# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

【新智元导读】来自UC berkeley的研究人员开源了首个世界模型,多模态性能优秀,长视频理解吊打GPT-4,同时将上下文长度增加到百万级别
首个开源「世界模型」来了!
来自UC berkeley的研究人员发布并开源了LWM(LargeWorldModel)系列模型:

论文地址:https://arxiv.org/pdf/2402.08268.pdf
代码地址:https://github.com/LargeWorldModel/LWM
LWM采用了一个包含各种视频和书籍的大型数据集,利用RingAttention技术对长序列进行可扩展的训练,最终将上下文长度增加到1M token。
在超长上下文的加持下,LWM系列模型可以轻松完成各种多模态任务,
比如文本图像生成(LWM 基于文本提示以自回归方式生成图像):


文本视频生成:

烟花在天空中爆炸
海浪拍打着海岸

伦敦熙熙攘攘的街道,背景是红色的电话亭和大本钟
桌子上的芒果切片,相机从左向右移动

一个球在空中飞舞
慢动作花瓣落在地上

森林中燃烧的篝火
一艘在波涛汹涌的海洋上航行的船
基于图像的对话:

用户:如果你是一名摄影师,想要捕捉这个地点的精髓,你会选择一天中的什么时间和天气条件?描述您选择背后的原因。
LWM:我会选择日落时分的时间。这张照片的特点是一个木制码头,延伸到平静的湖面,是宁静而风景如画的场景。夕阳在湖面上投下温暖的金色光芒,增强了场景的宁静。此外,天气条件似乎是凉爽和多云的,这与湖泊和木制码头的自然美景相得益彰。这些元素的结合营造出一种视觉上吸引人且平静的氛围,将是理想的时机。

用户:描述一下不同观众如何以不同的方式解释经典艺术作品的这种创造性转折。
LWM:在对经典艺术作品的创造性转折中,女人的脸变成了狗的脸,创造了视觉上引人注目和意想不到的表现。这件艺术品可以看作是对人类理解的局限性,以及人类与动物之间更深层次的联系和理解的评论。
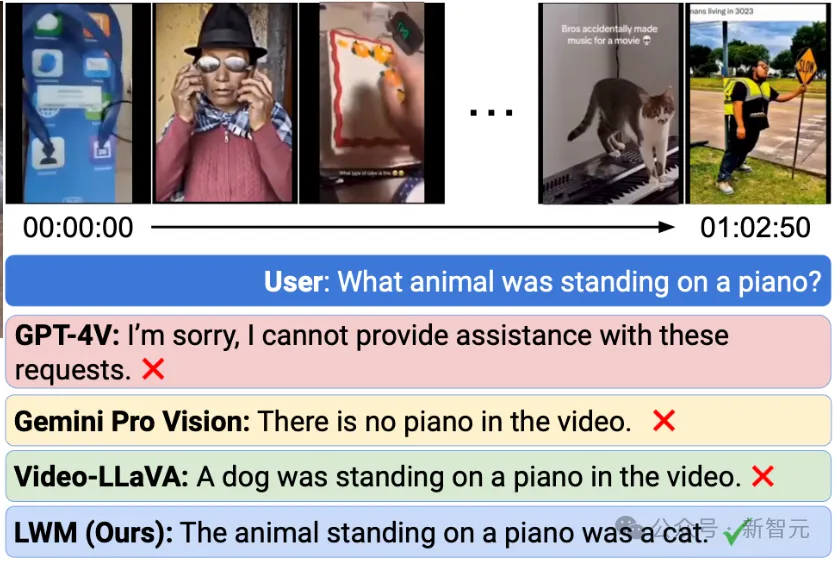
观看长视频(超过一小时),并回答问题:

即使最先进的商业模型GPT-4V和Gemini Pro也都失败了。
虽说「世界模型」还是个概念股吧,但LWM展现出的多模态能力是相当优秀的。
关键是,人家是开源的(基于Llama2 7B),于是受到广大开发者的热烈欢迎,仅仅不到两周的时间,就在GitHub上斩获了6.2k stars。

