# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。
通常来说,这些方法在训练模型时可以产生比典型正确解决方案更长的轨迹,并包含了试图实现某些「算法」的 token:
例如反思前一个答案、规划或实现某种形式的线性搜索。
这些方法包括显式地微调预训练 LLM 以适应算法行为,例如对搜索数据进行监督微调(SFT)或针对 0/1 正确性奖励运行结果奖励(outcome-reward,OR)RL。
虽然通过「结果奖励 RL 生成长推理链」的方式来训练模型消耗测试时计算的前景看好,但为了继续从扩展测试时计算中获得收益,
我们最终需要回答一些关键的理解和方法设计问题。
第一个问题:当前的 LLM 是否高效使用了测试时间计算?也就是说,它们是否消耗了与典型解决方案长度大致相当的 token,
或者它们是否在简单的问题上使用了太多 token?
第二个问题:当运行测试时 token 预算远大于用于训练的 token 预算时,LLM 是否能够「发现」用于更难问题的解决方案?
最终,我们希望模型能够从它们生成的每个 token(或任何语义上有意义的片段)中获得足够的效用,
这不仅是为了提高效率,还因为这样做可以形成一个系统化的流程来发现更难、分布外问题的解决方案。
在本文中,CMU、HuggingFace 的研究者提出从元强化学习(RL)的视角来形式化上述优化测试时计算的挑战。

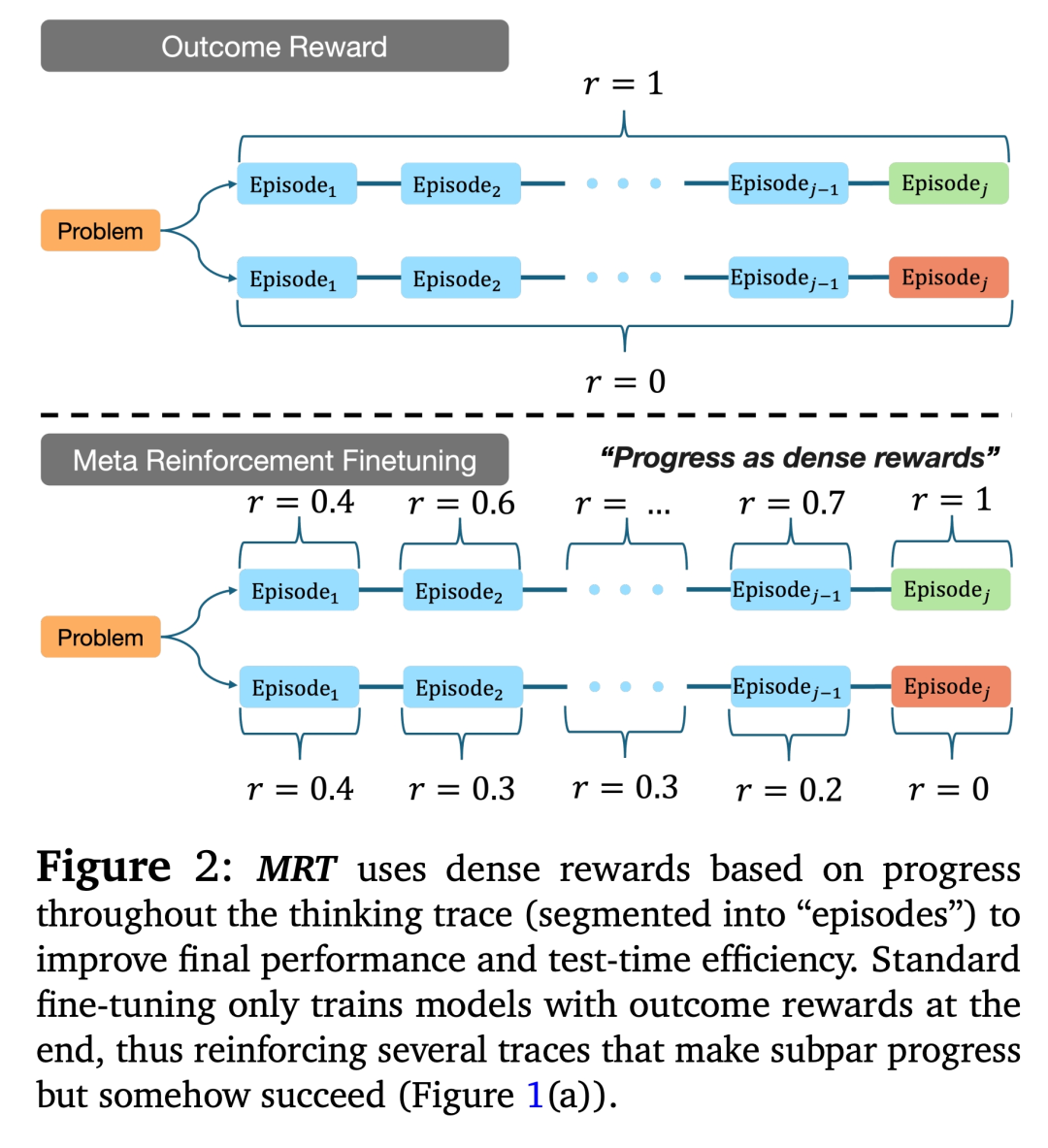
在构建方法的过程中,研究者在给定问题上将 LLM 的输出流分割成多个片段(图 2)。
如果我们只关心效率,那么 LLM 应该只学习利用并直接输出最终答案,而无需耗费太多片段。
另一方面,如果 LLM 仅专注于发现(discovery),那么探索就更可取,这样 LLM 就可以耗费几个片段来尝试不同的方法,
并进行验证和修改,然后得出最终答案。
从根本上说,这与传统的 RL 不同,这里的目标是学习一个可以在每个测试问题上实现探索 - 利用算法的 LLM。
换句话说,本文的目标是从训练数据中学习这样的算法,使其成为一个「元」RL 学习问题。
理想的「元」行为是在过早采用一种方法(即「利用」片段)和尝试过多高风险策略(即「探索」片段)之间取得平衡的行为。
从元 RL 文献中,我们知道探索和利用的最佳权衡相当于最小化输出 token 预算的累积悔值。
