]
【退火预训练过程】
a.在最后的4000万个标记的预训练期间,线性将学习率lr退火至0,同时保持上下文长度为128K token。
b.在这个退火阶段,还调整数据配比,增加了非常高质量的数据源(比如数学、代码、逻辑内容)的影响;
c.最后,计算在退火期间 的多个模型checkpoint的平均值,以生成最终的预训练模型。
Llama 3 预训练包括三个主要阶段:(1) 初始预训练,(2) 长上下文预训练,以及 (3) 退火(Annealing)。总体而言,和目前一些其它开源模型的训练过程差别不大,不过技术报告公开了很多技术细节。
a.初始预训练:就是常规的预训练阶段,训练初期使用较小Batch Size以稳定训练,随后逐步增大以提高效率,最终达到 16M token 的Batch大小。为了提升模型的多语言和数学推理能力,增加了非英语和数学数据的比例。
b.长上下文预训练:在预训练的后面阶段,采用长文本数据对长序列进行训练,支持最多128K token的上下文窗口。采取逐步增加上下文窗口长度策略,在Llama3.1 405B的预训练中,从最初的8K上下文窗口开始,逐步增加上下文长度,最终达到128K上下文窗口。这个长上下文预训练阶段使用了大约800B训练token数据。
c.退火(annealing):在预训练的最后4000万个token期间,线性地将学习率退火至0,同时保持上下文长度为128K个token。在这一退火阶段,调整了数据混合配比,以增加高质量数据比如数学、代码、逻辑内容的影响。最后,将若干退火期间模型Check Point的平均值,作为最终的预训练模型。在训练后期对高质量数据进行上采样目前其实也是比较标准的做法。--张俊林
【引用链接】:https://www.zhihu.com/question/662354435/answer/3572364267
**************************************************************




模型后训练-Llama3.1
2.在预训练检查点的基础上通过人类反馈对齐。
LLaMA3.1 Post-Training流程
**************************************************************

