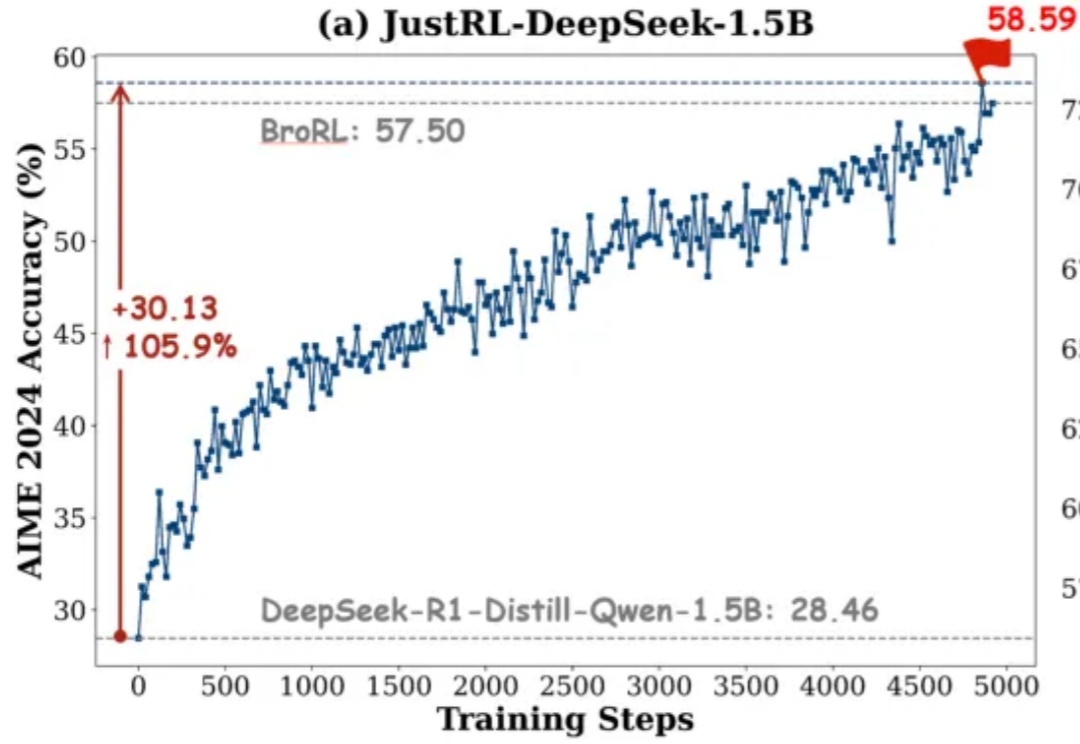
清华团队:1.5B 模型新基线!用「最笨」的 RL 配方达到顶尖性能
清华团队:1.5B 模型新基线!用「最笨」的 RL 配方达到顶尖性能如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗?
来自主题: AI技术研报
7269 点击 2025-11-13 09:37
 搜索
搜索
如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗?

AI To B 突围的新解法就在非共识里。
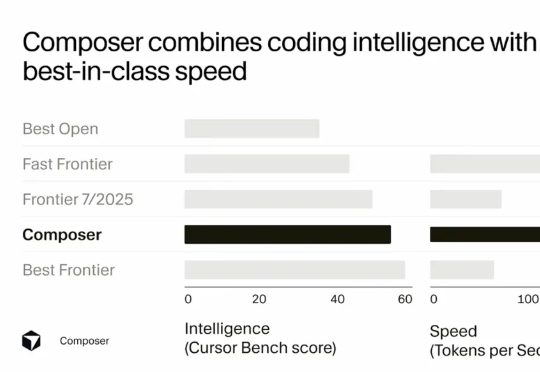
Sasha Rush 在分享开头就提到,Cursor Composer 在他们的内部 benchmark 上的表现几乎与最好的 Frontier 模型(前沿模型)持平,并且优于去年夏天发布的所有模型。它的表现明显好于最好的开源模型,以及那些被标榜为"快速"的模型。