这种悔值衡量了 LLM 与一个 oracle 比较器成功可能性之间的累积差异,如图 1 (b) 中的红色阴影区域所示。
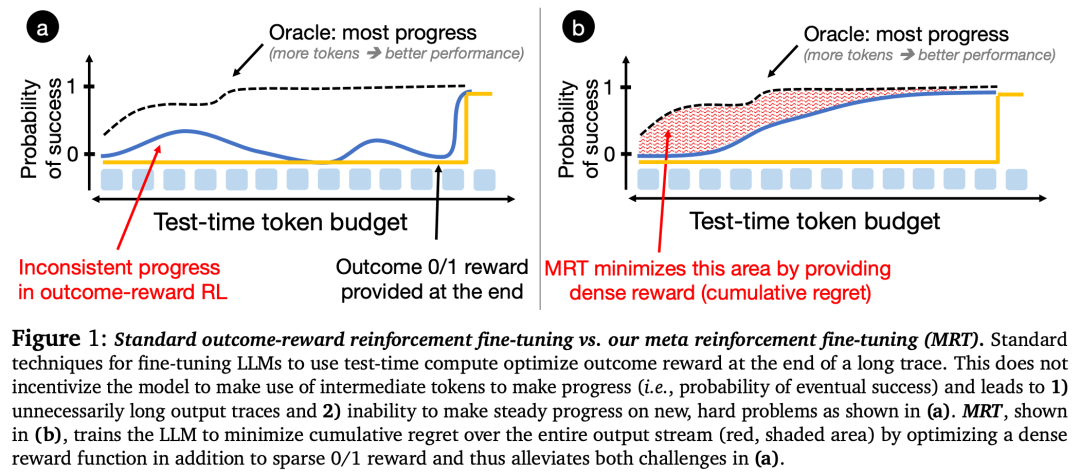
通过训练 LLM 来最小化每个查询的累积悔值,本文学习了一种在某种程度上与测试时预算无关的策略,
即在部署时 LLM 仅耗费必要数量的 token,同时在更大的 token 预算下运行时仍会取得进展。
具体地,研究者利用一类新的微调方法来优化测试时计算,通过最小化累积悔值的概念产生了一种被称为元强化微调
(Meta Reinforcement Fine-Tuning,MRT)的解决方案(或范式),从而为评估现有推理模型(如 Deepseek-R1)在使用测试时计算的有效性提供了一个指标。
研究者发现,使用结果奖励 RL 进行微调的 SOTA LLM 无法通过更多片段来提高发现正确答案的概率,即它们没有取得稳定的「进展」(如上图 1 (a) 所示),
即使这种行为对于发现未见过难题的解决方案至关重要。
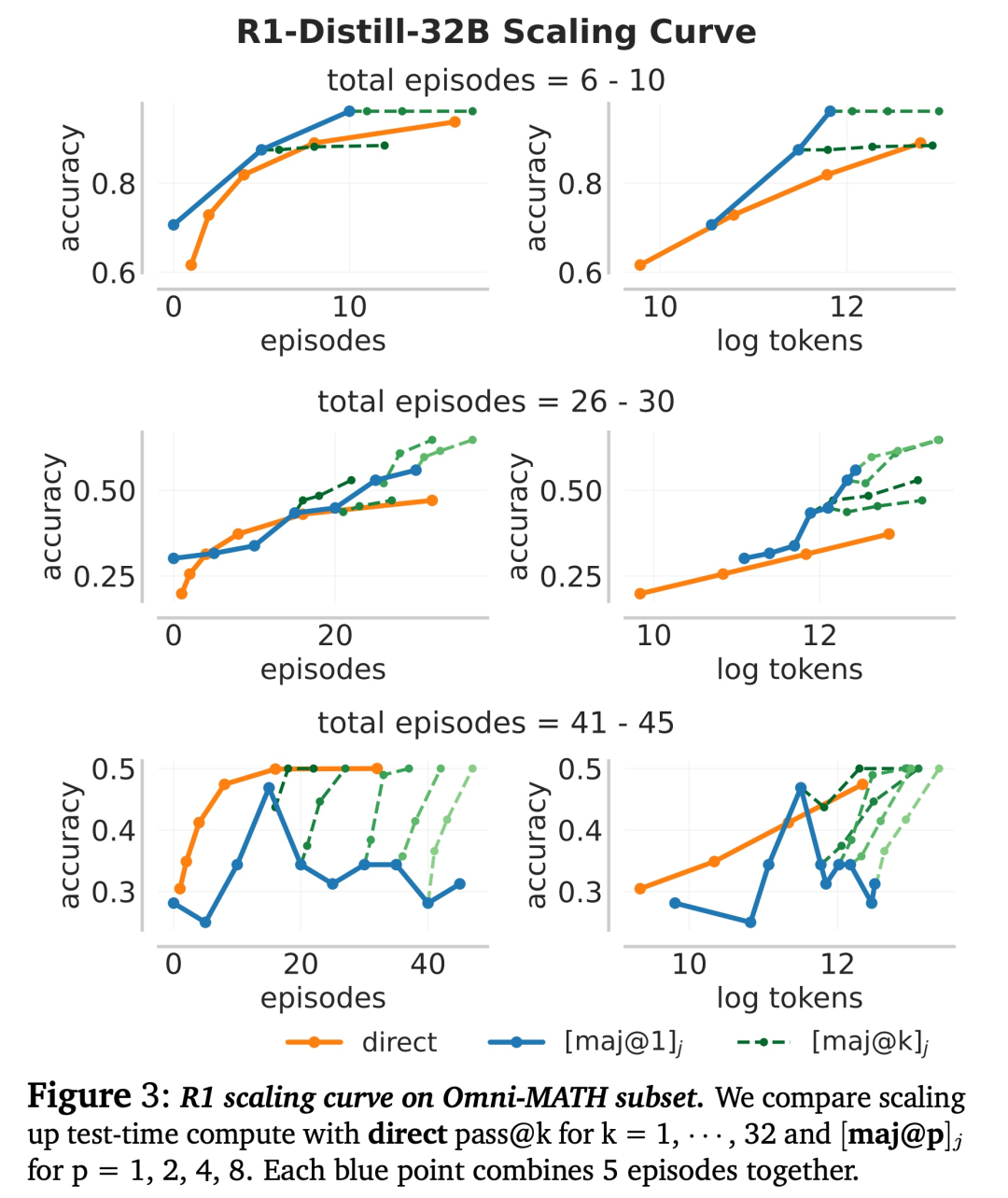
