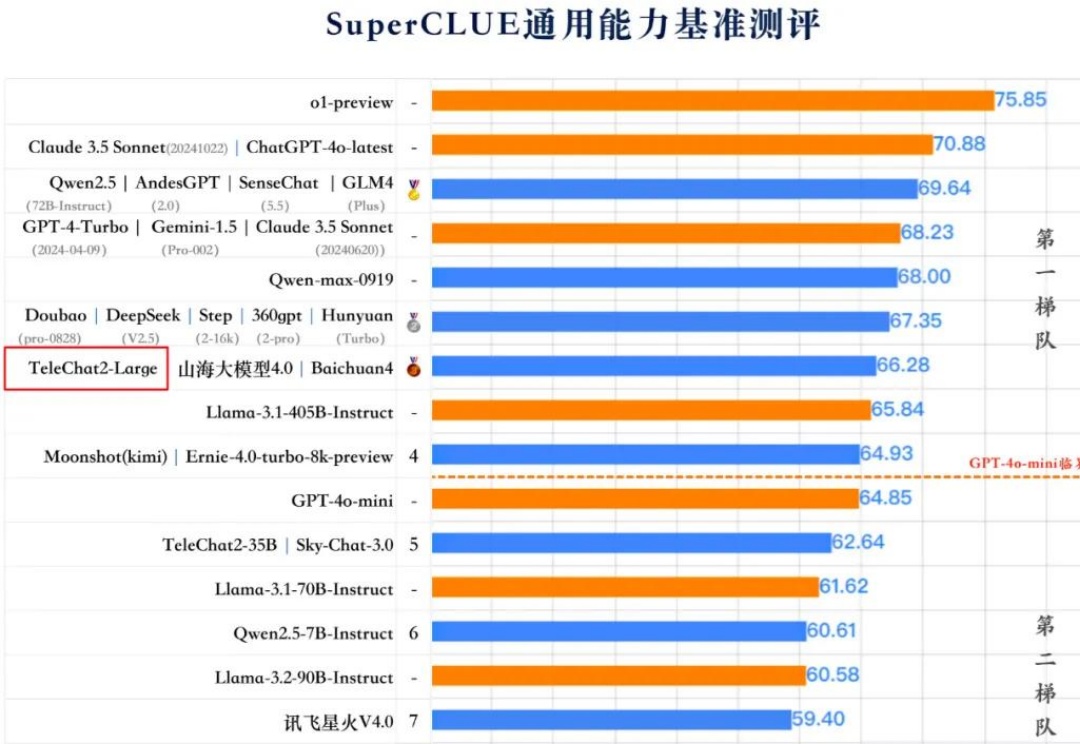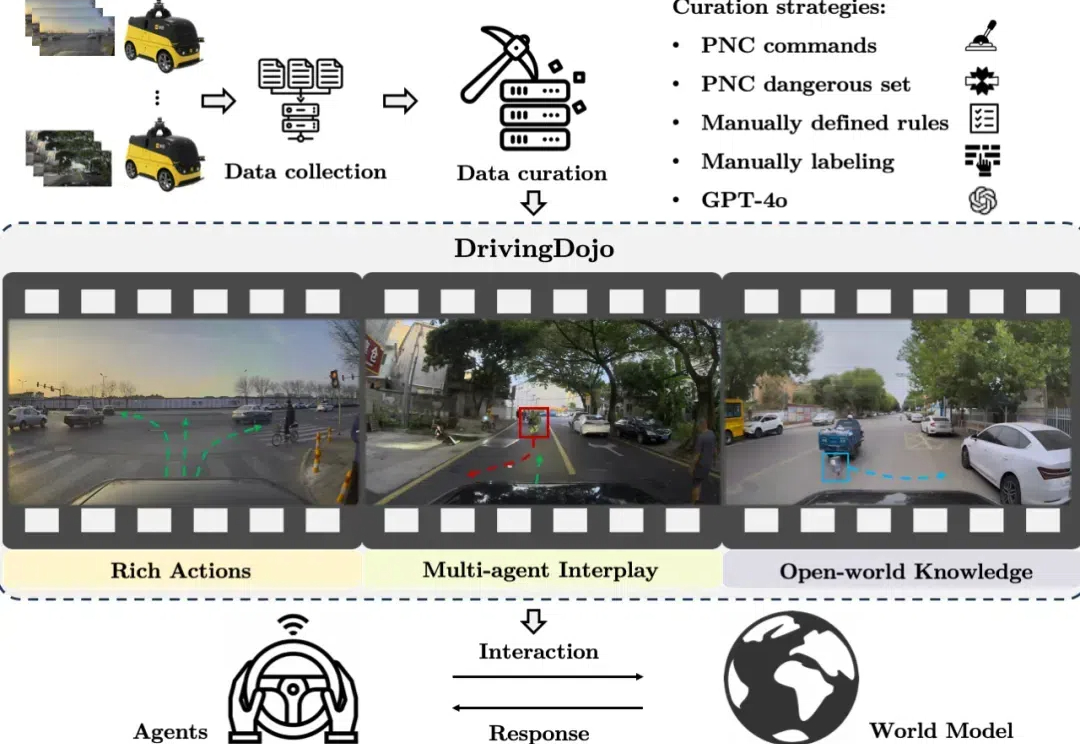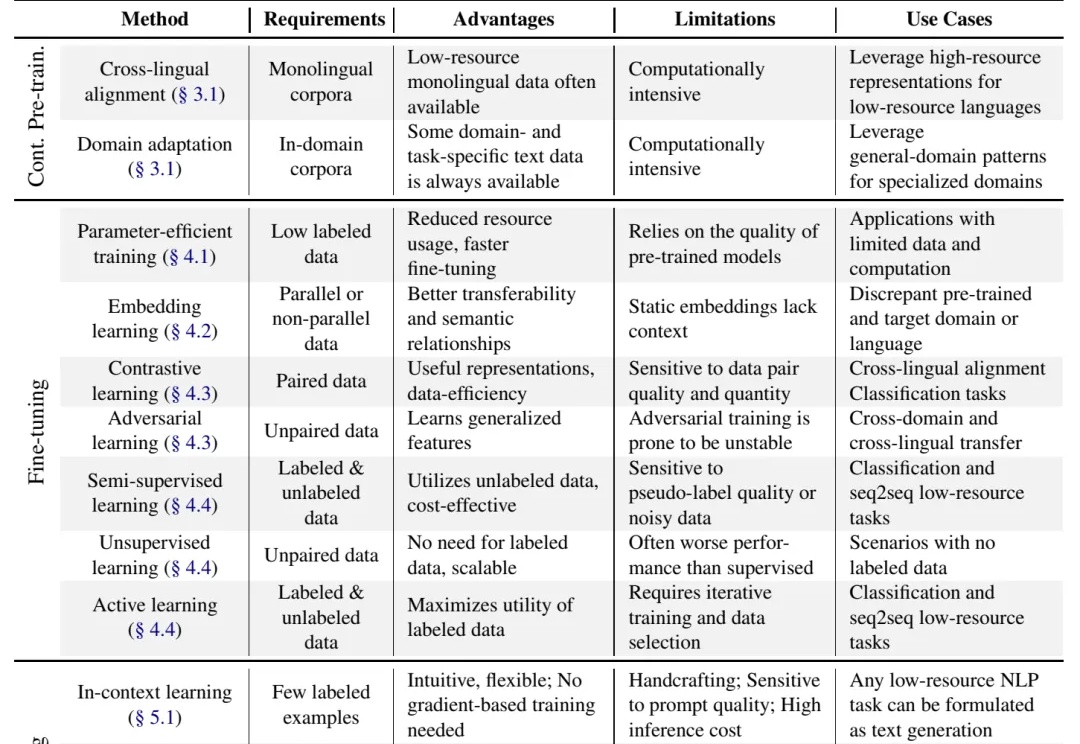
73页,开源「后训练」全流程!AI2发布高质量Tülu 3系列模型,拉平闭源差距,比肩GPT-4o mini
73页,开源「后训练」全流程!AI2发布高质量Tülu 3系列模型,拉平闭源差距,比肩GPT-4o miniAllen Institute for AI(AI2)发布了Tülu 3系列模型,一套开源的最先进的语言模型,性能与GPT-4o-mini等闭源模型相媲美。Tülu 3包括数据、代码、训练配方和评估框架,旨在推动开源模型后训练技术的发展。
来自主题: AI技术研报
8947 点击 2024-12-10 16:23