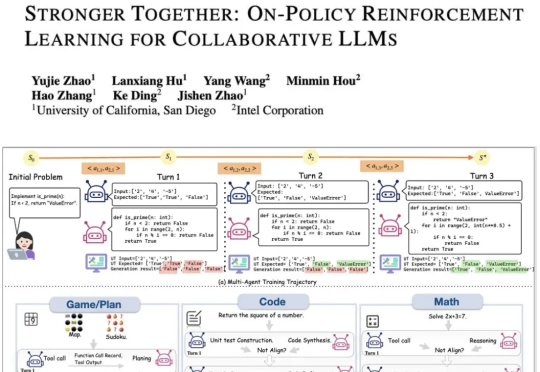
现有的LLM智能体训练框架都是针对单智能体的,多智能体的“群体强化”仍是一个亟须解决的问题。为了解决这一领域的研究痛点,来自UCSD和英特尔的研究人员,提出了新的提出通用化多智能体强化学习框架——PettingLLMs。支持任意组合的多个LLM一起训练。
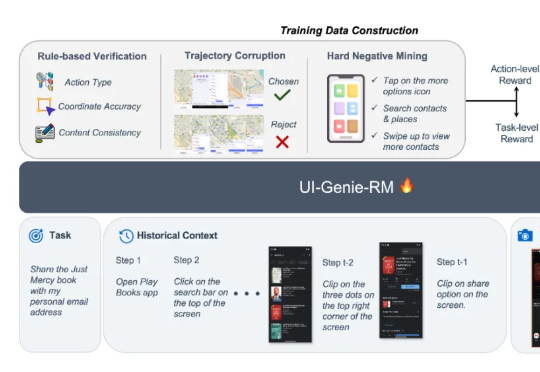
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le
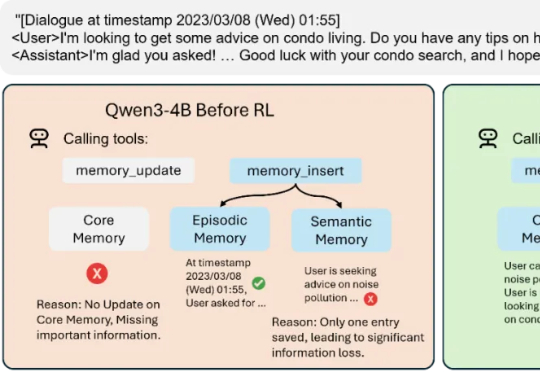
Mem-α 的出现,正是为了解决这一困境。由加州大学圣地亚哥分校的 Yu Wang 在 Anuttacon 实习期间完成,这项工作是首次将强化学习引入大模型的记忆管理体系,让模型能够自主学习如何使用工具去存储、更新和组织记忆。