事实上,在 FLOPs 匹配的评估中,运行更少片段并结合多数投票的更简单方法通常对较难的问题更有效(下图 3)。
相反,研究者表明,当目标是最小化悔值时,除了结果奖励之外,对进展的优化也会自然而然出现。
本文的微调范式 MRT 为 RL 训练规定了密集的奖励(reward bonus)。直观地说,这一进展奖励衡量了在生成给定片段之前和之后获得正确答案的似然的变化。
在实验部分,研究者在两种设置下对 MRT 进行了评估,二者的不同之处在于它们对片段进行参数化的方式。
对于第一种设置,他们对基础模型进行微调,包括 DeepScaleR-1.5B-Preview、DeepSeek-R1-Distill-Qwen-1.5B 和 DeepSeekR1-Distill-Qwen-7B,
并采用了数学推理问题数据集。
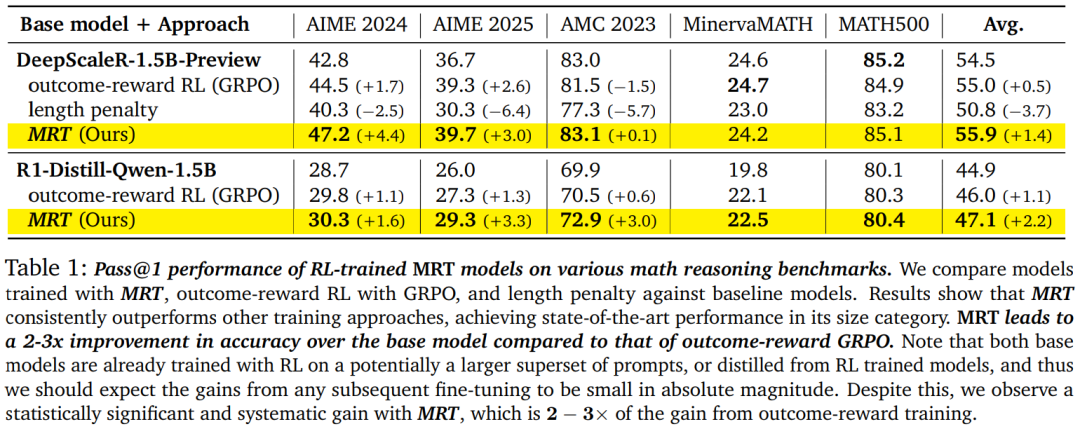
结果发现,MRT 的表现始终优于结果奖励强化学习,在多个基准测试(AIME 2024、AIME 2025、AMC 2023 等)上取得了 15 亿参数规模的 SOTA 结果,