LWM在博客开头就展示了自己的优势区间,除了上面提到的长视频理解,下图比较了几个模型的事实检索能力:
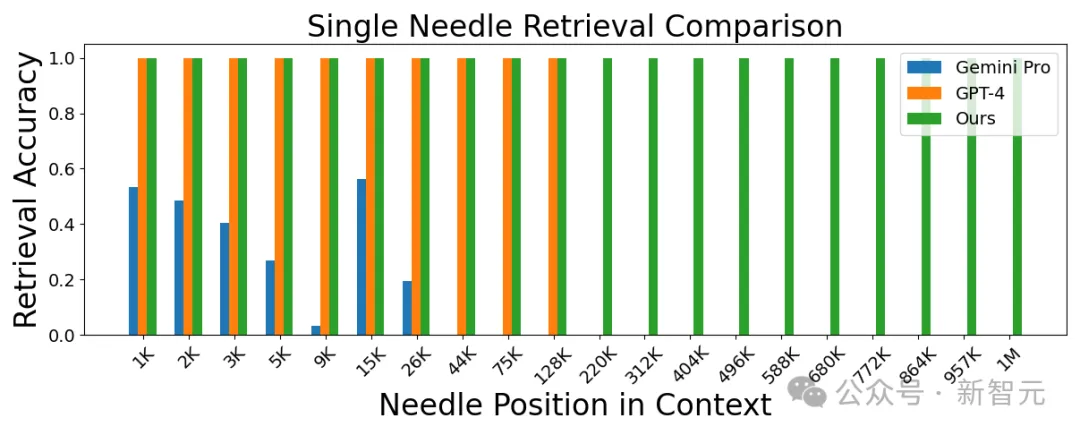
LWM在1M上下文窗口内实现了高精度,性能优于GPT-4V和Gemini Pro。
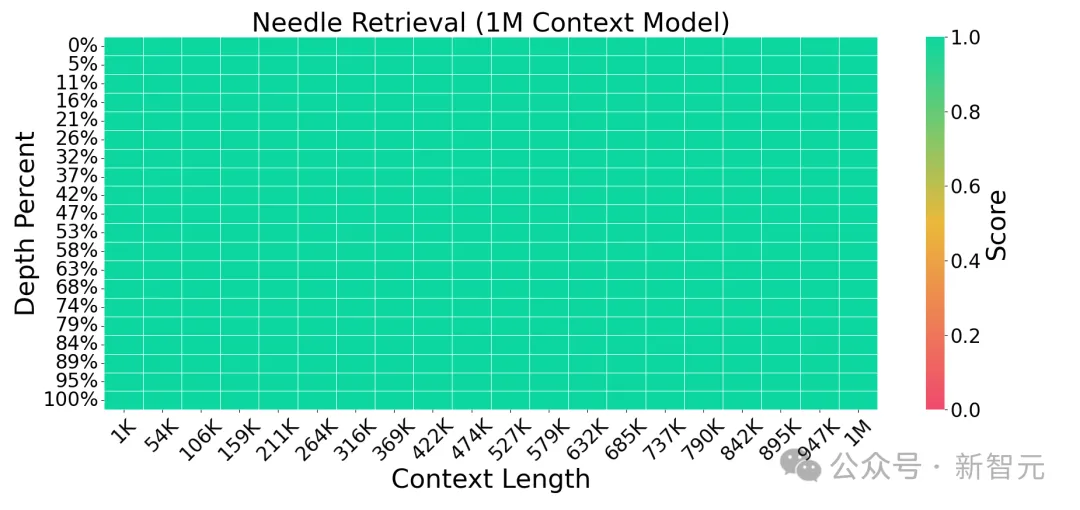
