# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
人工智能在今天百花齐放,大模型靠规模称王,小模型则凭数据取胜。
当然我们也希望,可以付出更少的资源,并达到相同的效果。
很早之前,谷歌就有相关研究,探索了在固定算力的情况下,如何分配模型参数量和训练数据量,以达到最好的性能。
近日,LeCun参与的一项工作从另一个角度向我们展示了,神经网络在实践中的灵活性到底有多大?

论文地址:https://arxiv.org/pdf/2406.11463
这个灵活性指的是,神经网络拟合训练数据(样本数量)的能力,在实际应用中受到哪些因素的影响。
比如我们第一时间想到的可能就是模型的参数量。
人们普遍认为,神经网络可以拟合至少与自身参数一样多的训练样本。
这就像是解一个线性方程组,有多少个参数(或者方程)、多少个未知数,从而判断解的数量。
然而神经网络实际上要复杂的多,尽管在理论上能够进行通用函数逼近,但在实践中,我们训练的模型容量有限,不同优化器也会导致不同的效果。
所以,本文决定用实验的方法,分别考察数据本身的性质、模型架构、大小、优化器和正则化器等因素。
而模型拟合数据的能力(或者说学习信息的能力),由有效模型复杂性(EMC)来表示。
这个EMC是怎么算的呢?
一开始,在少量样本上训练模型。如果它在训练后达到100%的训练准确率,则将模型重新初始化并增大训练样本数量。
