
OpenAI被曝自研人形机器人,4年前因缺数据解散团队,如今要用机器人数据反哺大模型了
OpenAI被曝自研人形机器人,4年前因缺数据解散团队,如今要用机器人数据反哺大模型了o3之后,OpenAI下一个项目曝光了: 人形机器人
来自主题: AI资讯
7236 点击 2024-12-25 11:10
 搜索
搜索
o3之后,OpenAI下一个项目曝光了: 人形机器人
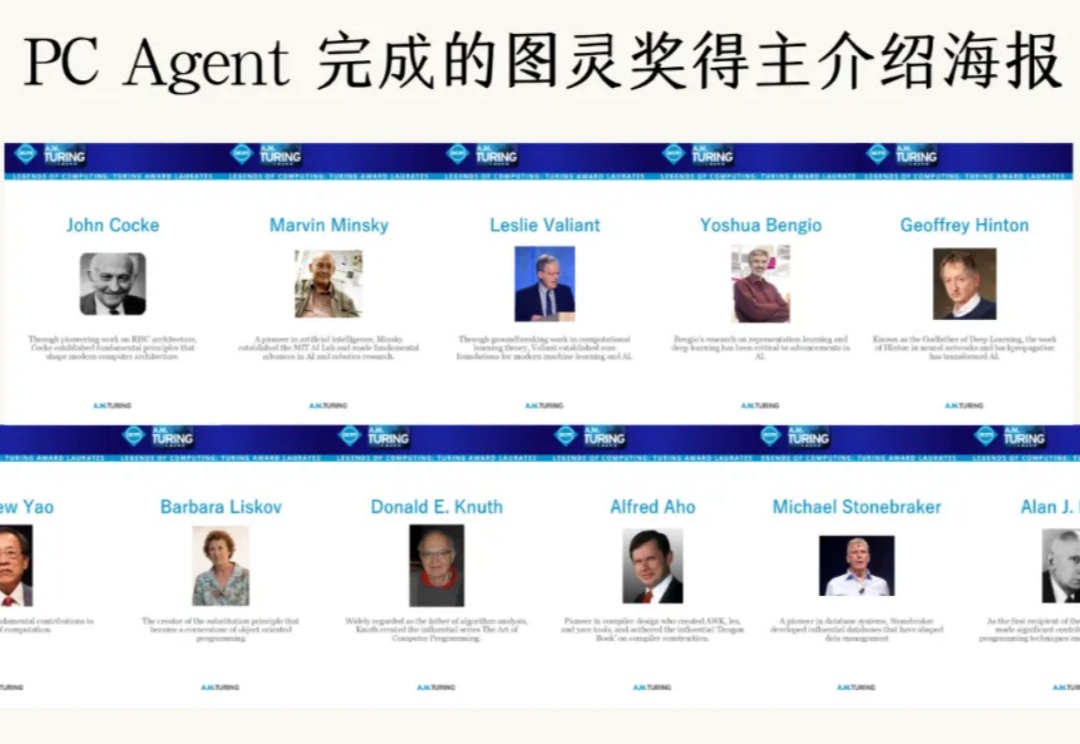
想象这样一个场景:深夜 11 点,你已经忙碌了一天,正准备休息,却想起明天早上还得分享一篇经典论文《Attention Is All You Need》,需要准备幻灯片。这时,你突然想到了自己的 AI 助手 —— PC Agent。
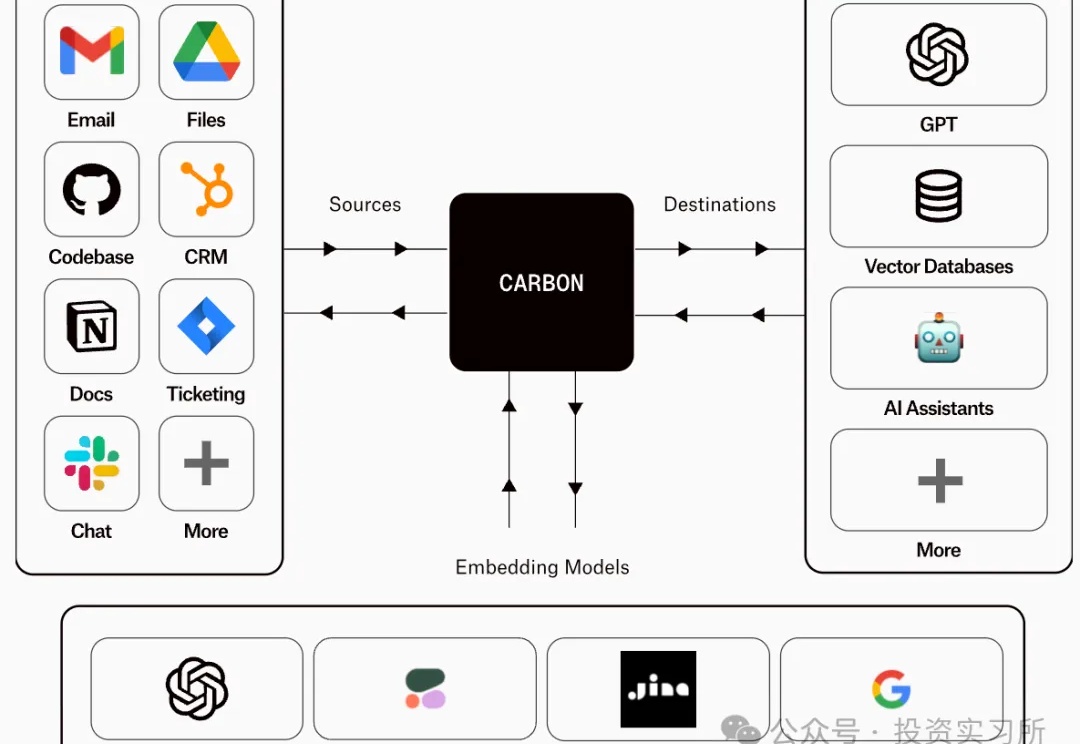
马斯克的 xAI 今天宣布正式完成了 60 亿美金的 C 轮融资,参与的投资人包括了 a16z、Blackrock、Fidelity、Kingdom