**************************************************************
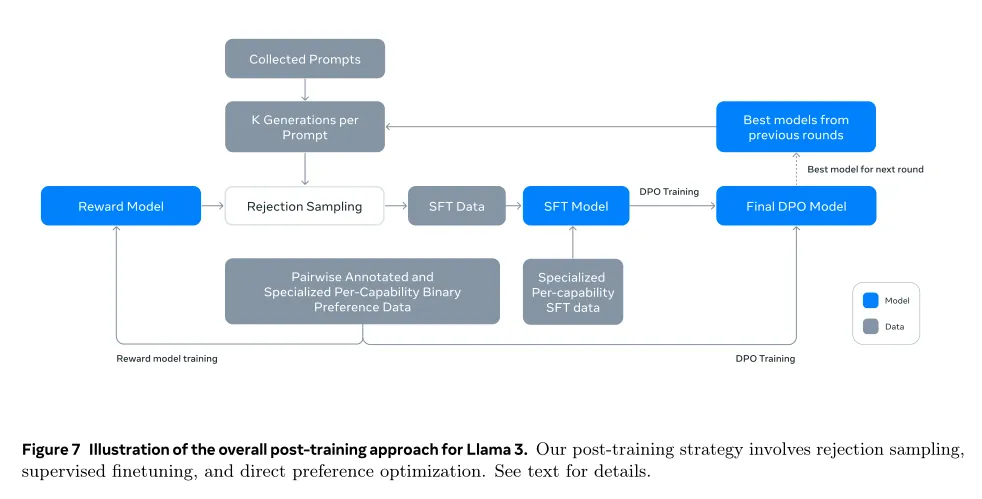
目前LLM的Post-Training主要有两种模式,一种是仿照ChatGPT的SFT+RM+PPO的模式,采用强化学习,需要调的超参很多,比较复杂不太好调通;另外一种是SFT+DPO的模式,去掉了PPO强化学习,相对简化了整个流程,比较容易跑起来。LLaMA3.1在这个阶段主体结构是SFT+DPO的模式,不过也有自己特殊的一些设计,上图展示了LLaMA3.1整个Post-Training的流程。
首先用人工标注数据训练RM模型,用来评价一个<Prompt,answer>数据的质量,然后用RM参与拒绝采样(Rejection Sampling),就是说对于一个人工Prompt,用模型生成若干个回答,RM给予质量打分,选择得分最高的保留作为SFT数据,其它抛掉。这样得到的SFT数据再加上专门增强代码、数学、逻辑能力的SFT数据一起,用来调整模型得到SFT模型。之后用人工标注数据来使用DPO模型调整LLM参数,DPO本质上是个二分类,就是从人工标注的<Prompt,Good Answer,Bad Answer>三元数据里学习,调整模型参数鼓励模型输出Good Answer,不输出Bad Answer。这算完成了一个迭代轮次的Post-Training。
上述过程会反复迭代几次,每次的流程相同,不同的地方在于拒绝采样阶段用来对给定Prompt产生回答的LLM模型,会从上一轮流程最后产生的若干不同DPO模型(不同超参等)里选择最好的那个在下一轮拒绝采样阶段给Prompt生成答案。很明显,随着迭代的增加DPO模型越来越好,所以拒绝采样里能选出的最佳答案质量越来越高,SFT模型就越好,如此形成正反馈循环。
可以看出,尽管RLHF 和DPO两种模式都包含RM,但是用的地方不一样,RLHF是把RM打分用在PPO强化学习阶段,而LLaMA3.1则用RM来筛选高质量SFT数据。而且因为拒绝采样的回答是由LLM产生的,可知这里大量采用了合成数据来训练SFT模型。
后训练Modeling[建模]流程:[训练奖励模型]使用人类注释的偏好数据在预训练的检查点之上训练奖励模型。[SFT]使用有监督微调(SFT)对预训练的检查点进行微调,[DPO]通过直接偏好优化(DPO)对检查点进行对齐。后训练策略的核心是一个奖励模型( a reward model)和一个语言模型(a language model.)。
【奖励模型RM】
a.在预训练检查点的基础上训练一个覆盖不同能力的奖励模型(RM)。训练目标与Llama 2相同,但移除了损失中的边际项,因为在数据扩展后观察到其改进效果递减。
b.与Llama 2类似,在过滤出类似响应的样本后,使用所有的偏好数据进行奖励建模。除了标准的偏好对(chosen,rejected) ,注释还为某些提示创建了第三个“编辑响应”,其中选定的响应进一步被编辑以改进。因此,每个偏好排序样本都有两个或三个响应,并且有明确的排序 (edited > chosen > rejected).
c.在训练过程中,将提示[prompt]和多个响应[multiple responses]串联成一行,并随机对响应进行混洗。这是对将响应放在单独行中计算分数的标准场景的一种近似,但在我们的实验中,这种方法提高了训练效率而不损失准确性。
【有监督学习SFT】
a.奖励模型用于在的人类注释提示上执行拒绝抽样。将这些拒绝抽样数据[ rejection-sampled data]与其他数据源[other data sources](包括合成数据)一起,使用标准的交叉熵损失[standard cross entropy loss]在目标标记上对预训练语言模型进行微调(同时在提示标记上进行损失屏蔽),这个阶段为监督微调(SFT),即使许多训练目标[ training targets]是模型生成的。
b.最大模型在8.5K到9K个步骤内以1e-5的学习率进行微调。发现这些超参数设置在不同轮次和数据混合中表现良好。
【直接偏好优化DPO】
a.进一步使用直接偏好优化(DPO)对的SFT模型进行训练,以进行人类偏好的对齐。在训练过程中,主要使用最近收集的偏好数据批次,这些数据是使用前一轮对齐效果最好的模型收集的。因此,我们的训练数据更好地符合每一轮优化的策略模型的分布。
b.还探索了基于策略的算法,如PPO,但发现DPO对于大规模模型需要更少的计算资源,并且在诸如IFEval的指令遵循基准测试中表现更好。对于Llama 3,使用1e-5的学习率,并将β超参数设置为0.1。
**************************************************************




【模型平均化Model Averaging】
对每个奖励模型(RM)、监督微调(SFT)或直接偏好优化(DPO)阶段 使用不同版本数据或超参数 的实验结果进行模型平均化。[增强模型泛化能力]
【迭代轮次Iterative Rounds】
与 Llama 2 类似,使用上述RM,SFT,DPO方法 迭代六轮。在每轮迭代中,收集新的偏好注释和 SFT 数据,并从最新模型中采样合成数据。[增强数据质量]
**************************************************************


