
首创TTFA指标!港大团队开源FASTER,让VLA模型真正实现「即刻响应」
首创TTFA指标!港大团队开源FASTER,让VLA模型真正实现「即刻响应」具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。
来自主题: AI技术研报
8135 点击 2026-05-15 09:55
 搜索
搜索
具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。
Factory 发布桌面端应用,让自治 AI 代理(Droids)直接在你的电脑上操控 VS Code、浏览器、终端和 Excel——官方原话是「像你一样操作你的电脑」。多代理并行、持久化机器、本地模型部署一步到位,官方称企业团队采用速度翻倍、会话量暴涨 4.6 倍。发布推文 21 万人围观,近 900 人点赞。
就在奥特曼公开支持 Anthropic、声称反对五角大楼施压后不到 12 小时,剧情发生了戏剧性逆转。刚刚,奥特曼在 X 上连发三条相同的帖子,宣布 OpenAI 已与美国五角大楼达成协议,将模型部署到他们的机密网络中。

随着AI浪潮的袭来,笔者本人以及团队都及时的调整了业务方向,转型为一名AI开发者和AI产品开发团队,常常需要微调大模型注入业务场景依赖的私域知识,然后再把大模型部署上线进行推理,以支撑业务智能体或智能问答产品的逻辑流程。
前不久我写了一篇百度最新的OCR模型(PaddleOCR-VL)的文章反响还不错。
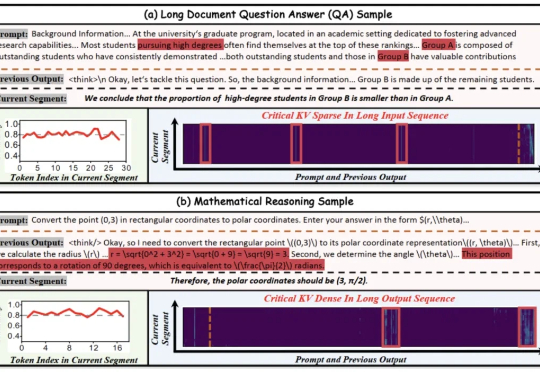
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。

AI公务员的大脑就是政务大模型。 就在刚刚,中央网信办和国。就在刚刚,中央网信办和国家发展改革委联合印发了重磅文件——《政务领域人工智能大模型部署应用指引》(我们后面就叫它《指引》)。
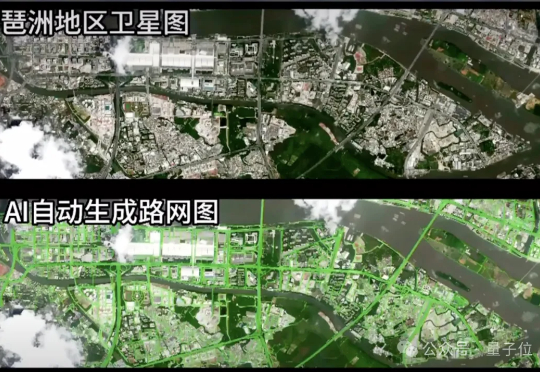
在一场视觉算法挑战中,一组参赛团队将道路识别模型部署至在轨卫星,完成了从图像采集、模型推理到结构化结果回传的全过程。 图像未落地,模型也并未运行在地面,所有计算任务均在轨道上完成,最终仅回传识别结果。
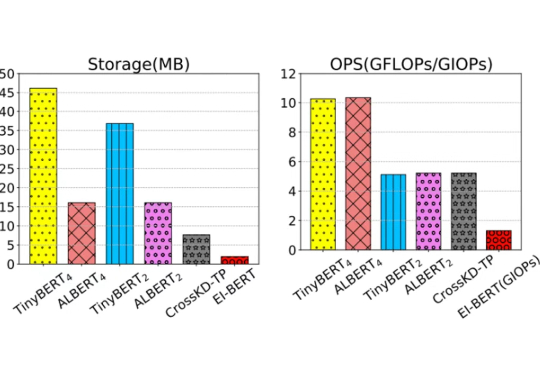
在移动计算时代,将高效的自然语言处理模型部署到资源受限的边缘设备上面临巨大挑战。这些场景通常要求严格的隐私合规、实时响应能力和多任务处理功能。
边缘-云协同计算通过整合边缘节点和云端资源,解决了传统云计算的延迟和带宽问题,推动了分布式智能和模型优化的发展。最新综述论文系统梳理了ECCC的架构设计、模型优化、资源管理、隐私安全和实际应用,提出了统一的分布式智能与模型优化框架,为未来研究提供了方向,包括大语言模型部署、6G整合和量子计算等前沿技术。