科研也完了,AI暴虐170位人类专家!Nature子刊:大模型精准预测研究结果,准确率高达81%
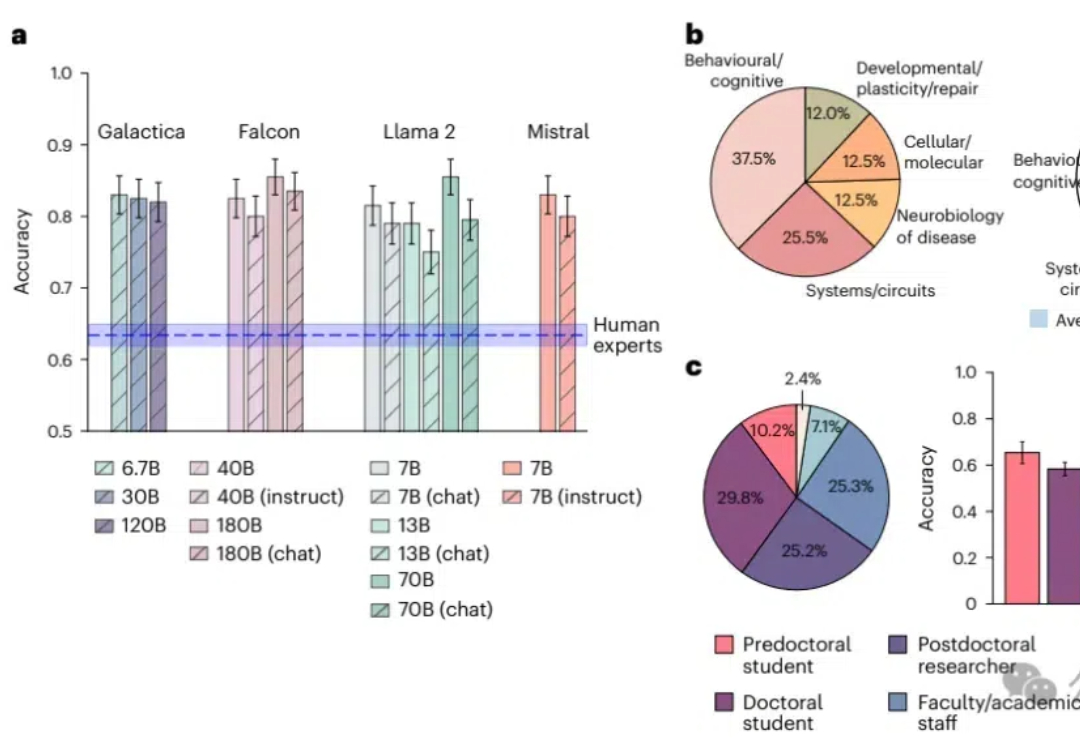
科研也完了,AI暴虐170位人类专家!Nature子刊:大模型精准预测研究结果,准确率高达81%知识密集型工作也败了!大型语言模型在预测神经科学结果方面超越了人类专家,平均准确率达到81%,而人类专家仅为63%;模型通过整合大量文献数据,展现出了惊人的前瞻性预测能力,预示着未来科研工作中人机协作的巨大潜力。
来自主题: AI技术研报
8651 点击 2024-12-07 15:20
 搜索
搜索
知识密集型工作也败了!大型语言模型在预测神经科学结果方面超越了人类专家,平均准确率达到81%,而人类专家仅为63%;模型通过整合大量文献数据,展现出了惊人的前瞻性预测能力,预示着未来科研工作中人机协作的巨大潜力。

12月5日,英伟达已经与越南政府达成合作,将在越南开设首个AI研发中心。越南投资部长阮智勇表示,英伟达将在越南开设人工智能研发中心,与越南最大的电信及移动运营商Viettel集团的数据中心共同推动越南先进人工智能技术的发展。

OpenAI“双12”直播第二天,依旧简短精悍,主题:新功能强化微调(Reinforcement Fine-Tuning),使用极少训练数据即在特定领域轻松地创建专家模型。少到什么程度呢?最低几十个例子就可以。

