
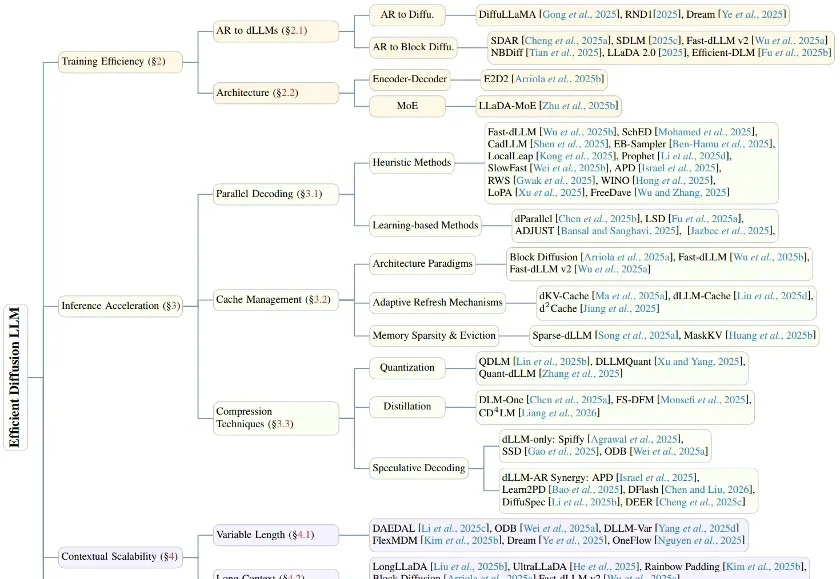
从训练到推理的「瘦身」演进:首篇高效扩散语言模型(dLLM)深度综述
从训练到推理的「瘦身」演进:首篇高效扩散语言模型(dLLM)深度综述在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
来自主题: AI技术研报
6486 点击 2026-03-10 14:29
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。

在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。

自扩散模型提出以来,它不仅在图像、视频和音频生成方面取得了优异效果,也正逐渐成为解决图像复原、超分辨率、去模糊等逆问题的重要工具。
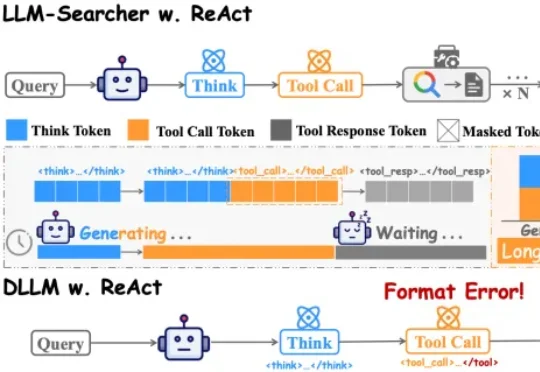
中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:

香港科技大学 & 北航 & 商汤等提出了一个专门面向视频生成扩散模型的 QAT 范式 ——QVGen,在 3-bit / 4-bit 都能把质量拉回来,并且让 4-bit 首次接近全精度表现成为现实。该论文现已被 ICLR 高分接收:rebuttal 前 88666(top 1.4%),rebuttal 后 88886 (top 0.5%)。