我们可以看到,LWM在在不同的上下文大小和位置上都保持了高精度(全绿)。
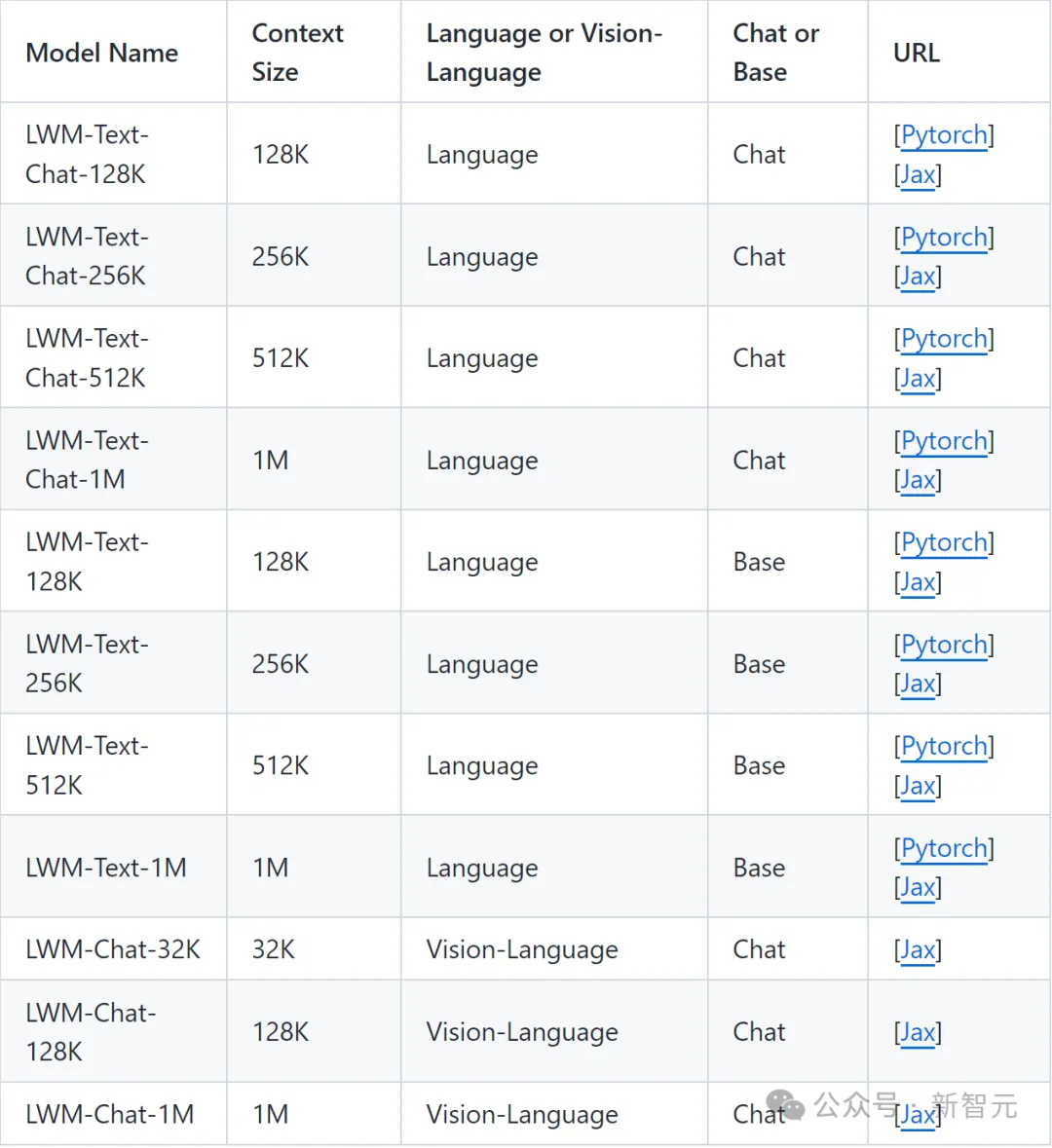
目前,LWM放出了一系列不同上下文大小(从32K到1M)的模型,包括纯语言版本和视频语言版本。其中视觉语言模型仅在Jax中可用,纯语言模型在PyTorch和Jax中都可用。
开源技术细节