迭代执行此过程,每次逐步增加样本量,直到模型不再完全拟合所有训练样本,将模型能实现完美拟合的最大样本量作为网络的EMC。
——一直喂饭,直到吃撑,则得到饭量大小。
实证分析
为了全面剖析影响神经网络灵活性的因素,研究人员考虑了各种数据集、架构和优化器。
实验采用了包括MNIST、CIFAR-10、CIFAR-100和ImageNet等视觉数据集,以及Forest-Cover Type、Adult Income和Credit等表格数据集。
另外,实验还使用了更大规模的合成数据集,通过Min-SNR加权策略进行的高效扩散训练,生成分辨率为128×128的高质量图像数据集——ImageNet-20MS,包含10个类别的2000万个样本。
实验评估了多层感知器(MLP)、CNN架构的ResNet和EfficientNet,以及Transformer架构的ViT。
作者系统地调整了这些架构的宽度和深度:
比如对于MLP,通过每层添加神经元来增加宽度,同时保持层数不变,或者通过添加更多层来增加深度,同时保持每层神经元数量不变。
对于一般的CNN(多个卷积层,接一个恒定大小的全连接层),可以改变每层的kernel数量或者卷积层的总数。
对于ResNet,可以改变kernel的数量或者block的数量(深度)。
而对于ViT,可以改变编码器的数量(深度)、patch embedding的维度和自注意力(宽度)。