前面已经说了,传统自回归就像打字机一样,一次只能处理一个token,且必须按照从左到右的顺序。但扩散模型Mercury 2的工作方式更像一位编辑——最终,Mercury 2能将生成速度提升5倍以上,且速度曲线截然不同。
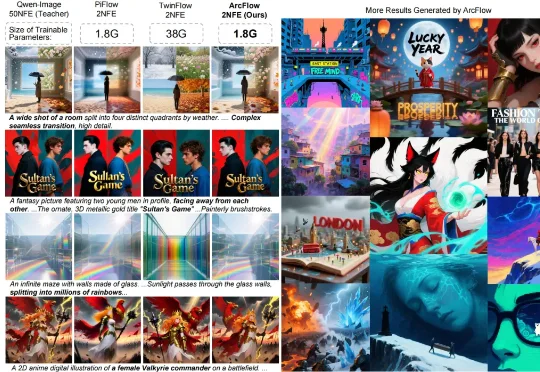
复旦大学与微软亚洲研究院带来的 ArcFlow 给出了答案:如果路是弯的,那就学会 “漂移”,而不是把路修直。在扩散模型中,教师模型(Pre-trained Teacher)的生成过程本质上是在高维空间中求解微分方程并进行多步积分。由于图像流形的复杂性,教师模型原本的采样轨迹通常是一条蜿蜒的曲线,其切线方向(即速度场)随时间步不断变化。
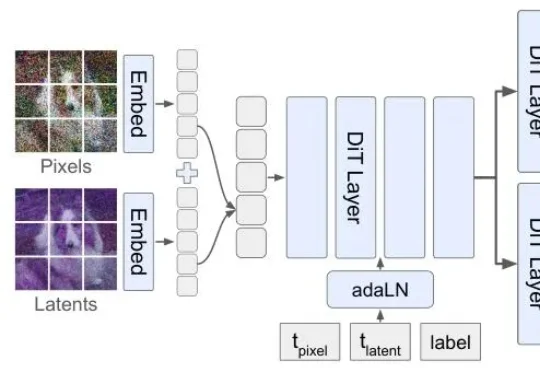
但扩散模型生图,顺序真的对吗?李飞飞团队最新论文提出的Latent Forcing方法直接打破了这一共识,他们发现生成的质量瓶颈不在架构,而在顺序。

谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!
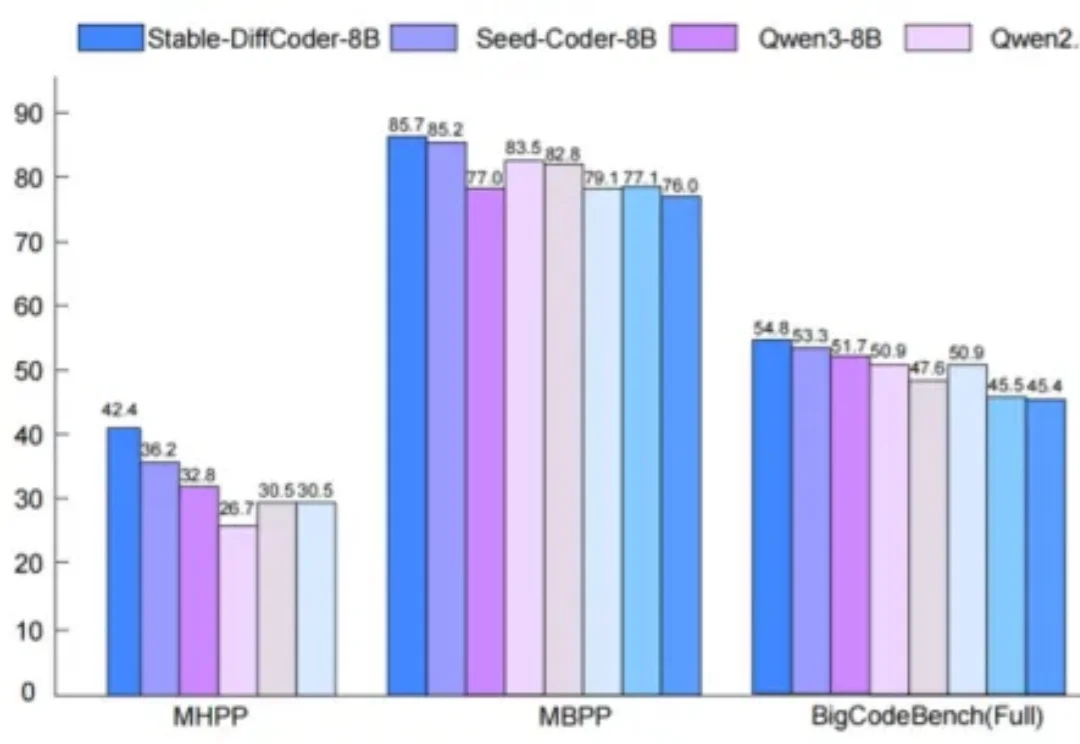
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。