
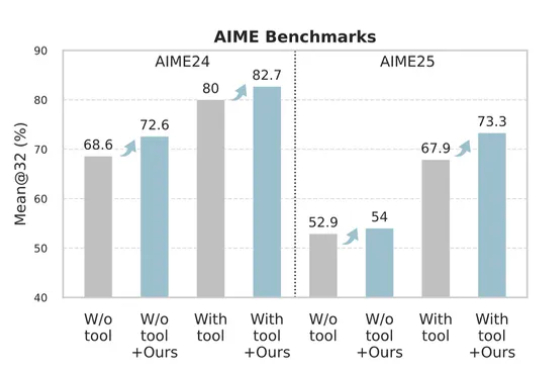
腾讯发布超低成本AI训练法!120元效果秒杀70000元微调方案
腾讯发布超低成本AI训练法!120元效果秒杀70000元微调方案只花120元,效果吊打70000元微调!腾讯提出一种升级大模型智能体的新方法——无训练组相对策略优化Training-Free GRPO。无需调整任何参数,只要在提示词中学习简短经验,即可实现高性价比提升模型性能。
来自主题: AI技术研报
10382 点击 2025-10-15 17:06
只花120元,效果吊打70000元微调!腾讯提出一种升级大模型智能体的新方法——无训练组相对策略优化Training-Free GRPO。无需调整任何参数,只要在提示词中学习简短经验,即可实现高性价比提升模型性能。
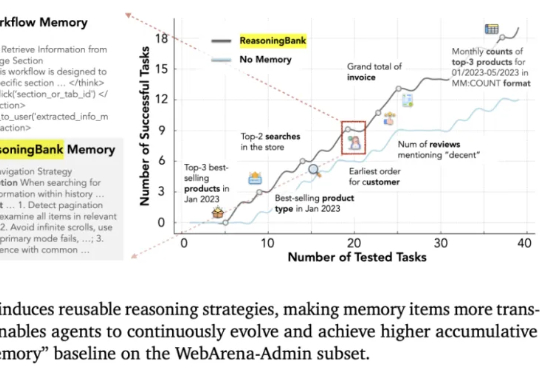
这几天,关于「微调已死」的言论吸引了学术圈的广泛关注。一篇来自斯坦福大学、SambaNova、UC 伯克利的论文提出了一种名为 Agentic Context Engineering(智能体 / 主动式上下文工程)的技术,让语言模型无需微调也能实现自我提升!

在具身智能领域,视觉 - 语言 - 动作(VLA)大模型正展现出巨大潜力,但仍面临一个关键挑战:当前主流的有监督微调(SFT)训练方式,往往让模型在遇到新环境或任务时容易出错,难以真正做到类人般的泛化

既然后训练这么重要,那么作为初学者,应该掌握哪些知识?大家不妨看看这篇博客《Post-training 101》,可以很好的入门 LLM 后训练相关知识。从对下一个 token 预测过渡到指令跟随; 监督微调(SFT) 基本原理,包括数据集构建与损失函数设计;
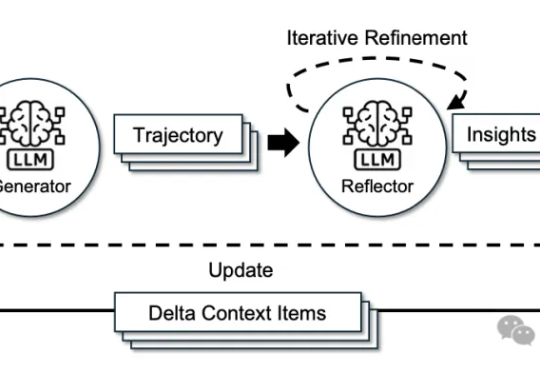
来自斯坦福大学、SambaNova Systems公司和加州大学伯克利分校的研究人员,在新论文中证明:依靠上下文工程,无需调整任何权重,模型也能不断变聪明。他们提出的方法名为智能体上下文工程ACE。
Thinking Machines Lab发布首个产品:Thinker,让模型微调变得像改Python代码一样简单。也算是终于摘掉了“0产品0收入估值840亿”的帽子。Tinker受到了业界的密切关注。AI基础设施公司Anyscale的CEO Robert Nishihara等beta测试者表示,尽管市面上有其他微调工具,但Tinker在“抽象化和可调性之间取得了卓越的平衡”

LoRA能否与全参微调性能相当?在Thinking Machines的最新论文中,他们研究了LoRA与FullFT达到相近表现的条件。Thinking Machines关注LoRA,旨在推动其更广泛地应用于各种按需定制的场景,同时也有助于我们更深入审视机器学习中的一些基本问题。

为破解机器人产业「一机一调」的开发困境,智源研究院开源了通用「小脑基座」RoboBrain-X0。它创新地学习任务「做什么」而非「怎么动」,让一个预训练模型无需微调,即可驱动多种不同构造的真实机器人,真正实现了零样本跨本体泛化。

我想聊个反向操作:咱们普通人,如何用有限的资源,轻松驯服一个 AI 模型,让它变成我们专属的垂直领域小能手?主角,就是最近华为刚刚开源的一个大小仅为 1B 的模型 openPangu-Embedded-1B,它不仅全面领先同规格模型,甚至与更大规模的 Qwen3-1.7B 也难分伯仲。

打破思维惯性,「小模型」也能安全又强大!北大-360联合实验室发布TinyR1-32B模型,以仅20k数据的微调,实现了安全性能的里程碑式突破,并兼顾出色的推理与通用能力。