实验采用的优化器包括随机梯度下降(SGD)、Adam、AdamW、全批次梯度下降(full-batch Gradient Descent)和second-order Shampoo optimizer。
由此,研究人员可以测试随机性和预处理等特征如何影响最小值。同时。为了确保跨数据集和模型大小进行有效优化,研究人员仔细调整了每个设置的学习率和批量大小,并省略了权重衰减。
研究人员通过修改隐藏层的宽度来扩展一个2层的MLP,通过修改层数和通道数来扩展CNN,并在一系列图像(MNIST、CIFAR-10、CIFAR-100、ImageNet)和表格(CoverType、Income 和 Credit)数据集上训练模型。
结果显示,在不同数据类型上训练的网络在EMC方面存在显著差异:
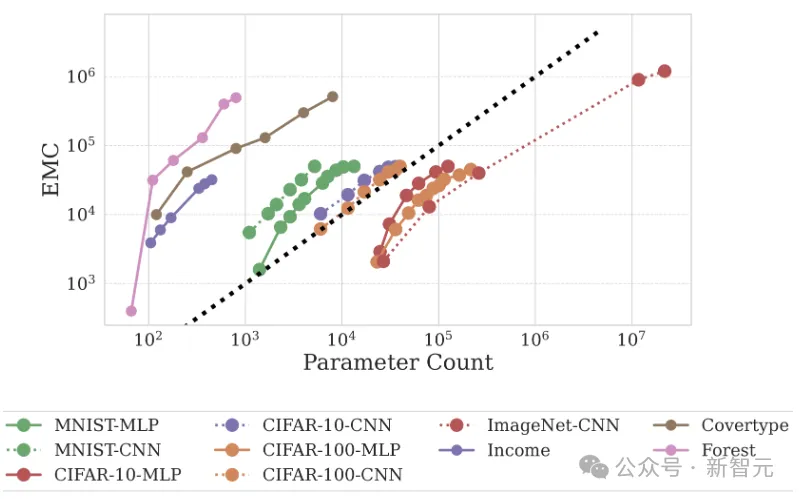
在表格数据集上训练的网络表现出更高的容量;而在图像分类数据集中,测试精度和容量之间存在很强的相关性。
值得注意的是,MNIST(模型达到99%以上的测试准确度)产生的EMC最高,而ImageNet的EMC最低,这表明了泛化与数据拟合能力之间的关系。
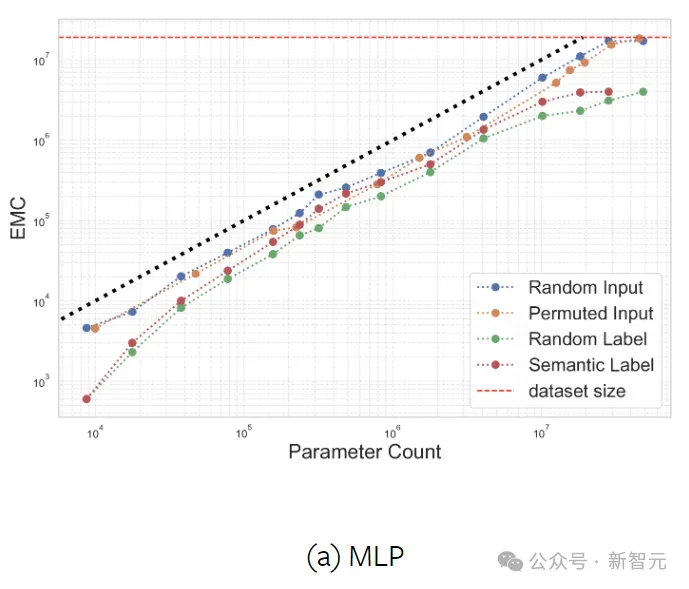
这里通过改变每层中的神经元或kernel的数量,来调整MLP和CNN的宽度,并在合成数据集ImageNet-20MS上进行训练。
实验测试了四种情况下的EMC:语义标签、随机标签、随机输入(高斯噪声)和固定随机排列下的输入。
