
更像人脑的新型注意力机制,Meta让大模型自动屏蔽任务无关信息,准确率提高27%
更像人脑的新型注意力机制,Meta让大模型自动屏蔽任务无关信息,准确率提高27%关于大模型注意力机制,Meta又有了一项新研究。通过调整模型注意力,屏蔽无关信息的干扰,新的机制让大模型准确率进一步提升。而且这种机制不需要微调或训练,只靠Prompt就能让大模型的准确率上升27%。
来自主题: AI资讯
6814 点击 2023-11-27 17:14
关于大模型注意力机制,Meta又有了一项新研究。通过调整模型注意力,屏蔽无关信息的干扰,新的机制让大模型准确率进一步提升。而且这种机制不需要微调或训练,只靠Prompt就能让大模型的准确率上升27%。

我们都知道,大语言模型(LLM)能够以一种无需模型微调的方式从少量示例中学习,这种方式被称为「上下文学习」(In-context Learning)。这种上下文学习现象目前只能在大模型上观察到。比如 GPT-4、Llama 等大模型在非常多的领域中都表现出了杰出的性能,但还是有很多场景受限于资源或者实时性要求较高,无法使用大模型。

用视觉来做Prompt!沈向洋展示IDEA研究院新模型,无需训练或微调,开箱即用

有一家公司,OpenAI、Anthropic、Cohere、Aleph Alpha(欧洲顶尖大模型公司)和Hugging Face的模型训练和微调都离不开它,NVIDIA和谷歌云(GCP)都是它的深度合作伙伴,它是支持生成式AI明星公司们训练模型的幕后英雄。
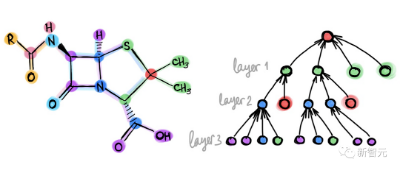
GraphGPT框架将图结构模型和大语言模型进行参数对齐,利用双阶段图指令微调范式提高模型对图结构的理解能力和适应性,再整合ChatGPT提高逐步推理能力,实现了更快的推理速度和更高的图任务预测准确率。

大型语言模型能力惊人,但在部署过程中往往由于规模而消耗巨大的成本。华盛顿大学联合谷歌云计算人工智能研究院、谷歌研究院针对该问题进行了进一步解决,提出了逐步微调(Distilling Step-by-Step)的方法帮助模型训练。
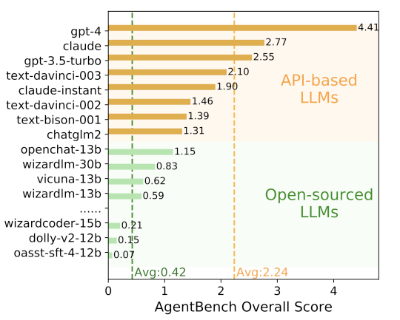
智谱AI&清华KEG提出了一种对齐 Agent 能力的微调方法 AgentTuning,该方法使用少量数据微调已有模型,显著激发了模型的 Agent能力,同时可以保持模型原有的通用能力。

微调LLM需谨慎,用良性数据、微调后角色扮演等都会破坏LLM对齐性能!学习调大了还会继续提高风险!

悄无声息,羊驼家族“最强版”来了! 与GPT-4持平,上下文长度达3.2万token的LLaMA 2 Long,正式登场。
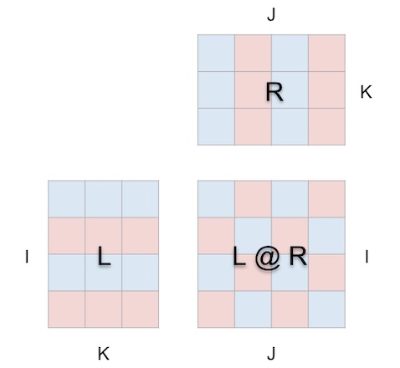
矩阵乘法已经成为机器学习模型的构建模块,是各种强大 AI 技术的基础,了解其执行方式必然有助于我们更深入地理解这个 AI 以及这个日趋智能化的世界。