Holdings、Lightspeed、MGX、Morgan Stanley、OIA、QIA、Sequoia Capital、Valor Equity Partners、Vy Capital、Nvidia、AMD 以及其它。
AI缺乏情商,需设计训练数据提高社交认知能力。 当你觉得AI不够好用时,很可能是因为它还不够“懂”你。

一家公司因远程招聘了一名看似优秀的计算机工程师,却遭遇了严重的网络安全威胁。

近年来,日本动漫的全球领导地位正遭遇挑战。有数据显示韩国的Line Manga和Piccoma已经超越Jump+,占据了亚太地区60%以上的数字漫画市场份额。日本动漫这个曾被誉为动漫界“珠穆朗玛峰”的存在,正受到移动端平台和AIGC带来的生产力突破而发生巨大的变化。
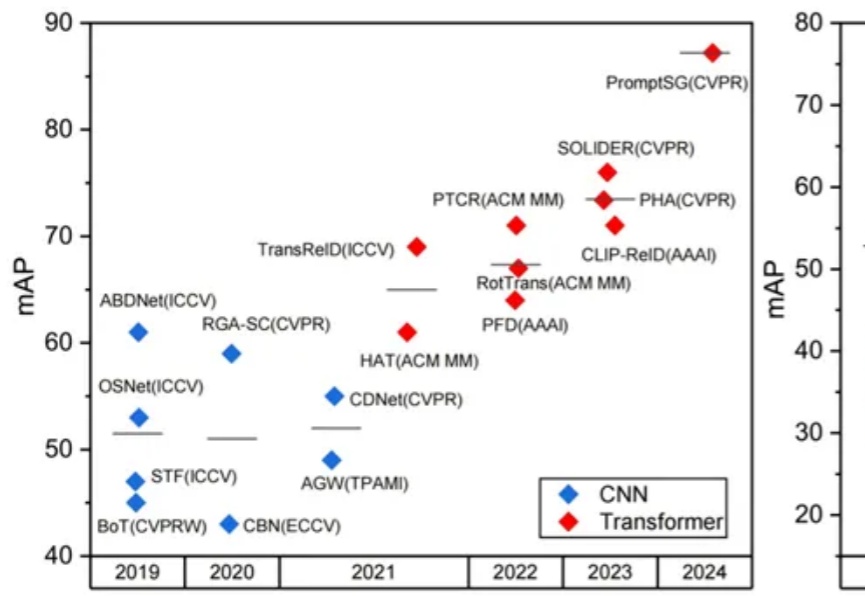
研究人员对基于Transformer的Re-ID研究进行了全面回顾和深入分析,将现有工作分类为图像/视频Re-ID、数据/标注受限的Re-ID、跨模态Re-ID以及特殊Re-ID场景,提出了Transformer基线UntransReID,设计动物Re-ID的标准化基准测试,为未来Re-ID研究提供新手册。
