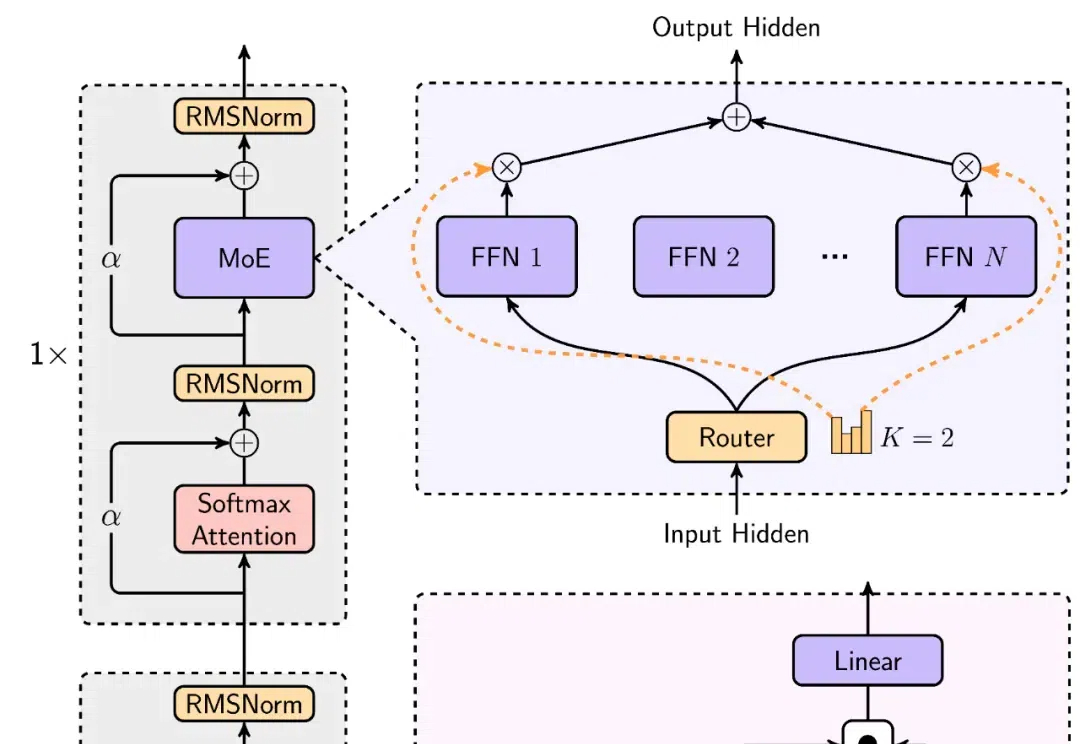
MiniMax震撼开源,突破传统Transformer架构,4560亿参数,支持400万长上下文
MiniMax震撼开源,突破传统Transformer架构,4560亿参数,支持400万长上下文「2025 年,我们可能会看到第一批 AI Agent 加入劳动力大军,并对公司的生产力产生实质性的影响。」——OpenAI CEO Sam Altman
来自主题: AI技术研报
9662 点击 2025-01-15 14:06
 搜索
搜索
「2025 年,我们可能会看到第一批 AI Agent 加入劳动力大军,并对公司的生产力产生实质性的影响。」——OpenAI CEO Sam Altman

大家可能看到过很多类似的结论:针对特定任务,对开源模型进行 LoRA 微调可以干翻 GPT-4 这类闭源模型。

因为 V3 版本开源模型的发布,DeepSeek 又火了一把,而且这一次,是外网刷屏。 训练成本估计只有 Llama 3.1 405B 模型的 11 分之一,后者的效果还不如它。

DeepSeek-v3大模型横空出世,以1/11算力训练出超过Llama 3的开源模型,震撼了整个AI圈。
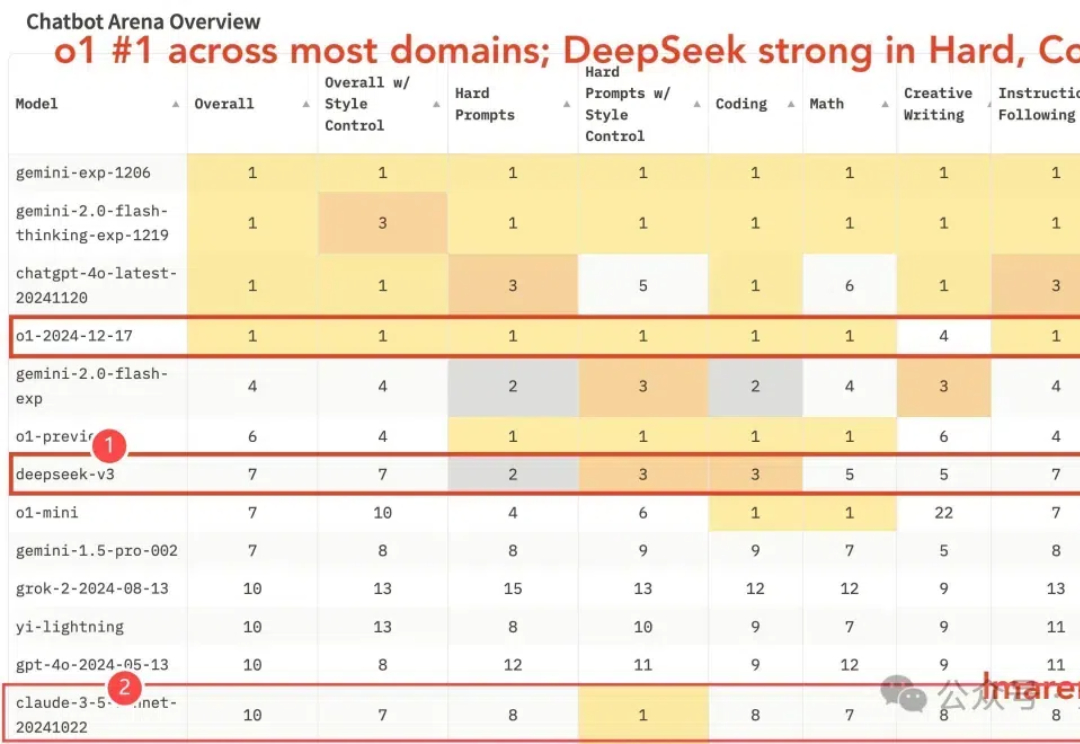
国产之光DeepSeek V3竞技场排名新鲜出炉—— 优于o1-mini(总榜第7),获最强开源模型认证(也是唯一闯入前10的开源模型)。

