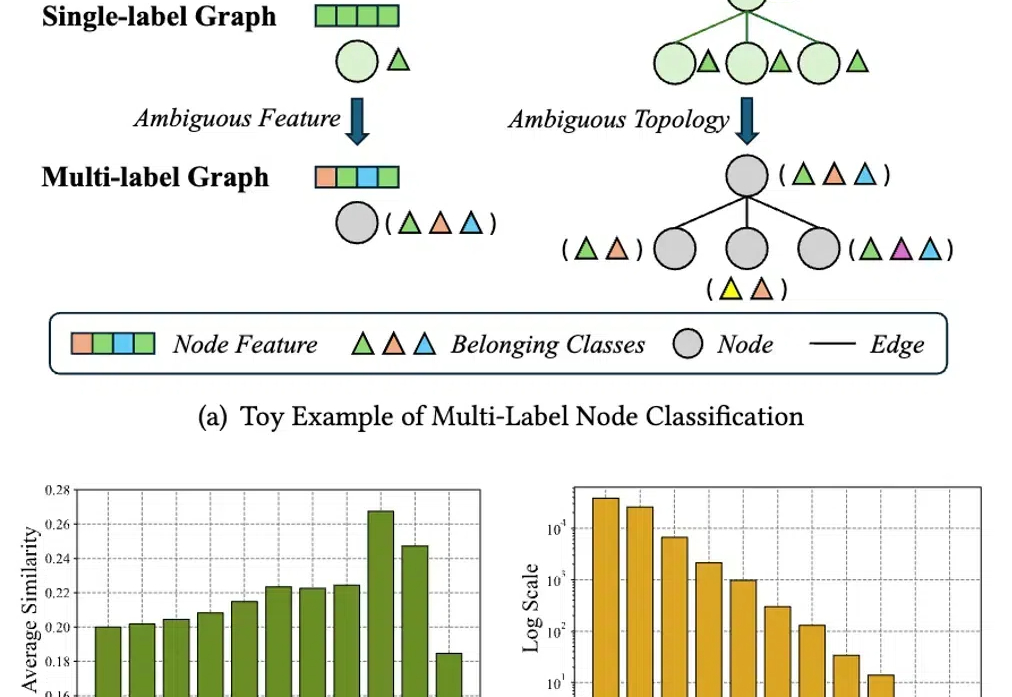
KDD2025 | 多标签节点分类场景下,阿里安全&浙大对图神经网络增强发起挑战
KDD2025 | 多标签节点分类场景下,阿里安全&浙大对图神经网络增强发起挑战ACM SIGKDD(简称 KDD)始于 1989 年,是全球数据挖掘领域历史最悠久、规模最大的国际顶级学术会议。KDD 2025 将于 2025 年 8 月 3 日在加拿大多伦多举办。
来自主题: AI技术研报
8365 点击 2024-12-14 14:00
 搜索
搜索
ACM SIGKDD(简称 KDD)始于 1989 年,是全球数据挖掘领域历史最悠久、规模最大的国际顶级学术会议。KDD 2025 将于 2025 年 8 月 3 日在加拿大多伦多举办。

wwAutoLabeler2.0助力自动驾驶高效数据标注。

提起AI产品赚钱,人们就兴奋。 看组数据:剪映和CapCut,两个软件全球每月用户超过8亿。到2024年,赚钱增长了三倍多,总共差不多有一百亿人民币。

近日,Crusoe Energy 宣布已筹集 6.86 亿美元,使其最新融资目标达到 8.18 亿美元。这笔资金将主要用于在德克萨斯州建设一个大型 AI 数据中心,并计划将该中心租赁给 Oracle(甲骨文)、微软 和 OpenAI 等知名公司,以支持其不断增长的算力需求。

在探索迈向AGI(通用人工智能)物理世界的路径中,通用机器人被视作关键载体。

只需要在手腕上戴一个腕带,就能够实现隔空打字。Meta近期推出的开源表面肌电图(sEMG)数据集,可进行姿态估计和表面类型识别,推动神经运动接口发展。

Apple MM1Team 再发新作,这次是苹果视频生成大模型,关于模型架构、训练和数据的全面报告,87 亿参数、支持多模态条件、VBench 超 PIKA,KLING,GEN-3。
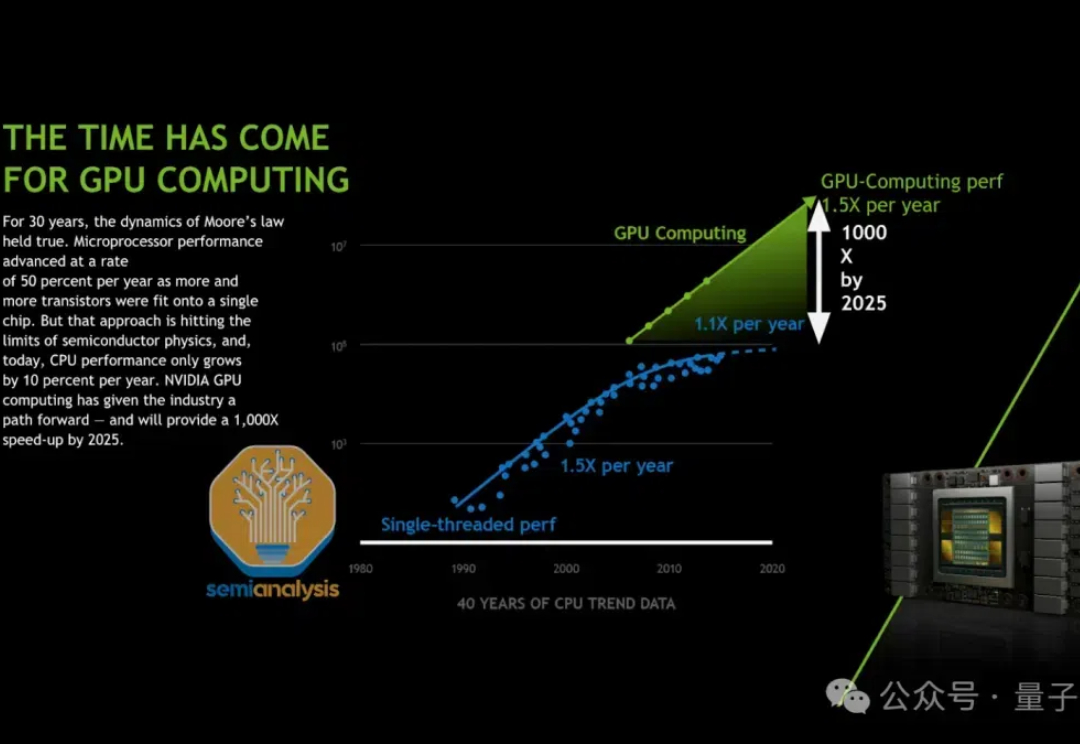
传闻反转了,Claude 3.5 Opus没有训练失败。 只是Anthropic训练好了,暗中压住不公开。 semianalysis分析师爆料,Claude 3.5超大杯被藏起来,只用于内部数据合成以及强化学习奖励建模。 Claude 3.5 Sonnet就是如此训练而来。