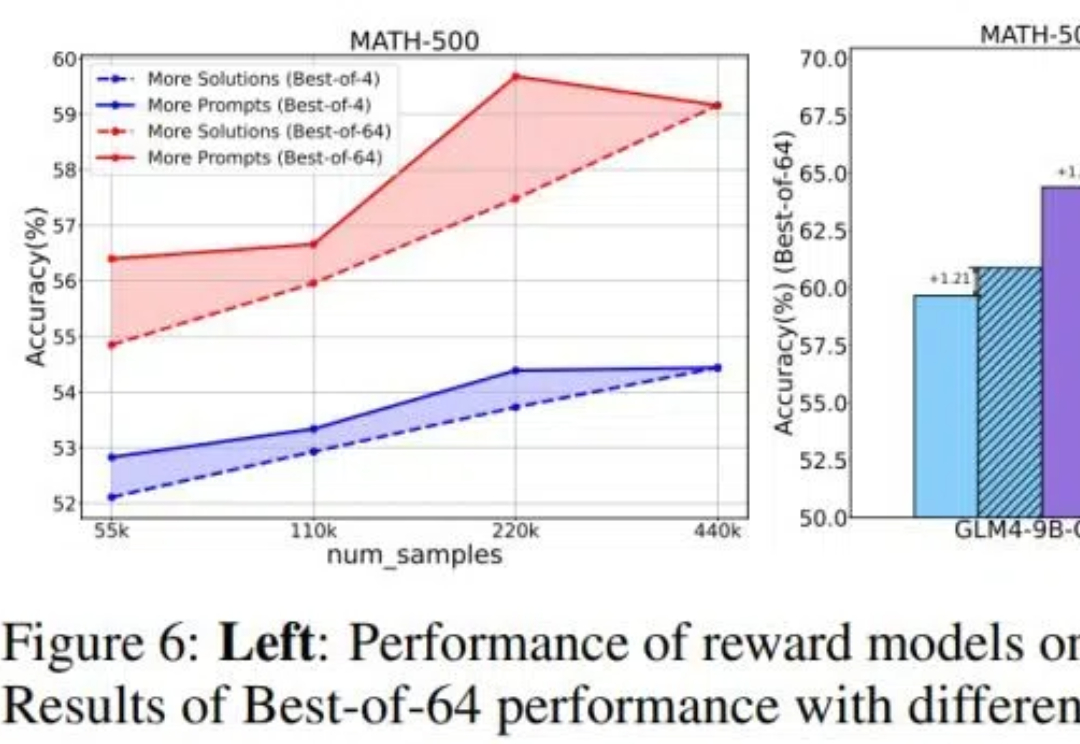
目前关于 RLHF 的 scaling(扩展)潜力研究仍然相对缺乏,尤其是在模型大小、数据组成和推理预算等关键因素上的影响尚未被系统性探索。 针对这一问题,来自清华大学与智谱的研究团队对 RLHF 在 LLM 中的 scaling 性能进行了全面研究,并提出了优化策略。
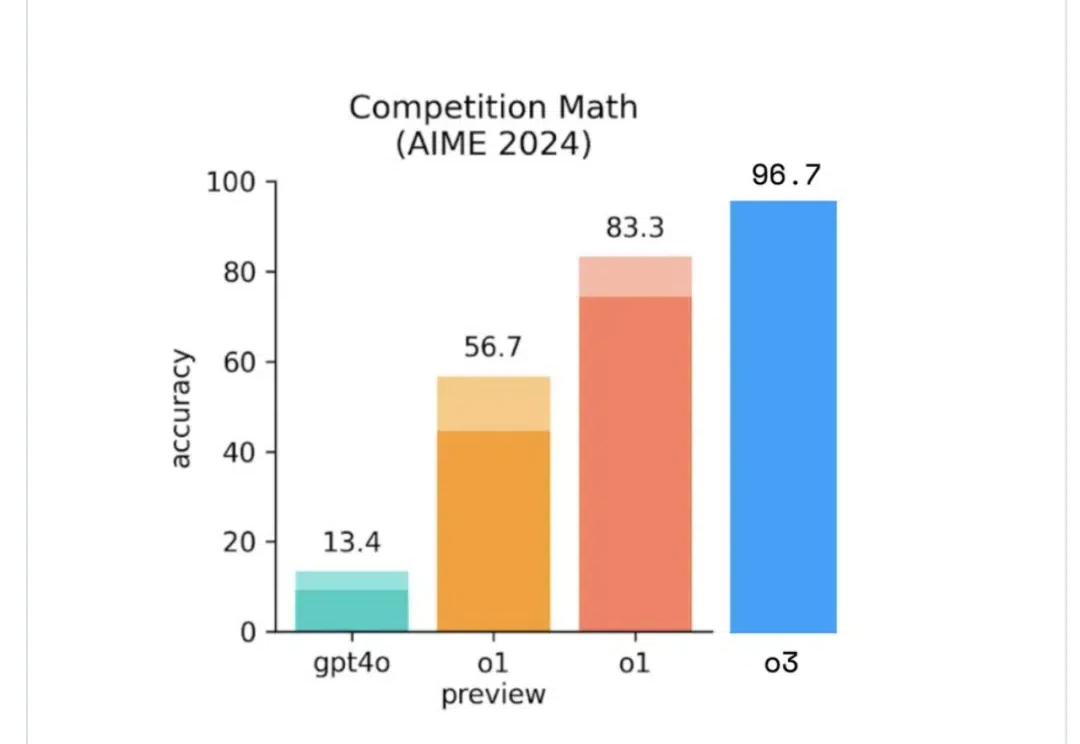
从韦氏智商测试来看,如果 o3 的 IQ 真这么高,则称得上非常优秀。 OpenAI o3 的智商(IQ)竟然已经这么高了吗 今天,Reddit 上一则热帖宣称「OpenAI o3 的 IQ 估计为 157」,并放出了一张数据图。

研究团队在最新时间序列预测基准评测TFB的25个数据集上进行了广泛验证,证明了DUET的卓越性能,为各行业的时间序列预测任务提供了全新的解决方案。