【后训练数据】a.人类标注程序和偏好数据收集,human annotation procedures and preference data collectionb.SFT数据的组成,the composition of our SFT data c.数据质量控制和清理方法,
methods for data quality control and cleaning

【偏好数据构建流程】
a.偏好数据标注过程类似于 Llama 2。在每一轮中使用多个模型进行标注。对于每个用户提示,并从两个不同模型的中抽样出两个响应[responses]。这些标注模型可以使用不同的数据组合和对齐方案进行训练,从而允许具有不同能力强度(例如,代码专业知识)和增加数据多样性。
【偏好数据构建细节】
a.要求注释者根据他们更喜欢的响应相对于被拒绝的响应的程度将偏好 划分为四个级别之一:显著更好、更好、稍微更好或边缘更好[significantly better, better, slightly better, or marginally better. ]。
b.在偏好排序后增加编辑步骤,鼓励注释者进一步改进他们更喜欢的响应。注释者可以直接编辑选择的响应,或通过反馈提示模型来改进其自身的响应。因此,我们的偏好数据中的一部分有三个响应被排序为(edited > chosen > rejected)。
c.实施了质量分析和人工评估过程,严格评估收集到的数据,允许我们优化提示并向注释者提供系统化的可操作反馈。例如,随着每轮 Llama 3 的改进,我们相应地增加提示的复杂性,以针对模型滞后的领域。
d.在每轮后训练中,使用那时可用的所有偏好数据进行奖励建模,同时仅使用来自各种能力的最新批次进行 DPO 训练。对于奖励建模和 DPO,我们使用标记为所选择响应显著更好或更好于被拒绝对应物的样本进行训练,并且丢弃类似响应的样本。
在表6中,报告用于 Llama 3 训练的偏好标注统计数据。通用英语涵盖了多个子类别,如基于知识的问答或精确的指令跟随,这些超出了特定能力范围。与 Llama 2 相比,我们观察到提示和响应的平均长度增加,表明我们在更复杂的任务上训练 Llama 3。
**************************************************************

【微调数据主要来源】
a.来自我们的人类注释收集的提示,以及拒绝抽样的回应
b.针对特定能力的合成数据(详见第4.3节,了解更多细节)
c.少量经过人类精心策划的数据(详见第4.3节,了解更多细节)
在后训练轮次中,逐步开发出更强大的Llama 3变体,用于收集涵盖广泛复杂能力的更大数据集。
本节中,讨论拒绝抽样过程的详细信息以及最终SFT数据混合的整体组成。
【拒绝抽样过程的详细信息】
在拒绝抽样过程(RS)中,针对每个人类注释收集的提示,从最新的聊天模型策略中(通常是上一轮后训练中表现最佳的检查点,或者特定能力的最佳检查点)采样K个(通常在10到30之间)输出,并使用我们的奖励模型选择最佳候选者。在后续的后训练轮次中,引入系统提示来引导RS响应,以符合所需的语气、风格或格式,这可能针对不同的能力有所不同。
为了提高拒绝抽样的效率,采用PagedAttention。PagedAttention通过动态键-值缓存分配增强了内存效率。它通过基于当前缓存容量动态调度请求,支持任意输出长度。然而,这也带来了内存不足时交换的风险。为了消除这种交换开销,我们定义了最大输出长度,并仅在有足够内存容纳该长度的输出时执行请求。PagedAttention还允许我们在所有对应输出之间共享提示的键-值缓存页。这些措施共同导致了拒绝抽样时吞吐量的提升超过2倍。
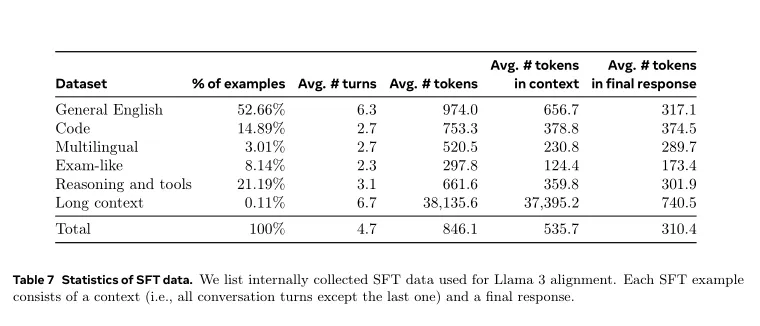
【SFT数据混合的整体组成】
表7显示了我们“有用性”混合的每个广泛类别的数据统计。虽然SFT和偏好数据包含重叠领域,但它们经过不同的策划,产生了不同的计数统计。描述了对数据样本的主题、复杂性和质量进行分类的技术。在每一轮后训练中,我们仔细调整整体数据混合,跨这些方面调节性能,以应对广泛的基准测试要求。最终数据混合在某些高质量来源上多次执行迭代,并降低其他来源的采样频率。
**************************************************************


