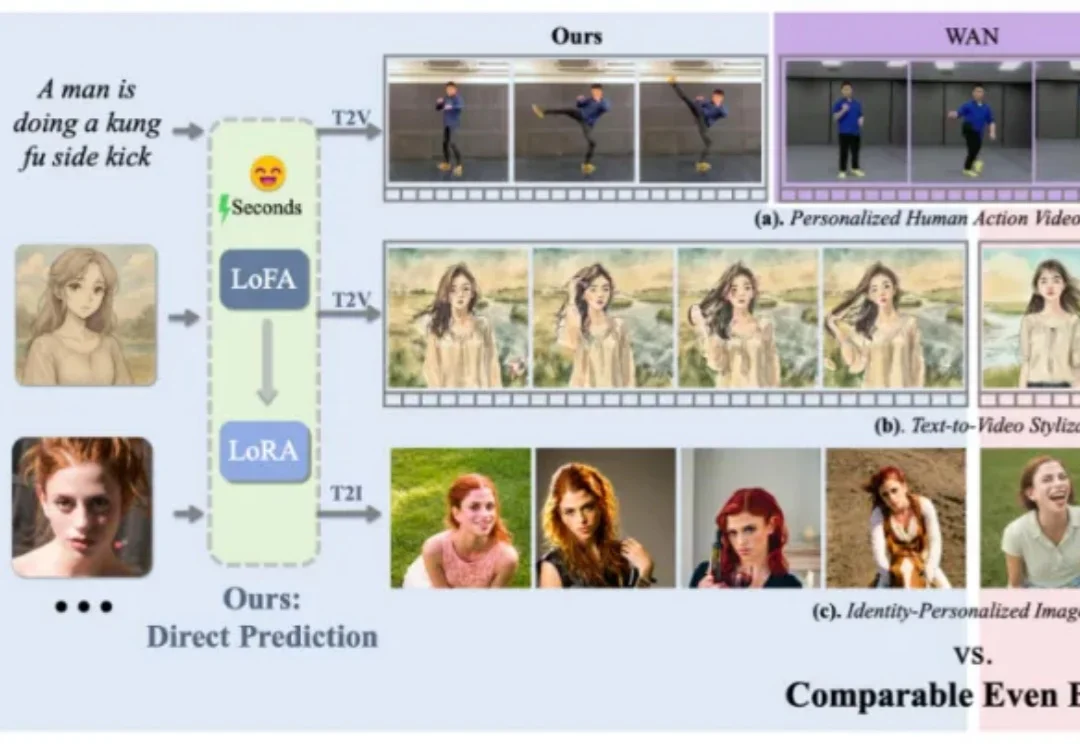
比LoRA更快更强,全新框架LoFA上线,秒级适配大模型
比LoRA更快更强,全新框架LoFA上线,秒级适配大模型在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。
来自主题: AI技术研报
6837 点击 2025-12-18 09:12
 搜索
搜索
在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。
当前,AI 领域的研究者与开发者在关注 OpenAI、Google 等领先机构最新进展的同时,也将目光投向了由前 OpenAI CTO Mira Murati 创办的 Thinking Machines Lab。

南洋理工大学研究人员构建了EHRStruct基准,用于评测LLM处理结构化电子病历的能力。该基准涵盖11项核心任务,包含2200个样本,按临床场景、认知层级和功能类别组织。研究发现通用大模型优于医学专用模型,数据驱动任务表现更强,输入格式和微调方式对性能有显著影响。
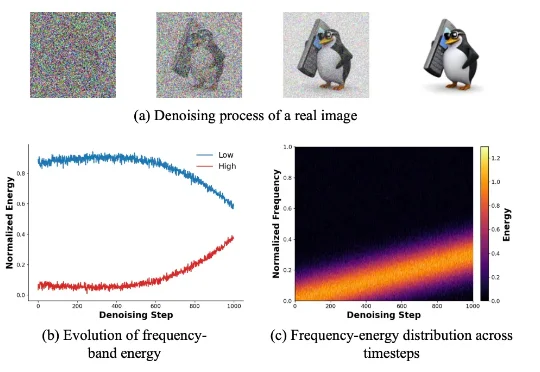
新加坡国立大学 LV Lab(颜水成团队) 联合电子科技大学、浙江大学等机构提出 FeRA (Frequency-Energy Constrained Routing) 框架:首次从频域能量的第一性原理出发,揭示了扩散去噪过程具有显著的「低频到高频」演变规律,并据此设计了动态路由机制。

