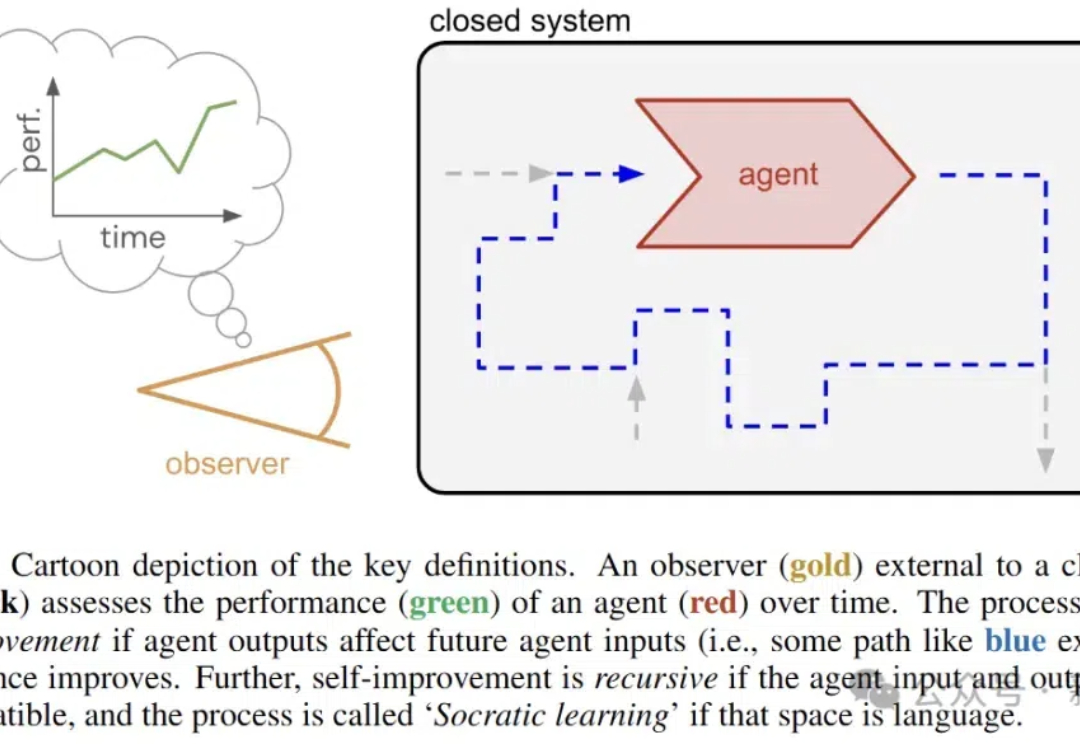
语言游戏让AI自我进化,谷歌DeepMind推出苏格拉底式学习
语言游戏让AI自我进化,谷歌DeepMind推出苏格拉底式学习近日,谷歌DeepMind的研究人员推出了苏格拉底式学习,在没有外部数据的情况下,让AI通过语言游戏不断变强。
来自主题: AI技术研报
8382 点击 2024-12-17 14:40
 搜索
搜索
近日,谷歌DeepMind的研究人员推出了苏格拉底式学习,在没有外部数据的情况下,让AI通过语言游戏不断变强。

以前我们总说:比你更了解你自己的是税务局。现在恐怕还需要变成:比你更了解你自己的,除了税务局,还有AI。
基于昇腾算力的矩阵运算改进求解器框架,大幅提升Local Optimum跳出能力。

利用数据和AI驱动的方法,建立反馈评估-自学习-验证的闭环,是企业Agent应用加速成功的关键。
根据Layoffs.fyi的统计数据,截至12月2日,全球科技公司已经至少裁员了14.9万个人。这不是普通的裁员潮,而是一场产业生态的重塑。

AI带来的机遇远比科技行业面临的所有机遇要大,但这需要初创企业转变观念,不再寻求颠覆和摧毁老牌企业,而是改造它们,因为初创企业在很多方面都处于劣势。成功应用AI需要两样东西:大量数据和昂贵的算力。大公司正好拥有这两样东西。

通用语言模型率先起跑,但通用视觉模型似乎迟到了一步。究其原因,语言中蕴含大量序列信息,能做更深入的推理;而视觉模型的输入内容更加多元、复杂,输出的任务要求多种多样,需要对物体在时间、空间上的连续性有完善的感知,传统的学习方法数据量大、经济属性上也不理性...... 还没有一套统一的算法来解决计算机对空间信息的理解。
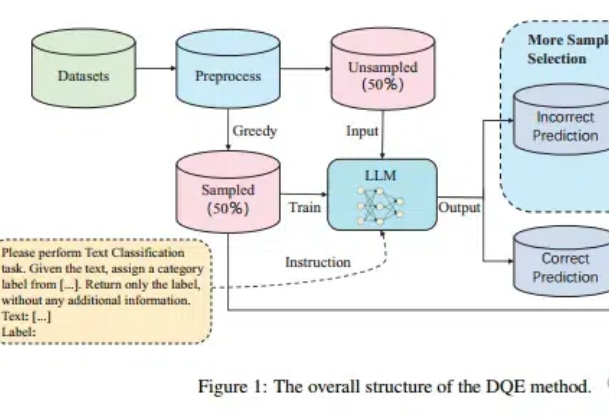
Scaling Law不仅在放缓,而且不一定总是适用! 尤其在文本分类任务中,扩大训练集的数据量可能会带来更严重的数据冲突和数据冗余。

全网独一份o1 pro架构爆料来了!首创自洽性机制打破推理极限,「草莓训练」系统首次揭秘。更令人震惊的是,OpenAI和Anthropic自留Orion、Claude 3.5超大杯,并不是内部失败了,而是它们成为数据生成的秘密武器。
ACM SIGKDD(简称 KDD)始于 1989 年,是全球数据挖掘领域历史最悠久、规模最大的国际顶级学术会议。KDD 2025 将于 2025 年 8 月 3 日在加拿大多伦多举办。