Given that most of our training data is model-generated,it requires careful cleaning and
quality control.
【数据清洗.Data cleaning】
在早期的迭代轮次中,观察到数据中存在一些undesirable patterns common,比如过度使用表情符号或感叹号。实施一系列基于规则的数据移除和修改策略[rule-based data removaland modification strategies],以过滤或清理问题数据。例如,为了缓解过度道歉的语调问题,我们识别出常用短语(如“I'm sorry”或“I apologize”),并在数据集中谨慎平衡这类样本的比例。
【数据修剪.Data pruning】
应用基于模型的技术[ model-based techniques]来移除低质量的训练样本,以提高整体模型性能:
a.主题分类[Topic classification]:首先将Llama 3-8B微调成[ topic classifier],并对所有数据进行推断,将其分类为粗粒度桶[coarsely-grained buckets ](如“数学推理”)和细粒度桶[fine-grained 18 buckets](如“几何和三角法”)。
b.质量评分[Quality scoring]:利用 reward model 和 Llama-based signals为每个样本获取质量评分。对于基于奖励模型的评分[ RM-based score],将RM分数处于最高四分位数的数据视为 高质量数据。对于基于Llama的评分[Llama-based score],我们提示Llama 3检查点对每个样本进行评分,对一般英语数据(准确性、指令跟随和语调/表达)使用三分制,对编码数据(错误识别和用户意图)使用二分制,并将获得最高分数的样本视为高质量数据。奖励模型[ RM]和基于Llama评分[Llama-based scores]存在高度分歧率,并且发现将这些信号结合 使用可以 在内部测试集上 实现最佳的召回率。最终,我们选择标记为高质量的示例,是由奖励模型RM或the Llama-based filter的。
c.难度评分[Difficulty scoring]:因为还希望优先考虑对模型更复杂的示例,使用两种难度评分措施:Instag和基于Llama的评分[ Llama-based scoring]。对于Instag,我们提示Llama 3-70B对SFT提示进行意图标记,其中意图越多,意味着越复杂。还提示Llama 3在three-point scale上评估对话的难度。
d.语义去重复[Semantic deduplication]:最后执行语义去重。首先使用RoBERTa对完整对话(complete dialogs )进行聚类,并在每个聚类中按质量评分×难度评分( quality score × difficulty score.)进行排序。然后,通过迭代所有排序的示例,并 仅保留 与迄今为止在该聚类中看到的示例的最大余弦相似度低于阈值的示例,进行贪婪选择。
**************************************************************


模型效果-Llama3.1

【5.1 预训练语言模型】
a.报告了我们预训练的Llama 3(第3节)的评估结果,并与各种其他大小相当的模型进行比较。我们在可能的情况下复现了竞争模型的结果。对于非Llama模型,我们报告了公开报道或(可能的情况下)我们自己复现的最佳分数。这些评估的具体细节,包括配置(如shots的数量)、指标和其他相关的超参数和设置,可以在我们的Github仓库这里找到。
b.另外,还发布了作为公开可用基准测试一部分生成的数据,可以在Huggingface这里找到。我们在标准基准测试上评估我们模型的质量(5.1.1节),对多选题设置变化的鲁棒性(5.1.2节),以及在对抗评估上的表现(5.1.3节)。我们还进行了一项污染分析,以估计我们的评估受到训练数据污染程度的影响(5.1.4节)。
**************************************************************

【5.2 后训练语言模型】
a.在不同能力的基准测试上展示了我们Llama 3的后训练模型的结果。与预训练类似,我们发布了作为公开可用基准测试一部分生成的数据,可以在Huggingface-here找到。关于我们评估设置的额外细节-here。
b.基准测试和指标。表16概述了所有基准测试,按能力(capability)组织排列。通过使用每个基准测试的提示进行精确匹配来对后训练数据进行去污染处理。除了标准的学术基准测试外,还进行了对不同能力的广泛人工评估。详细信息请参见第5.3节。
c.实验设置。采用类似的实验设置来进行后训练阶段,并与其他大小和能力相当的模型进行比较分析。在可能的情况下,我们自行评估其他模型的性能,并将结果与报告的数字进行比较,选择最佳分数。您可以here找到关于我们评估设置的额外细节。
**************************************************************