其相较于基础模型的准确率提升是标准结果奖励 RL(GRPO)的约 2-3 倍,而 token 效率是 GRPO 的 1.5 倍、是基础模型的 5 倍。
GRPO 是 DeepSeek-R1 的关键强化学习算法。
对于第二种设置,研究者对 Llama 3.1 进行微调以实现回溯,结果表明,MRT 相较于 STaR 和 GRPO 均实现了 1.6-1.7 倍的 token 效率提升。
MRT 的目标是直接学习一种与预算无关(budget-agnostic)的 LLM,使其能够稳步取得进展。
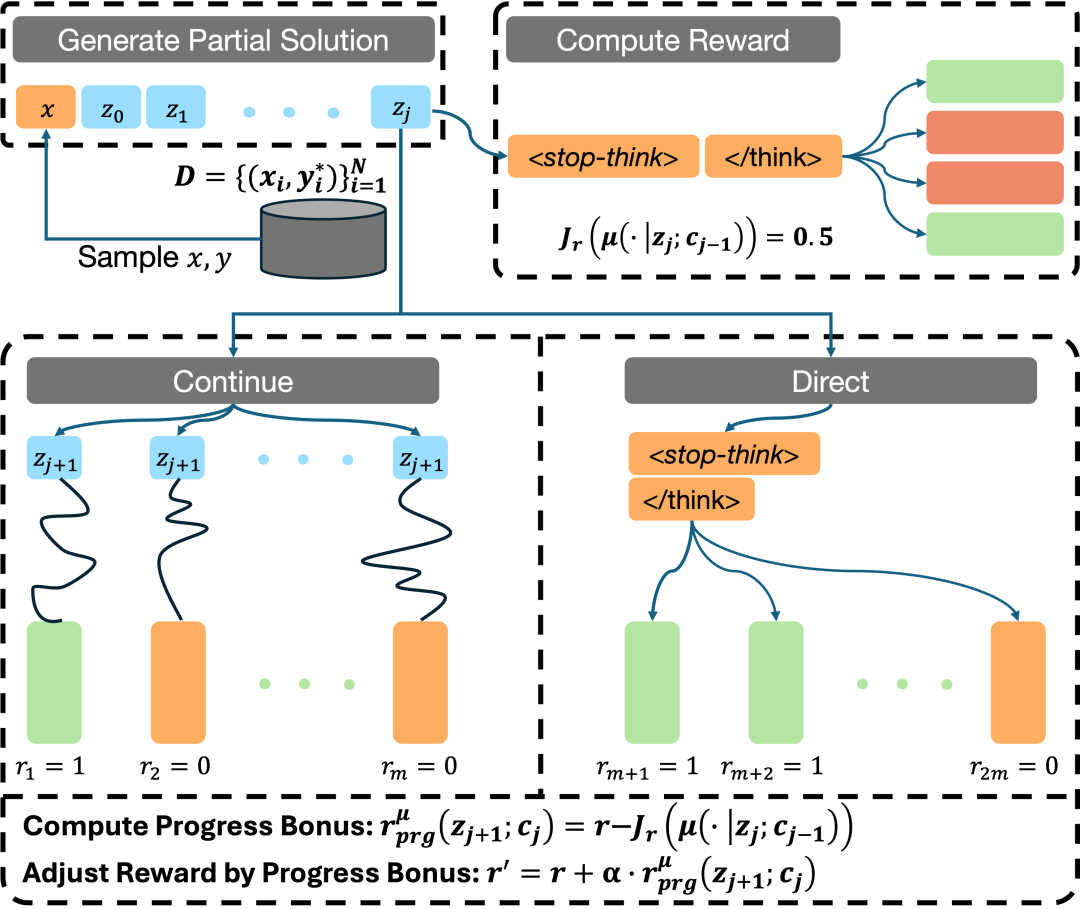
该研究使用在线强化学习方法(如 GRPO)实现元强化学习范式。下面是它的工作原理:
该研究定义了一个元证明器策略(Meta-Prover Policy)μ,用于评估一个片段对解决问题的贡献程度。该策略的工作方式如下:
对于推理过程中的每一个片段,需要这样操作:
在训练过程中,该研究优化了包含标准结果奖励和基于进展的密集奖励奖励的 MRT 目标函数:
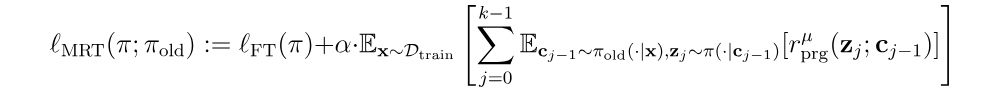
实验结果
实验评估了 MRT 在优化「测试时计算」资源方面的有效性。