上图展示了LWM的多模态训练。
第一阶段是上下文扩展,重点是使用Books3数据集扩展上下文大小,从32K增长到1M。
第二阶段,视觉语言培训,重点是对不同长度的视觉和视频内容进行培训。饼图详细说明了训练数据的分布情况,包括495B的文本-视频数据,以及33B的文本数据。
图中还展示了模型的交互功能。
这个阶段首先开发LWM-Text和LWM-Text-Chat,通过使用RingAttention逐步增加序列长度数据进行训练,并修改位置编码参数以考虑更长的序列长度。
由于计算的二次复杂度所施加的内存限制,对长文档的训练非常昂贵。
为了解决计算限制,研究人员使用RingAttention,利用具有序列并行性的块计算在理论上扩展到无限上下文,仅受可用设备数量的限制。
作者使用Pallas进一步将RingAttention与FlashAttention融合在一起,以优化性能。通常,如果每个设备有足够大的token,RingAttention期间的通信成本与计算完全重叠,并且不会增加任何额外的开销。
模型以LLaMA-2 7B为基础,分5个阶段逐步增加模型的有效上下文长度:32K、128K、256K、512K和1M。对于每个阶段,使用来自The Pile的Books3数据集的不同过滤版本进行训练。
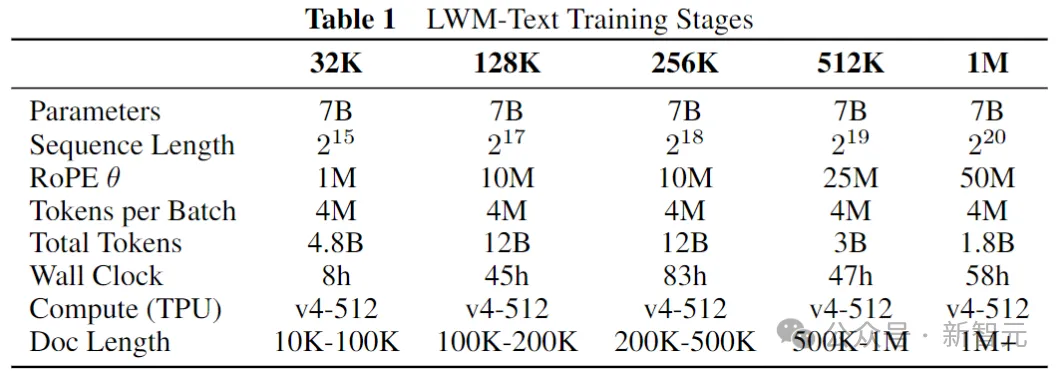
上表详细介绍了每个训练阶段的信息,例如token数量、总时间和Books3数据集过滤约束。每个阶段以前一个阶段作为初始化。
研究人员还构建了一个简单的QA数据集,用于学习长上下文聊天能力。将Books3数据集中的文档分块成1000个token的固定块,将每个块提供给短上下文语言模型,并提示它生成一个关于该段落的问答对。
对于聊天模型的微调,研究人员在UltraChat和自定义QA数据集上训练每个模型,比例约为7:3。
作者发现将UltraChat数据预打包到训练序列长度至关重要,而且需要与自定义的QA数据示例分开。
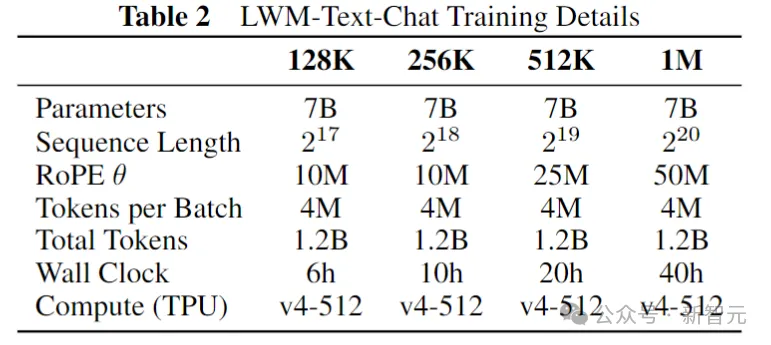
聊天模型并没有采用渐进式训练,而是从各自的预训练模型以相同的上下文长度进行初始化。
第二阶段旨在有效地联合训练长视频和语言序列。
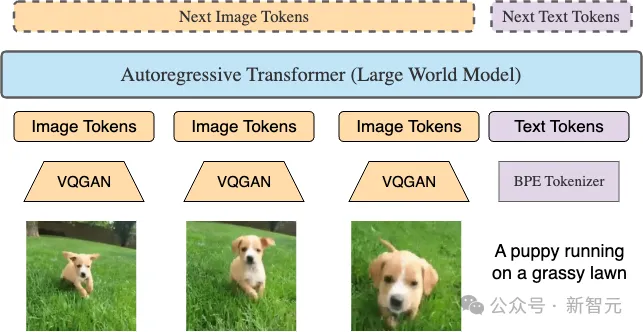
LWM是数百万长标记序列上的自回归变换器。视频中的每一帧都用VQGAN产生256个token。这些token与文本token连接起来,馈送到Transformer中,以自回归方式预测下一个token。
输入和输出token的顺序反映了不同的训练数据格式,包括图像-文本、文本-图像、视频、文本-视频和纯文本格式。
LWM本质上是使用多种模式以任意到任意方式进行训练的。为了区分图像和文本token,以及进行解码,这里采用特殊的分隔符。在视觉数据中,也会处理视频的中间帧和最终帧。
这里使用来自aMUSEd的预训练VQGAN,将256 × 256个输入图像标记为16 × 16个离散token。
模型使用视觉和文本token的交错串联进行训练,并进行自回归预测。