全国首个零售金融领域大模型天镜,揭晓了过去460多天的成绩单。 目前已实现智能营销交互、数据决策支持、防伪安全等八大应用场景。1.0版本人机交互模型完成100亿交易额,全面服务超2亿用户。
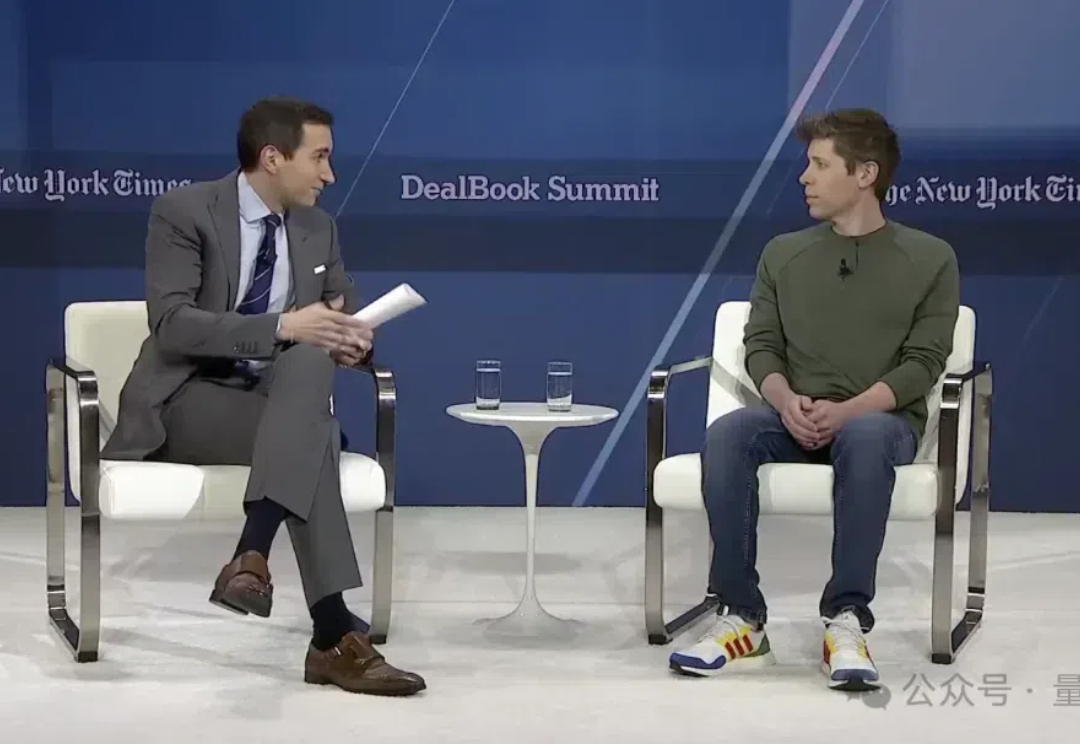
OpenAI最新交互数据,就这么水灵灵被奥特曼全抖出来了: 每周超过3亿活跃用户 每天用户们在上面发送10亿条消息 130万美国开发者使用OpenAI开发,全球数量更庞大
近年来,精神心理健康行业的热度显著上升。根据动脉橙数据库的统计,自2021年3月起,该行业内共有14家企业成功获得17笔融资,融资总金额已超过10亿元。这其中,包括好心情、昭阳健康、简单心理和壹点灵等知名企业。
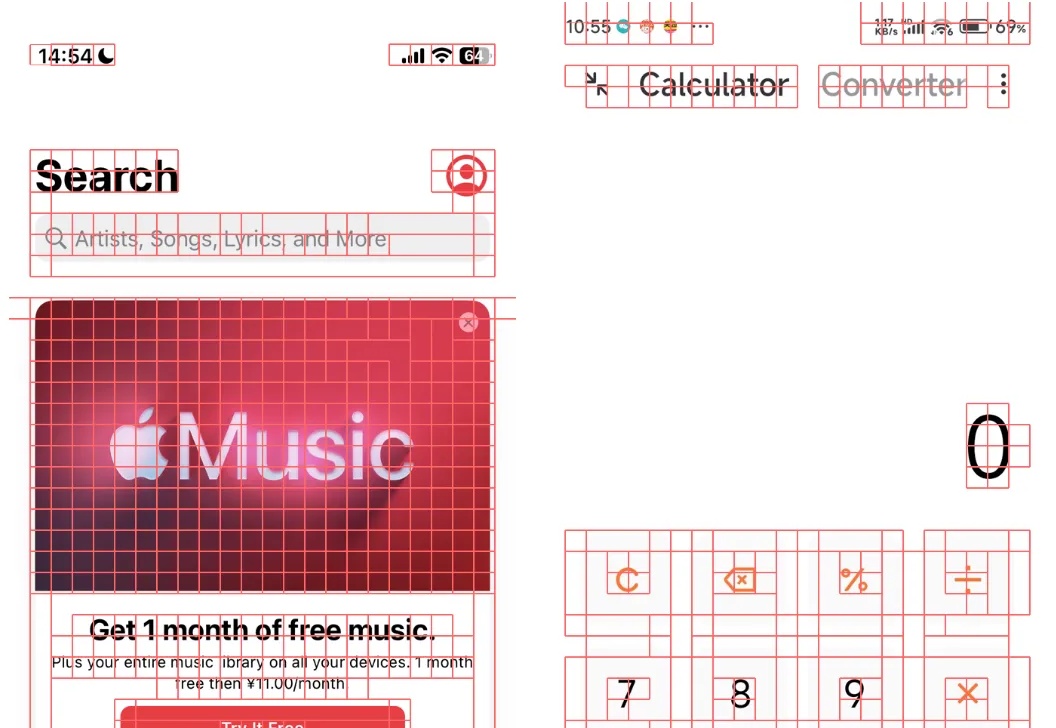
Show Lab 和微软推出 ShowUI,这是一个刚刚开源的 UI Agent 模型,在中文 APP 定位和导航能力上表现出色。通过创新的视觉 token 选择和独特的训练数据构建方法,该模型在有限的训练数据下实现了非常棒的性能。
在数字化浪潮席卷全球的今天,数据已成为企业最宝贵的资产之一。如何从海量数据中提取有价值的信息,转化为决策支持,是每个企业都在积极探索的问题。

谷歌DeepMind最新基础世界模型Genie 2登场!只要一张图,就能生成长达1分钟的游戏世界。从此,我们将拥有无限的具身智能体训练数据。更有人惊呼:黑客帝国来了。

大模型的能力是否已经触及极限?Business Insider采访了12位业内前沿人士。众人表示,利用新类型的数据、将推理能力融入系统, 以及创建更小但更专业的模型,将成为新一代的范式。