
买AI要付两次钱?微软CEO纳德拉:这是一笔比Token更贵的账
买AI要付两次钱?微软CEO纳德拉:这是一笔比Token更贵的账“购买使用AI时,钱可能要付两遍!”
来自主题: AI资讯
6314 点击 2026-07-14 15:26
 搜索
搜索
“购买使用AI时,钱可能要付两遍!”

微软Copilot & Agents Core总裁Nitin Agrawal说,「迫不及待想让客户看到GPT-5.6能做什么」——不管是起草文档、分析数据、做演示,还是跨团队协作,产出都会更精致。除了原生接入模型,微软还会直接通过OpenAI API调用GPT-5.6,服务Microsoft 365客户。双通道,齐上阵。
2023 年大模型刚火的时候,浏览器被认为是 AI 时代最值得抢的入口,用AI颠覆Chrome是大家都能看到的百亿创业项目。实在是这个入口太大了。全球互联网用户已经是 60 亿量级,Chrome 一个产品就是三十亿级用户;Safari 靠 iPhone、iPad 和 Mac 占住十亿级设备入口,Edge 背后是 Windows 和微软账号体系。

Jay 发自 凹非寺 量子位 | 公众号 QbitAI AI能否真正产生价值?组织因素的权重是个人的两倍。 也就是说,你AI用得不好,三分之二的锅得公司背。 这个反直觉洞察,出自微软一年一度的《Wor
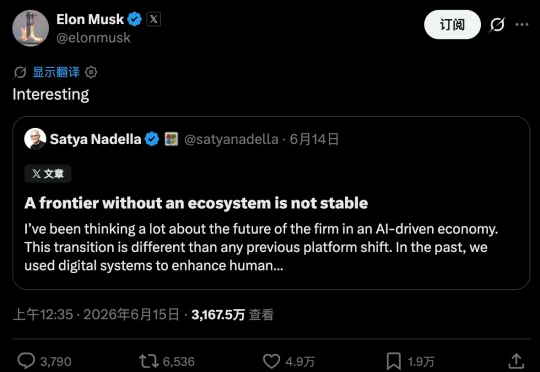
微软CEO 萨蒂亚·纳德拉,上周发的那篇《没有生态的前沿,立不住》(A frontier without an ecosystem is not stable),是近期挺有意思的一篇文章。不在于它提出了多少新概念,里面的很多要点,在近一年里大多已有讨论,而在于说它的不是旁观者,而是亲手运营着庞大 AI 基础设施的人,并且纳德拉用很朴素的语言,把两件非常重要的事情讲清楚了:

写代码、跑实验、改项目、迭代方案,现在的AI智能体样样都能搞定。

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?

好你个微软,当起大模型“倒爷”来了?!
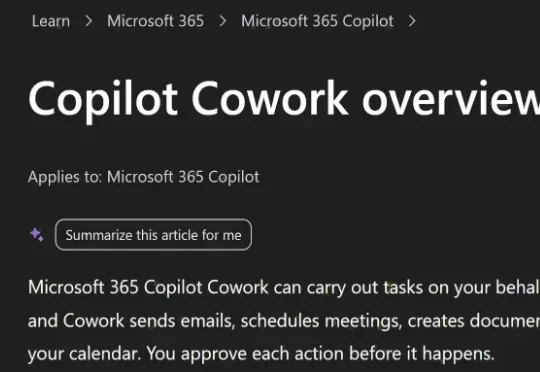
当地时间6月16日,微软宣布将企业AI工具Copilot Cowork转向按使用量计费。另据外媒Axios报道,在扩大该工具访问范围的同时,Copilot Cowork近期考虑引入由微软托管的DeepSeek模型,作为更低成本的模型选项。

昨天晚上,微软 CEO 萨蒂亚·纳德拉(Satya Nadella)在 𝕏 上发布了一篇长推文《A frontier without an ecosystem is not stable》,即「没有生态系统的前沿是不稳定的」。