如表 1 所示,MRT 的表现优于在相同数据集上未使用密集奖励训练的模型。
此外,该研究还得出了以下结论:
由于模型在经过蒸馏或已经经过强化学习(RL)训练的基础模型上进行了训练,因此绝对性能提升较小。
然而,与基于结果奖励的 RL 方法(如 GRPO)相比,使用 MRT 的相对性能提升约为 2-3 倍。
(这或许在意料之中),而且在相对于结果奖励强化学习(RL)分布外的 AMC 2023 数据集上也保持了较好的性能。
MRT 对 token 的处理效率
前文我们已经看到 MRT 可以在 pass@1 准确率上超越标准的结果奖励强化学习(RL)。接下来,作者尝试评估 MRT(RL)在 token 效率上是否可以带来提升。
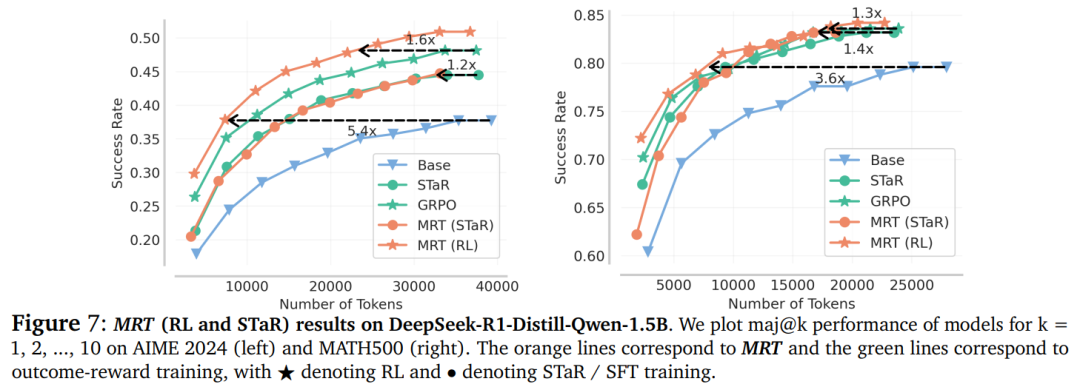
如图 7 所示,MRT 在 AIME 2024 数据集上,在相同 token 数量的情况下,平均准确率比基础模型高出 5%。
此外,MRT(RL)在 AIME 2024 上所需的 token 数量比基础模型少 5 倍,在 MATH 500 上少 4 倍,就能达到相同的性能
(本例中使用的是 DeepSeek-R1 蒸馏的 Qwen-1.5B 模型)。