分配随机标签(而非真实标签)的目的是探索过参数化(overparameterization)和欠参数化(underparameterization)之间的边界。
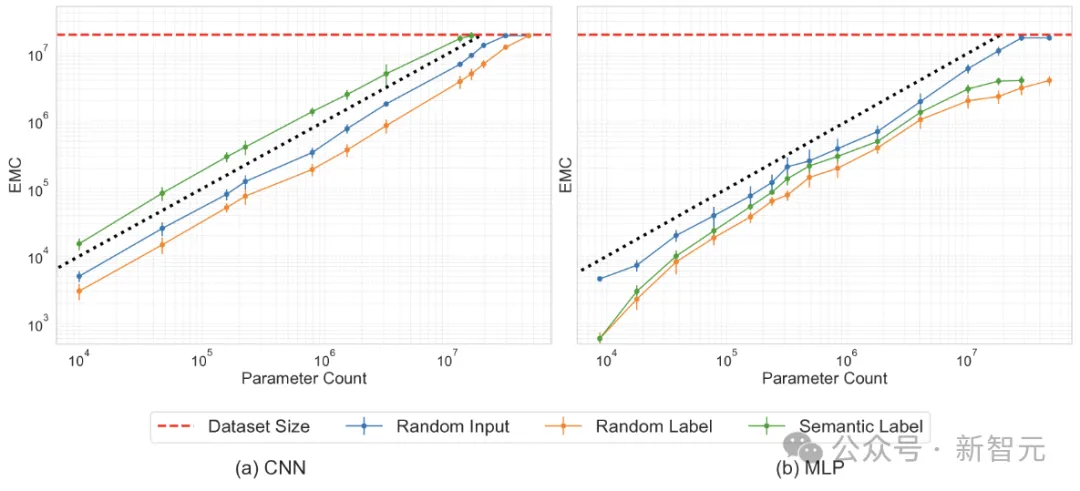
从上图的结果可以发现,与原始标签相比,当分配随机标签时,网络拟合的样本要少得多,此时神经网络的参数效率低于线性模型。而从整体上来看,模型的参数量与拟合的数据量大致呈线性关系。
分类数量对EMC的影响
作者随机合并了CIFAR-100中的类别(保留原始数据集的大小),在具有不同数量kernel的2层CNN上进行实验。
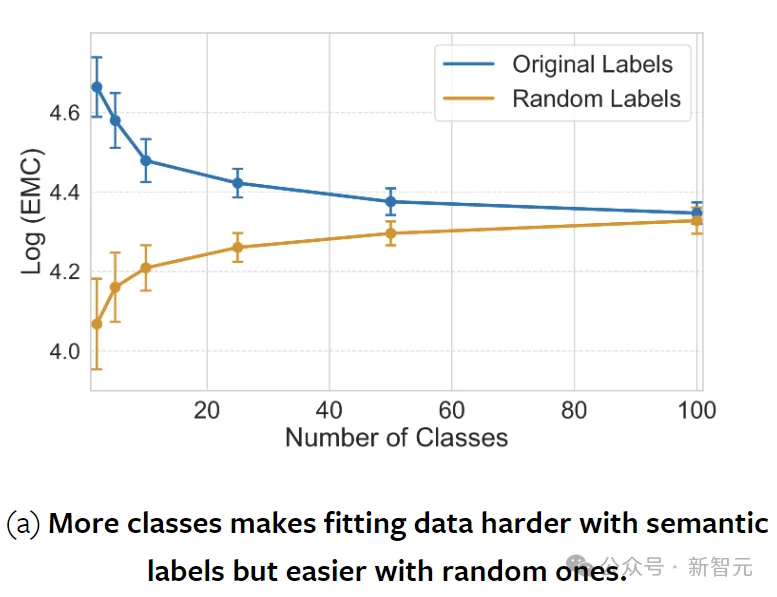
结果如上图所示,随着类数量的增加,带有语义标签的数据变得越来越难以拟合,因为模型必须对其权重中的每个样本进行编码。
相比之下,随机标记的数据变得更容易拟合,因为模型不再被迫为语义上不同的样本分配相同的类标签。
神经网络偏向于拟合语义连贯的标签而不是随机标签,而且,与随机标签相比,网络拟合语义标签的熟练程度通常与其泛化能力相关。
这种泛化也使得CNN这种架构能够拟合比模型参数量更多的样本。
传统的机器学习观念认为,高容量模型往往会过度拟合,从而影响其对新数据的泛化,而PAC-贝叶斯理论则指出,模型更喜欢正确的数据标记。
而本文的实验将这两种理论联系在了一起。
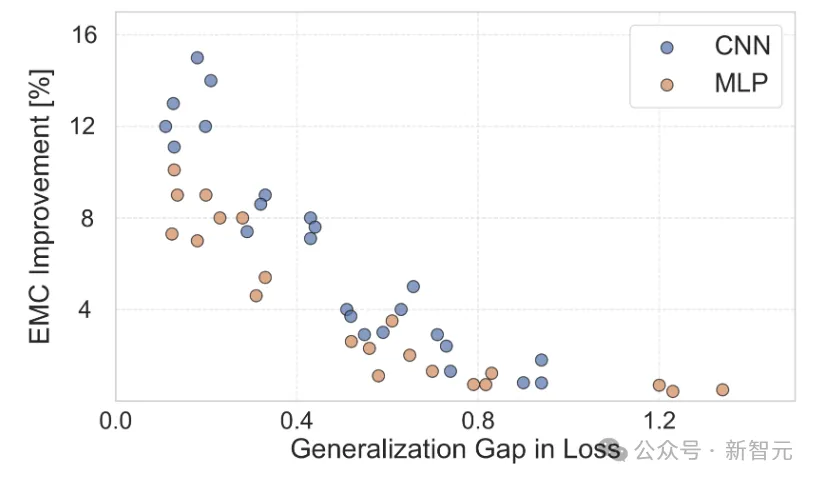