以LWM-Text-1M文本模型为初始化,对大量组合的文本-图像和文本-视频数据执行渐进式训练过程,这里没有额外扩展RoPE θ,因为它已经支持高达1M的上下文。
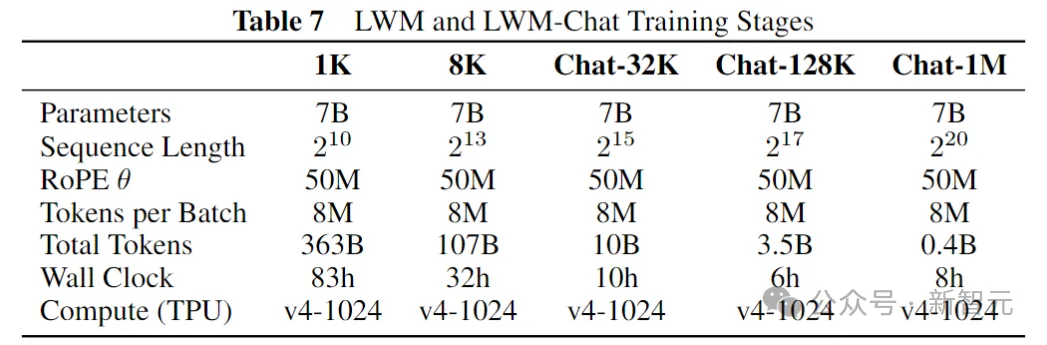
上表显示了每个训练阶段的详细信息,每个模型是从先前较短的序列长度阶段初始化的。
对于每个阶段,根据以下数据进行训练:
LWM-1K:在大型文本图像数据集上进行训练,该数据集由LAION-2Ben和COYO-700M混合组成。数据集被过滤后仅包含至少256分辨率的图像——总共大约1B个文本图像对。
在训练过程中,将文本-图像对连接起来,并随机交换模态的顺序,以对文本-图像生成、无条件图像生成和图像标题进行建模。这里将文本-图像对打包为1K个token的序列。
LWM-8K:在WebVid10M和3M InternVid10M示例的文本视频数据集组合上进行训练。与之前的工作类似,每种模态使用相同的比例联合训练图像和视频。
这里将图像打包成8K token序列和30帧视频,速度为4FPS。与图像训练类似,随机交换每个文本-视频对的模态顺序。
LWM-Chat-32K/128K/1M:在最后3个阶段,研究人员对每个下游任务的聊天数据组合进行训练:
文本图像生成
图像理解
文本视频生成
视频理解
通过对预训练数据的随机子集进行采样,并用聊天格式进行增强,构建了文本-图像和文本-视频聊天数据的简单版本。为了理解图像,这里使用来自ShareGPT4V的图像聊天指示。
最后,对于视频理解聊天数据,使用Valley-Instruct-73K和Video-ChatGPT-100K指令数据的组合。对于所有短上下文数据(图像生成、图像理解、视频生成),将序列打包到训练上下文长度。
在打包过程中,研究人员发现关键是要掩盖注意力,以便每个文本视觉对只关注自己,以及重新加权损失,以使计算与非打包+填充训练方案中的训练相同。
对于视频理解数据,如果视频太长,会统一采样最大帧数,以适应模型的训练上下文长度。在训练期间,4 个下游任务等比例平均分配。
尽管视觉语言模型可以摄取长视频,但由于上下文长度有限,通常是通过对视频帧执行大型时间子采样来完成的。
例如,Video-LLaVA被限制为从视频中均匀采样8帧,无论原始视频有多长。因此,模型可能会丢失更细粒度的时间信息,而这些信息对于准确回答有关视频的任何问题非常重要。

相比之下,本文的模型是在1M令牌的长序列上训练的,因此,可以同时处理数千帧视频,以在短时间间隔内检索细粒度信息。在上图的示例中,LWM正确回答了有关由500多个独立剪辑组成的1小时长YouTube视频的问题。
不过作者也承认,LWM生成的答案可能并不总是准确的,并且该模型仍在努力解决需要对视频有更高层次理解的更复杂的问题。希望LWM将有助于未来的工作,开发改进的基础模型,以及长视频理解的基准。
参考资料:
https://largeworldmodel.github.io/
文章来自微信公众号“新智元”,作者:新智元



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