过去两年,AI靠模仿人类席卷世界。但强化学习之父Richard Sutton却说:「GenAI的时代正在结束。」他带着图灵奖的荣光,加入一家几乎没人听过的公司——ExperienceFlow.AI,他要让AI不靠人类数据喂养,而靠「经验」觉醒。
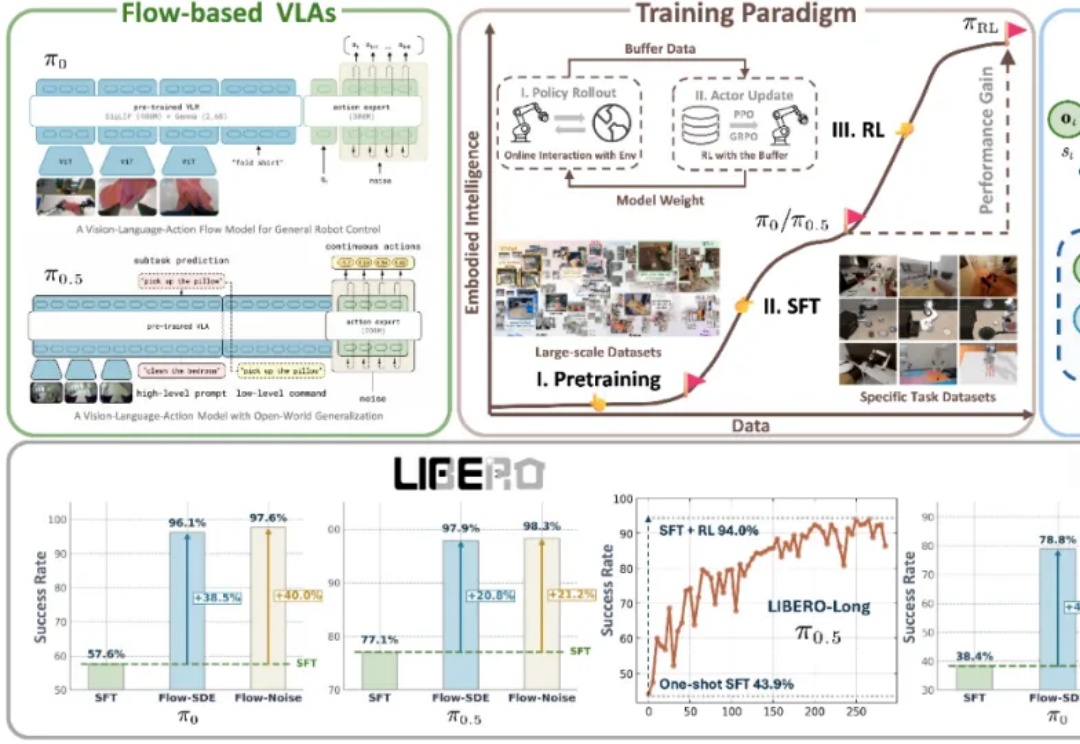
近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。
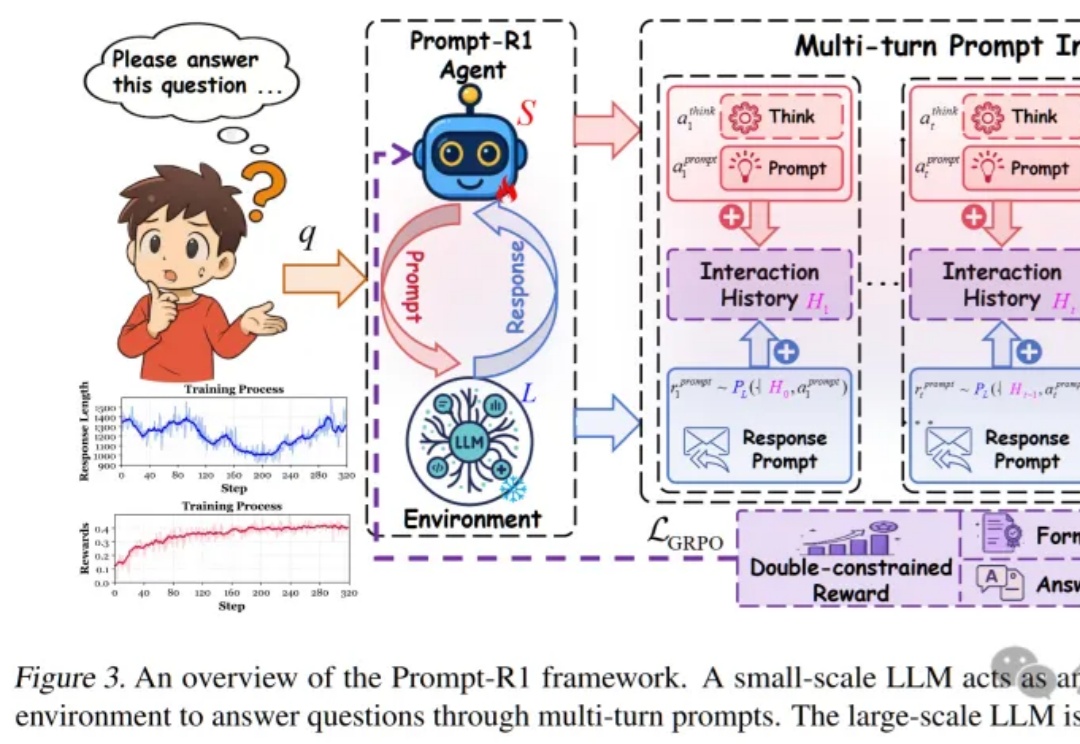
这篇论文提出了一种颠覆性的协作模式,即通过强化学习训练一个“小模型”作为智能代理(Agent),让它自动学会如何写出完美的Prompt,一步步引导任何一个“大模型”完成复杂推理,实现了真正的“AI指挥AI”。

传统智能体系统难以兼顾稳定性和学习能力,斯坦福等学者提出AgentFlow框架,通过模块化和实时强化学习,在推理中持续优化策略,并使小规模模型在多项任务中超越GPT-4o,为AI发展开辟新思路。