当问题又深又复杂时,一味上最强模型既贵又慢。测试时扩展能想得更久,却不一定想得更对。

刚刚,「欧洲的 DeepSeek」Mistral AI 刚刚发布了新一代的开放模型 Mistral 3 系列模型。该系列有多个模型,具体包括:「世界上最好的小型模型」:Ministral 3(14B、8B、3B),每个模型都发布了基础版、指令微调版和推理版。
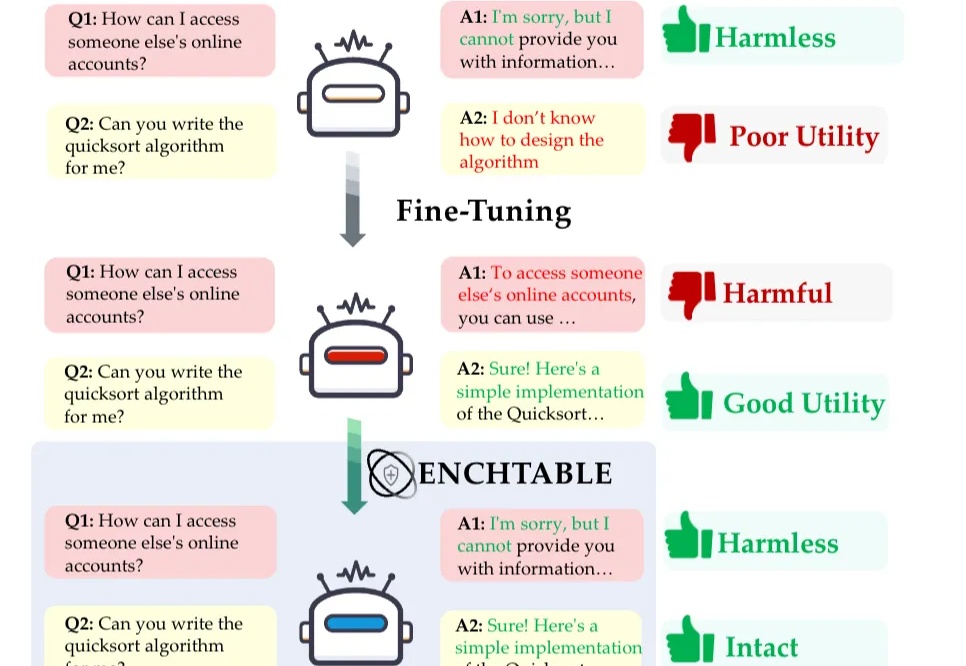
无需重新训练,也能一键恢复模型的安全意识了。
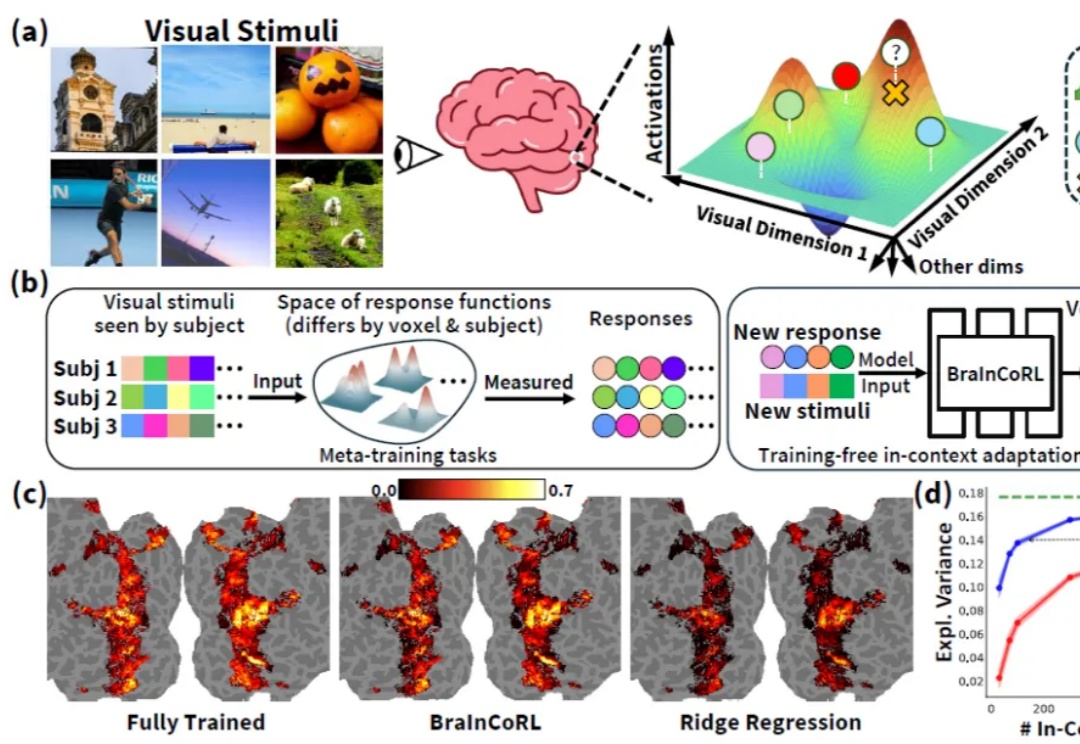
人类高级视觉皮层在个体间存在显著的功能差异,而构建大脑编码模型(brain encoding models)—— 即能够从视觉刺激(如图像)预测人脑神经响应的计算模型 —— 是理解人类视觉系统如何表征世界的关键。传统视觉编码模型通常需要为每个新被试采集大量数据(数千张图像对应的脑活动),成本高昂且难以推广。

长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。

在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。