一个来自中国的开源模型,让整个AI圈再次惊呼“来自东方的神秘力量”。 昨天,国内知名大模型创业公司“深度求索”通过官方公众号宣布上线并同步开源 DeepSeek-V3模型,并公布了长达53页的训练和技术细节。

都说国产大模型“通义千问”能打,到底是真强还是智商税?今天就带你看看,这个国产“AI猛将”凭什么火出圈! 2023年4月,阿里巴巴推出通义千问,选择了“全开源”的策略,成为全球开发者关注的焦点。而在2024年的云栖大会上,阿里云进一步发布了Qwen2.5系列,包括多个尺寸的大语言模型、多模态模型、数学模型和代码模型,涵盖从0.5B到72B的完整规模

OpenAI在LangSmith用户群中继续稳居最常使用的大语言模型供应商宝座,其使用率是排名第二的Ollama的六倍以上。开源模型的采用率有了显著增长,特别是Ollama和Groq两家公司,它们支持用户运行开源模型,并在今年成功跻身行业前五。

全球首个端侧全模态理解开源模型来了!
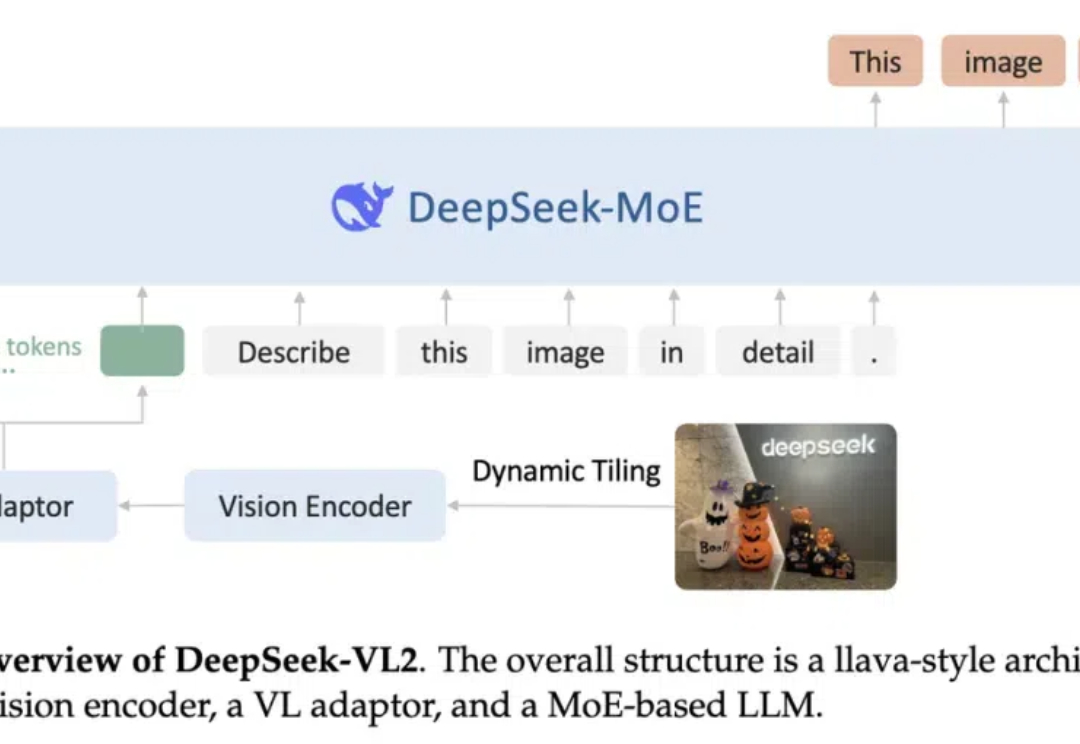
阔别九月,大家期待的 DeepSeek-VL2 终于来了!DeepSeek-MoE 架构配合动态切图,视觉能力再升级。从视觉定位到梗图解析,从 OCR 到故事生成,从 3B、16B 再到 27B,DeepSeek-VL2 正式开源。