上图中,在正确标记和随机标记的数据上计算各种CNN和MLP的EMC,测量模型遇到语义标签与随机标签时EMC增加的百分比。
结果表明EMC增加的百分比与generalization gap之间存在显著的负相关关系,这不仅证实了泛化的理论基础,而且阐明了理论的实际意义。
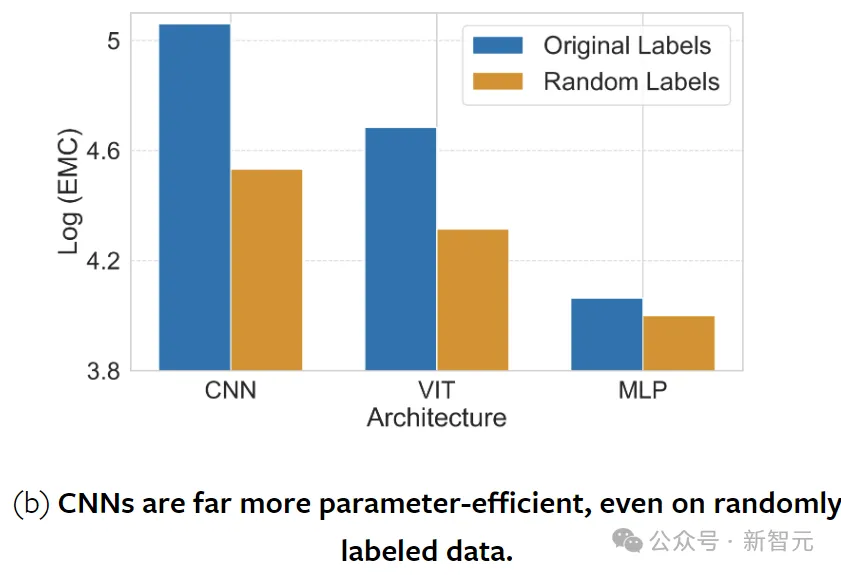
关于CNN和ViT的效率和泛化能力一直存在争议。
实验表明,CNN以硬编码的归纳偏差为特征,在EMC中优于ViT和MLP。当对语义标记的数据进行评估时,这种优势在所有模型大小中都持续存在。
CNN从具有空间结构的数据中获益匪浅,当空间结构通过排列被打破时,拟合的样本就会减少。而MLP缺乏这种对空间结构的偏好,因此它们拟合数据的能力是不变的。
另外,用高斯噪声代替输入可提高两种架构的容量,这可以解释为,在高维中,嘈杂的数据相距甚远,因此更容易分离。
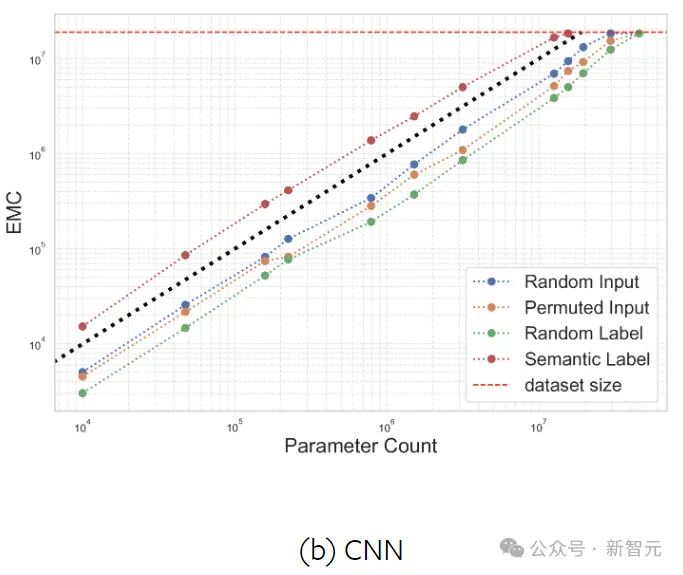
值得注意的是,与随机输入相比,CNN可以拟合具有语义标签的样本数量要多得多,MLP却正好相反,这再次凸显了CNN在图像分类方面的卓越泛化能力。
扩展网络规模
下图展示了各种扩展配置下的EMC。
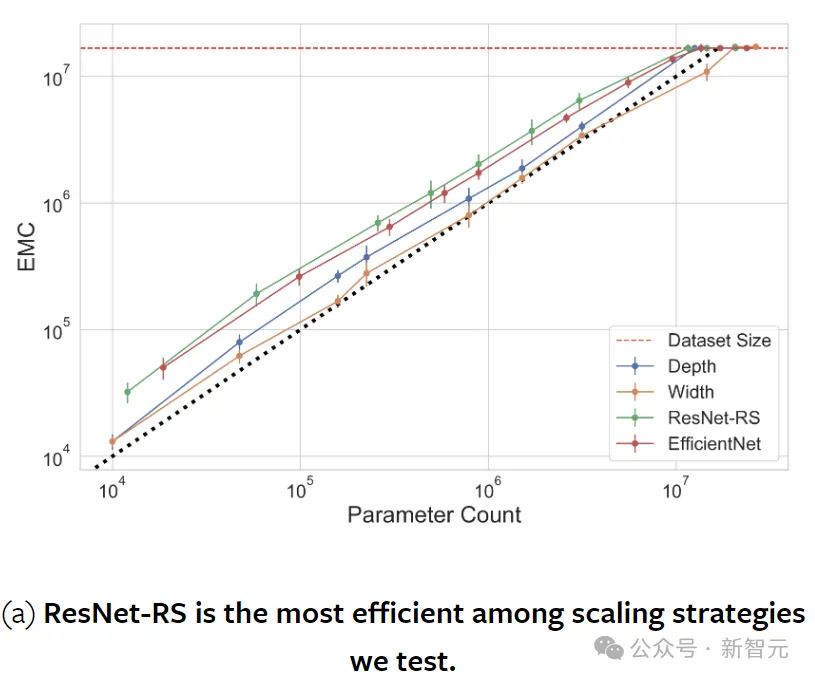
