
突破医疗影像分析:AI如何通过语言引导实现自我学习与精准分类
突破医疗影像分析:AI如何通过语言引导实现自我学习与精准分类本文提出了一种名为MedUnA的方法,旨在解决医疗图像分类中因缺乏标注数据而导致的监督学习挑战。MedUnA利用视觉-语言模型(VLMs)中的视觉与文本对齐特性,通过无监督学习来适应医疗图像分类任务。
来自主题: AI资讯
6226 点击 2024-09-10 14:39
 搜索
搜索
本文提出了一种名为MedUnA的方法,旨在解决医疗图像分类中因缺乏标注数据而导致的监督学习挑战。MedUnA利用视觉-语言模型(VLMs)中的视觉与文本对齐特性,通过无监督学习来适应医疗图像分类任务。

在此之上,「帆软」将FineChatBI的核心能力集成开放给部分优质客户,让用户依托平台,能够独立部署企业数据库,完善企业底层数据资产建设。

与 Text2SQL 或 RAG 不同,TAG 充分利用了数据库系统和 LLM 的功能。
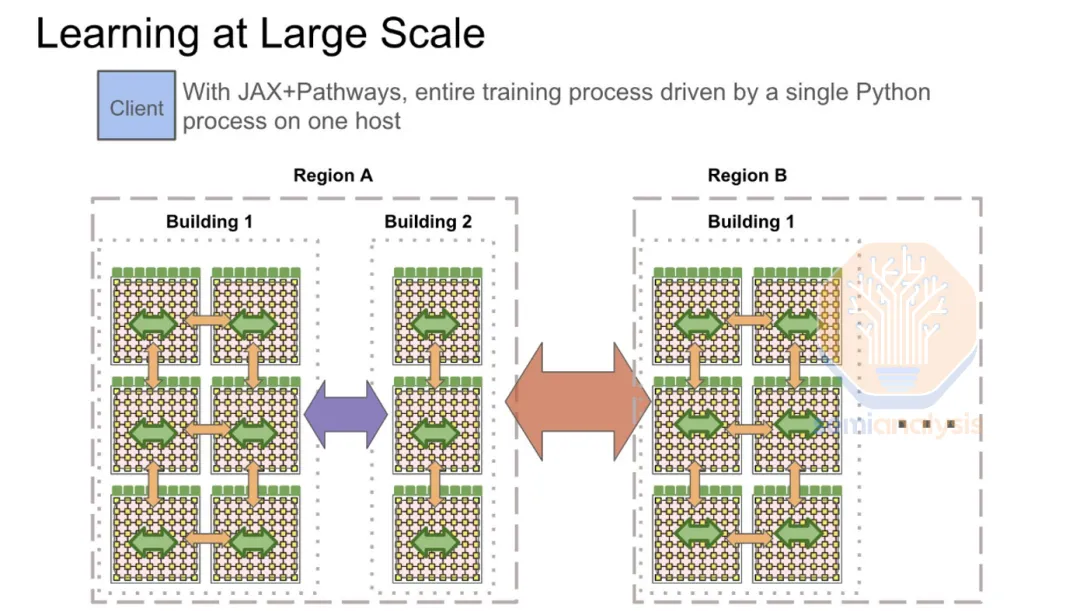
最近,国外的一份研究报告揭秘了 OpenAI、围绕和谷歌在 AI Infra 层的布局,我们将文章提炼出了核心观点,并进行精校翻译。

基于图神经网络的方法被广泛应用于不同问题并且显著推动了相关领域的进步,包括但不限于数据挖掘、计算机视觉和自然语言处理。考虑到图神经网络已经取得了丰硕的成果,一篇全面且详细的综述可以帮助相关研究人员掌握近年来计算机视觉中基于图神经网络的方法的进展,以及从现有论文中总结经验和产生新的想法。

所有模型都是通过在来自互联网的海量数据上进行训练来工作的,然而,随着人工智能越来越多地被用来生成充满垃圾信息的网页,这一过程可能会受到威胁。

近日,上海交通大学、上海人工智能实验室和上海交通大学附属瑞金医院联合团队发布基于异常检测预训练的心电长尾诊断模型。
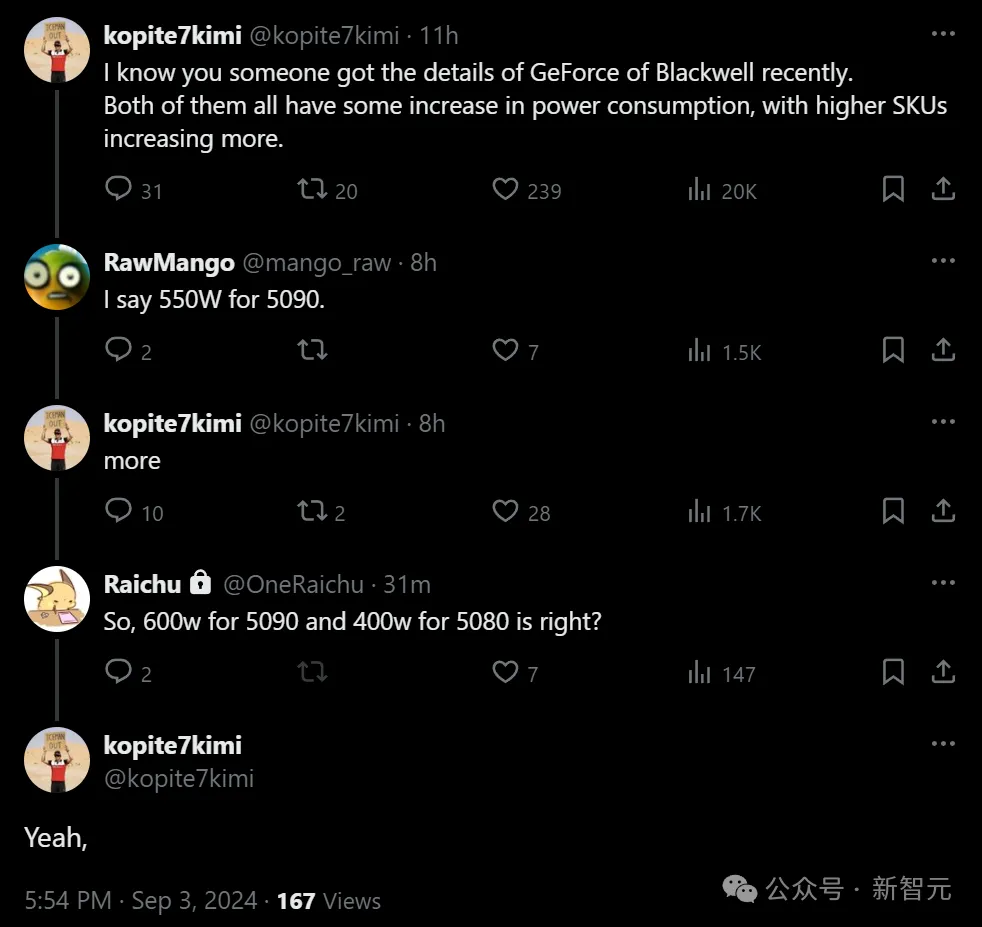
根据最新泄露的数据,英伟达GeForce RTX 5080的功耗或将提升至400W,并在部分性能上达到RTX 4090的110%!而RTX 5090的功耗预计将增加150W,达到惊人的600W。

训练代码、中间 checkpoint、训练日志和训练数据都已经开源。

AlphaFold2解决了很大程度上解决了单体蛋白质结构预测问题。