【5.4 安全性 】
a.我们的研究重点在于评估Llama 3在生成内容时以安全和负责任的方式,同时最大化有用信息的能力。我们的安全工作始于预训练阶段,主要是通过数据清洗和过滤来实现。然后,我们描述了我们的安全微调方法,重点是如何训练模型以符合特定的安全政策,同时保留有益信息的能力。我们分析了Llama 3的各种能力,包括多语言、长篇文本、工具使用和各种多模态能力,以评估我们安全缓解措施的有效性。
b.接下来,我们描述了我们对网络安全和化学生物武器风险的提升评估。提升指的是与使用现有可用技术(如网页搜索)相比,新技术发展引入的额外风险。
c.然后,我们描述了如何利用红队测试来迭代地识别和应对各种能力中的安全风险,并进行剩余风险评估。
d.最后,我们描述了系统级安全性,即围绕模型输入和输出开发和协调分类器,进一步增强安全性,并使开发人员能够更轻松地根据各种用例定制安全性,并以更负责任的方式部署生成式人工智能。
模型推理-Llama3.1
a.当使用BF16数值表示模型参数时,Llama3 405B模型不能适应单机配备8个Nvidia H100 GPU的内存。为解决这个问题,使用BF16精度在两台机器的16个GPU上并行化模型推理。在每台机器内部,高NVLink带宽使得可以使用张量并行。然而,跨节点的连接具有较低的带宽和较高的延迟,因此使用流水线并行。
b.在使用流水线并行进行训练时,气泡是主要的效率问题(见第3.3节)。然而,在推理过程中,它们并不是一个问题,因为推理不涉及需要刷新流水线的反向传递。因此,我们使用微批处理(micro-batching)来提高在流水线并行时(pipeline parallelism.)的推理吞吐量。
c.评估了在推理工作负载中使用两个微批处理[micro-batches ]的效果,包括使用4096个输入token和256个输出token,无论是在推理的键值缓存(kv-cache)预填充阶段(the key-value cache pre-fill stage of inference)还是解码阶段(the decoding stage)。我们发现,微批处理( micro-batching)提高具有相同本地批处理大小的推理吞吐量;请参见图24。这些改进结果来自微批处理( micro-batching)在这两个阶段中并行执行微批次。由于微批处理引入了额外同步点,也会增加延迟,但总体上,微批处理仍然带来更好的吞吐量-延迟的平衡。
**************************************************************


a.利用H100 GPU的原生FP8支持,执行低精度推理实验。为了实现低精度推理,对模型内的大多数矩阵乘法应用FP8量化。具体来说,对模型中前馈网络层中的大多数参数和激活进行量化,这大约占推断计算时间的50%。没有对模型的自注意力层进行参数量化。
b.利用动态缩放因子来提高精度,优化我们的CUDA核,减少计算比例的开销。
c.发现Llama 3 405B的质量对某些类型的量化很敏感,并进行了一些额外的更改以提高模型的输出质量:
1.不对Transformer的第一层和最后一个层进行量化。2. 高困惑度token(High-perplexity tokens).例如日期,可能导致较大的激活值。反过来,这可能导致FP8中较高的动态缩放因子( high dynamic scaling factors)和一定数量的下溢(a non-negligible number of underflows),从而导致解码错误。为了解决这个问题,将动态缩放因子的(the dynamic scaling factors )上限设定为1200。3.使用逐行量化,在参数和激活矩阵的行之间计算缩放因子(见图25)。发现这比张量级(tensor-wise)量化方法效果更好。
**************************************************************


