英伟达AI奥赛夺冠,1.5B数学碾压DeepSeek-R1!代码全系开源,陶哲轩点赞
英伟达AI奥赛夺冠,1.5B数学碾压DeepSeek-R1!代码全系开源,陶哲轩点赞AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!
来自主题: AI技术研报
9176 点击 2025-04-26 17:17
 搜索
搜索
AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!

近年来,大模型(Large Language Models, LLMs)在数学、编程等复杂任务上取得突破,OpenAI-o1、DeepSeek-R1 等推理大模型(Reasoning Large Language Models,RLLMs)表现尤为亮眼。但它们为何如此强大呢?

千亿参数内最强推理大模型,刚刚易主了。32B——DeepSeek-R1的1/20参数量;免费商用;且全面开源——模型权重、训练数据集和完整训练代码,都开源了。这就是刚刚亮相的Skywork-OR1 (Open Reasoner 1)系列模型——
最近,像 OpenAI o1/o3、DeepSeek-R1 这样的大型推理模型(Large Reasoning Models,LRMs)通过加长「思考链」(Chain-of-Thought,CoT)在推理任务上表现惊艳。
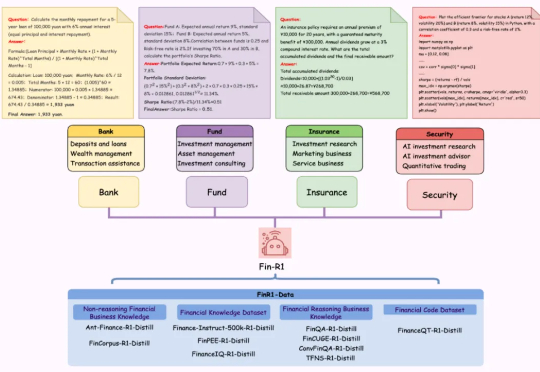
近日,上海财经大学统计与数据科学学院张立文教授与其领衔的金融大语言模型课题组(SUFE-AIFLM-Lab)联合数据科学和统计研究院、财跃星辰、滴水湖高级金融学院正式发布首款 DeepSeek-R1 类推理型人工智能金融大模型:Fin-R1,以仅 7B 的轻量化参数规模展现出卓越性能,全面超越参评的同规模模型并以 75 的平均得
2025 年第一款现象级的 AI 音乐爆品,就这么华丽丽地来了!3 月 26 日,国内「All in AGI 与 AIGC」的科技公司 —— 昆仑万维,发布了最新音乐大模型 Mureka V6 和 O1,给全球音乐圈带来了不小的震撼。

全球首个开源多模态推理大模型来了!38B参数模型性能直逼DeepSeek-R1,同尺寸上横扫多项SOTA。而这家中国公司之所以选择无偿将技术思路开源,正是希望同DeepSeek一样,打造开源界的技术影响力。

谷歌把推理大模型带入物理世界,机器人可以一边思考一边动作了!

乙巳新春,中国的推理大模型DeepSeek R1火爆全球。作为一款在推理能力上媲美OpenAI的o1且收费标准远低于o1的国产大模型,DeepSeek一时间在国内刮起一股扑面而来的全民AI风潮,并不令人意外,但这款来自大厂体系外创业团队的开源大模型,经由数位外国商界领袖与技术大佬口碑相传并最终形成在外国新闻媒体上“刷屏”的效果,则是非常耐人寻味了。

北京时间3月10日,据《华尔街日报》报道,富士康母公司鸿海已研发出中国台湾地区首个具备先进推理能力的大模型,性能上落后于DeepSeek的部分大模型。鸿海周一表示,已自主研发了具备推理能力的人工智能(AI)大语言模型FoxBrain,并在四周内完成训练。FoxBrain最初为公司内部使用而设计,具备数据分析、数学运算、推理以及代码生成的能力。