对于ResNet,扩展措施包括增加宽度(kernel数量)、增加深度。EfficientNet固定系数,同时缩放深度、宽度和分辨率。ResNet-RS根据模型大小、训练持续时间和数据集大小调整缩放。
对于ViT,使用SViT和SoViT方法,并尝试分别改变编码器块的数量(深度)和patch embedding的维度和自注意力(宽度)。
分析表明,缩放深度比缩放宽度更具参数效率。这个结论同时也适用于随机标记的数据,表明并不是泛化的产物。
激活函数
非线性激活函数对于神经网络容量至关重要,没有它们,神经网络只是大型因式分解线性模型。
研究结果表明,ReLU显著增强了模型的容量。虽然它最初的作用是为了减轻梯度的消失和爆炸,但ReLU还提高了网络的数据拟合能力。
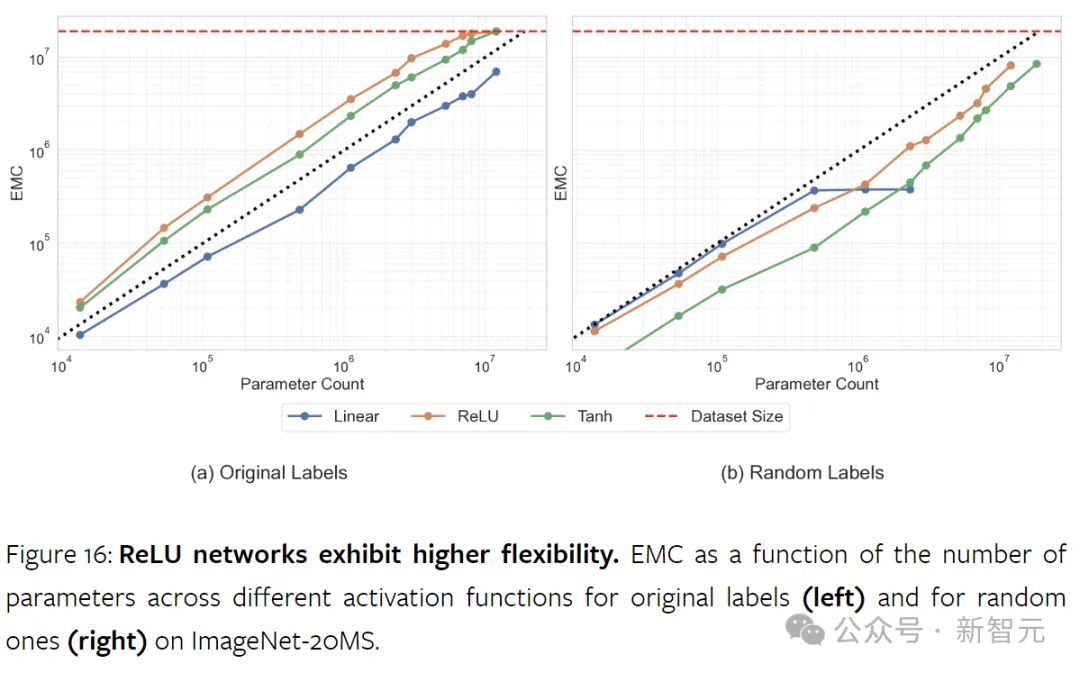
相比之下,tanh虽然也是非线性的,但不能实现类似的效果。
优化技术和正则化策略的选择在神经网络训练中至关重要。这种选择不仅影响训练收敛性,还影响所找到的解决方案的性质。
参与实验的优化器包括SGD、全批次梯度下降、Adam、AdamW和Shampoo。
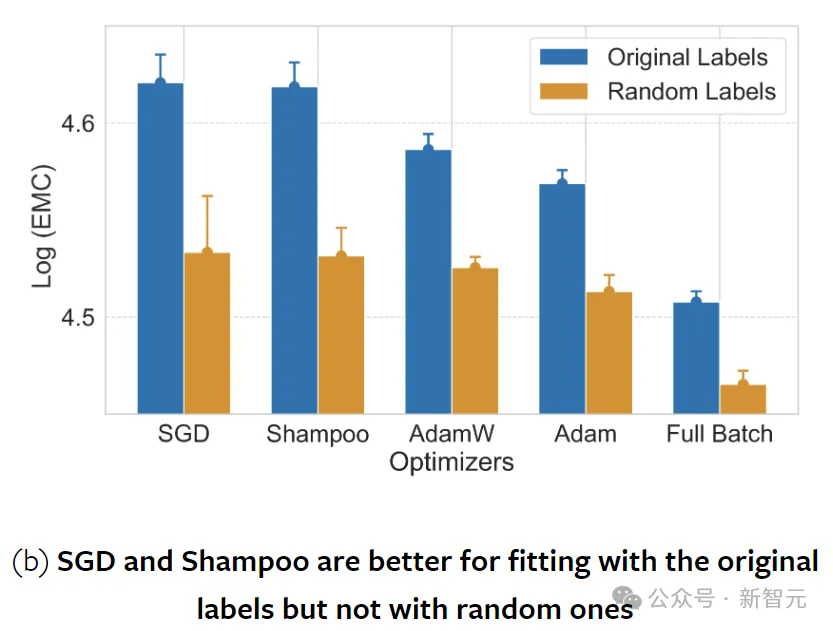
以前的研究认为SGD具有很强的平坦度寻求正则化效应,但上图表明,SGD还能够比全批次(非随机)梯度下降训练拟合更多的数据。
不同优化器的EMC测量值表明,优化器不仅在收敛速率上有所不同,而且在发现的最小值类型上也有所不同。
文章来源于“新智元”,作者“新智元”