【量化误差的影响.Effect of quantization errors】
a.对标准基准( standard benchmarks)的评估通常表明,即使没有这些缓解措施,FP8推断的性能也与BF16推断相当。
b.然而发现这些基准测试( such benchmarks)并未充分反映FP8量化的影响。当缩放因子(scaling factors)没有上限时,即使基准性能强大,模型有时也会产生损坏的响应(produces corrupted responses )。
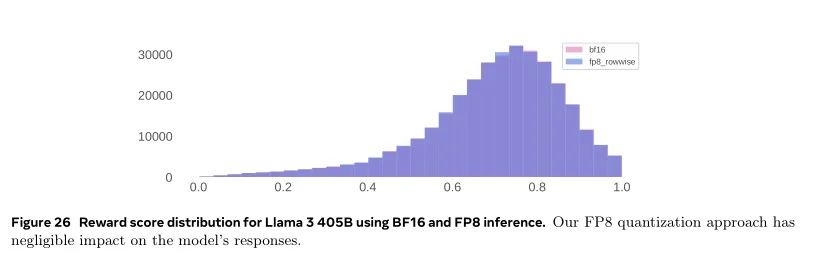
c.与其依赖基准测试来衡量 量化引起的分布变化(distribution changes),发现不如分析使用FP8和BF16生成的10万个响应的奖励模型分数分布( the distribution of reward-model scores )更为有效。
图26展示了我们量化方法的奖励分布。图中的结果表明,我们的FP8量化方法对模型的响应影响非常有限。
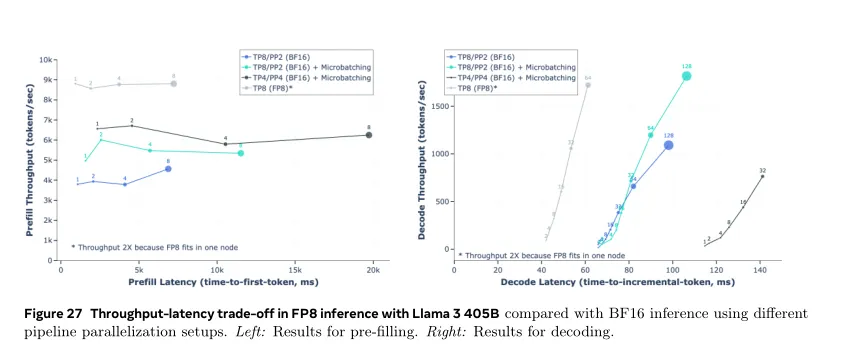
【效率的实验评估.Experimental evaluation of efficiency】
a.图27描述了使用Llama 3 405B在预填充和解码阶段[ the pre-fill and decoding stages,]执行FP8推断时的吞吐量-延迟权衡[throughput-latency trade-off],使用4096个输入token和256个输出token。该图比较了FP8推断的效率与第6.1节描述的两机BF16推断方法的效率。
b.结果显示在预填充阶段( the pre-fill stage),使用FP8推断可以提高高达50%的吞吐量,并在解码过程(during decoding.)中获得更好的吞吐量-延迟权衡( better throughput-latency trade-off )。
**************************************************************

a.在Post-Training阶段,合成数据目前已经产品化。尤其是其中的SFT阶段,目前看在朝着完全由合成数据主导的方向发展。比如LLama3.1 的SFT数据里有相当比例是由模型生成的合成数据,而Gemma2 在SFT阶段的数据很大比例是由规模更大的模型合成的,且证明了合成数据质量不比人工标注质量差。
b.在预训练阶段,类似Dalle-3和Sora这种由语言大模型根据图片或视频改写人写好的文字描述,也已实用化。
c.目前合成数据的一个重点方向是在Post-Training阶段对数学、逻辑、代码等数据的合成,数据质量将直接极大影响模型最终效果。
d.严格来说,目前的所谓合成数据只是“半合成数据”,比如Sora的<视频,人写文字描述<视频,模型改写文字描述>,以及Post-Training阶段的<Prompt,人写答案><Prompt,模型生成答案>,都是部分人工数据、部分模型生成数据,所以称其为“半合成数据”感觉更为恰当。
e.如果深入思考一下,你会发现合成数据其实是模型蒸馏的一种变体,算是一种特殊的模型蒸馏。(LLM预训练预测Next Token,其实是人类作为Teacher,LLM作为student。所以LLM本身就是对人类知识的蒸馏。合成数据是更大的模型输出数据作为Teacher,小点的模型作为Student从中学习知识,所以其实本质上是一种模型蒸馏。)
【引用链接】:https://www.zhihu.com/question/662354435/answer/3572364267
文章来源微信公众号zzichen




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