随着手术量的增长,越来越多的 AI 驱动产品进入市场,聚焦于手术室管理和数据优化。老牌科技公司如 Intuitive Surgical 和 Medtronic 正在加速推动手术机器人和医疗设备的整合,而诸如 Kronos Health 等初创公司则集中开发手术数据管理工具,进一步提升手术室效率和安全性。
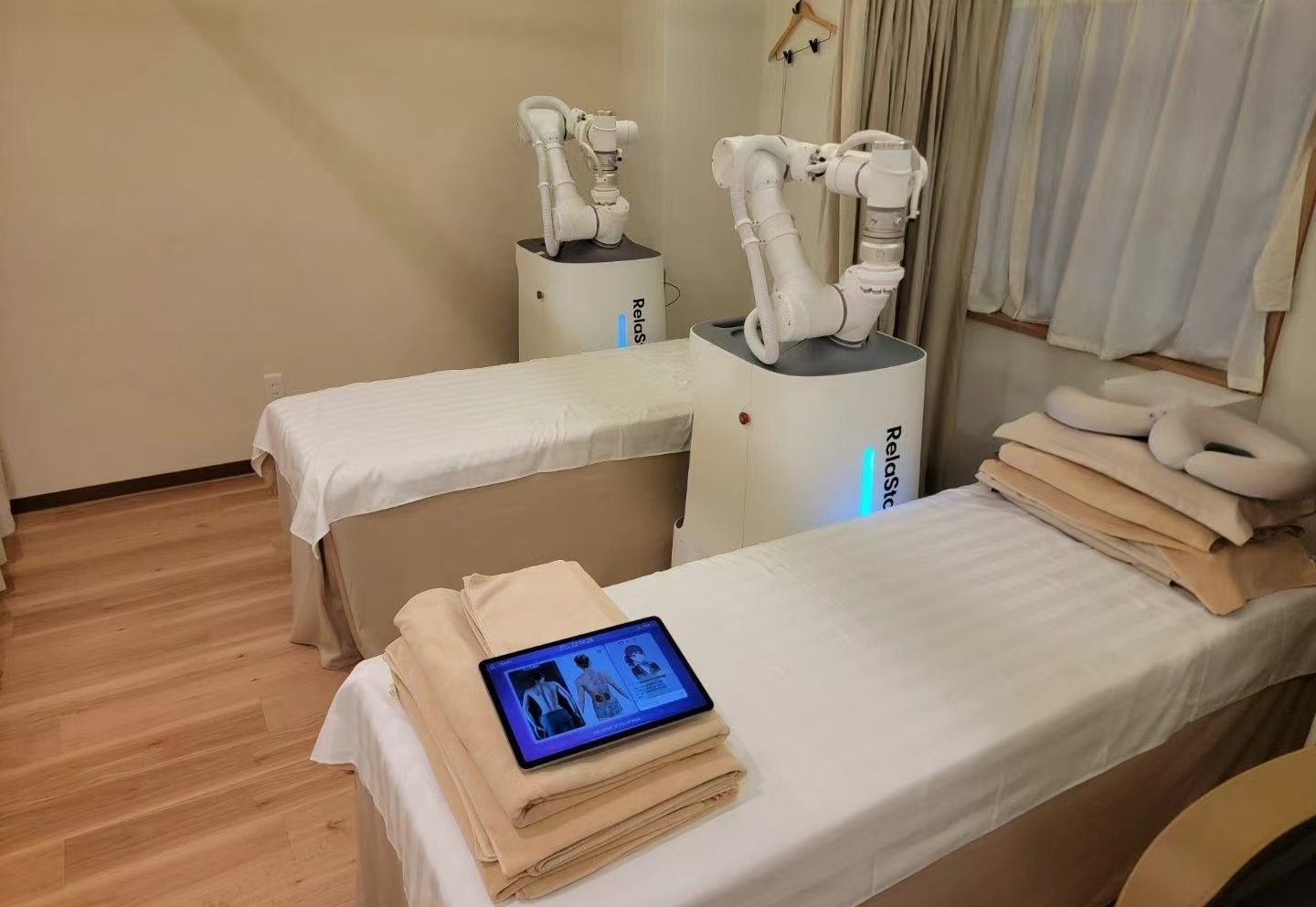
具身风暴在真实场景下广泛部署机器人,从而收集海量真实人机交互数据。