同样地,MRT 在 token 效率上比结果奖励 RL 提高了 1.2-1.6 倍。这些结果表明,MRT 在保持或提升准确率的同时,显著提高了 token 效率。
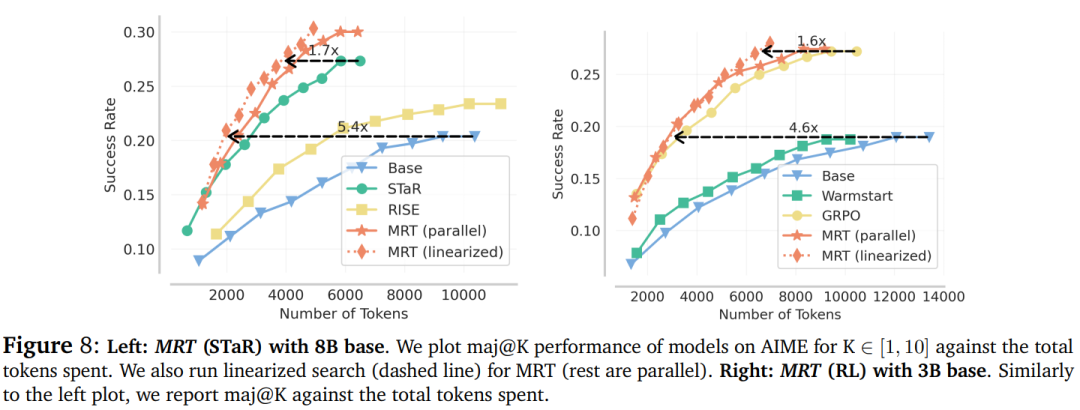
回溯搜索设置中的线性化评估
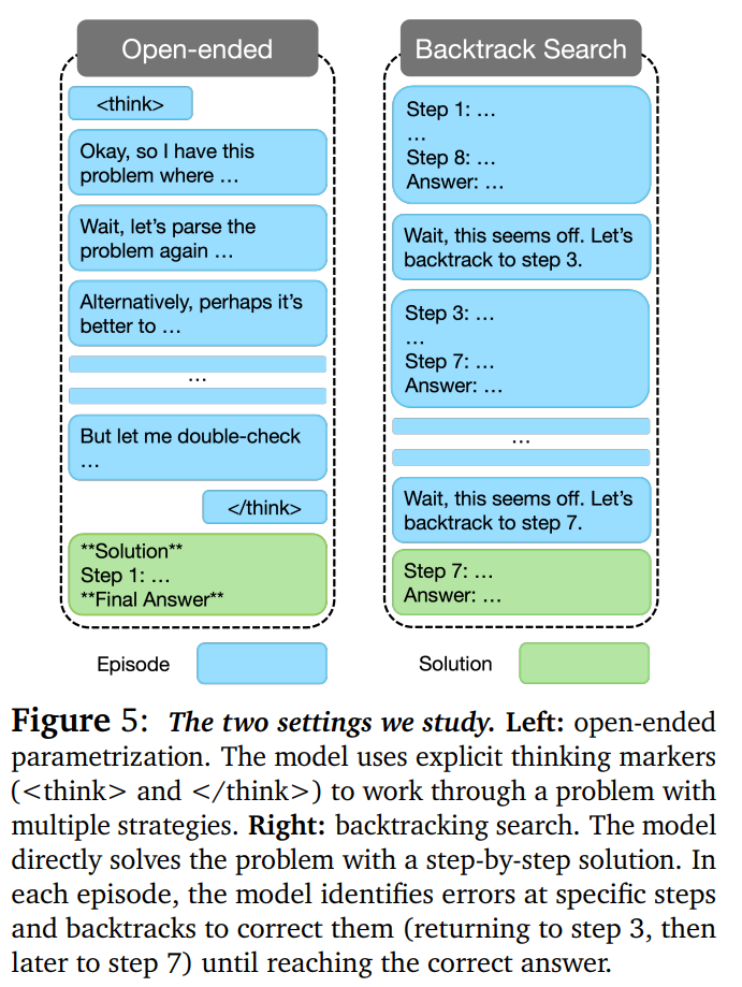
在这种设置中,模型被限制为先生成一个解决方案,接着进行错误检测,最后在进行修正(如图 5 所示)。
该研究首先对基于 Llama-3.1-8B 模型微调的 MRT 的 STaR 变体进行评估。
如图 8(左)所示,MRT 在两种评估模式下(并行模式为实线;线性化模式为虚线)均实现了最高的测试效率,并在线性化评估模式下将效率提高了 30% 以上。
图 8(右)显示,与结果奖励 GRPO 相比,MRT(RL)通过减少 1.6 倍的 token 来提升线性化效率。
文章来自于微信公众号 “机器之心”,作者 :杜伟、陈陈




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
