
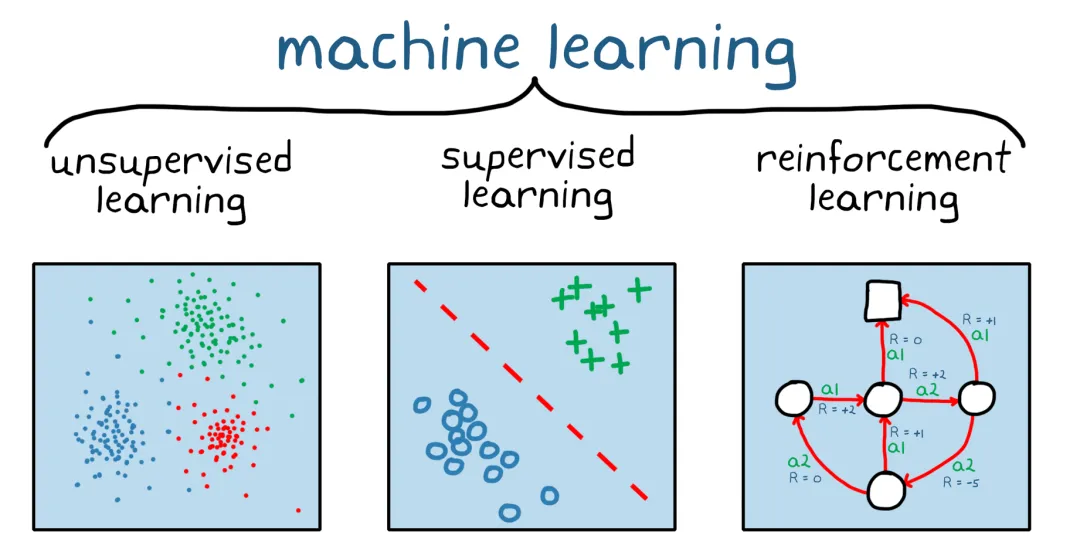
整合 200 多项相关研究,大模型「终生学习」最新综述来了
整合 200 多项相关研究,大模型「终生学习」最新综述来了该论文作者均来自于华南理工大学马千里教授团队,所在实验室为机器学习与数据挖掘实验室。论文的三位共同第一作者为博士生郑俊豪、硕士生邱圣洁、硕士生施成明,主要研究方向包括大模型和终生学习等,通讯作者为马千里教授(IEEE/ACM TASLP 副主编)。
来自主题: AI资讯
7286 点击 2024-09-01 15:57
 搜索
搜索
该论文作者均来自于华南理工大学马千里教授团队,所在实验室为机器学习与数据挖掘实验室。论文的三位共同第一作者为博士生郑俊豪、硕士生邱圣洁、硕士生施成明,主要研究方向包括大模型和终生学习等,通讯作者为马千里教授(IEEE/ACM TASLP 副主编)。

8月28日至30日,2024中国国际大数据产业博览会正在贵阳火热进行中。“产业链上下游的人都来了。”一位行业人士观察,与以往不同,这届数博会上,数据要素、智算基础设施建设,正在和智能化、大模型行业应用等一起成为被密集讨论的话题。

近日,创投数据服务商 IT桔子发布了《2024年中美独角兽公司发展分析报告》 。作为全球拥有独角兽企业数量最多的两个国家,对比中国和美国的独角兽在产业、估值、城市分布等维度的差异,分析他们的发展路径、轨迹,有着更重要的意义。
从几周前 Sam Altman 在 X 上发布草莓照片开始,整个行业都在期待 OpenAI 发布新模型。根据 The information 的报道,Strawberry 就是之前的 Q-star,其合成数据的方法会大幅提升 LLM 的智能推理能力,尤其体现在数学解题、解字谜、代码生成等复杂推理任务。这个方法也会用在 GPT 系列的提升上,帮助 OpenAI 新一代 Orion。
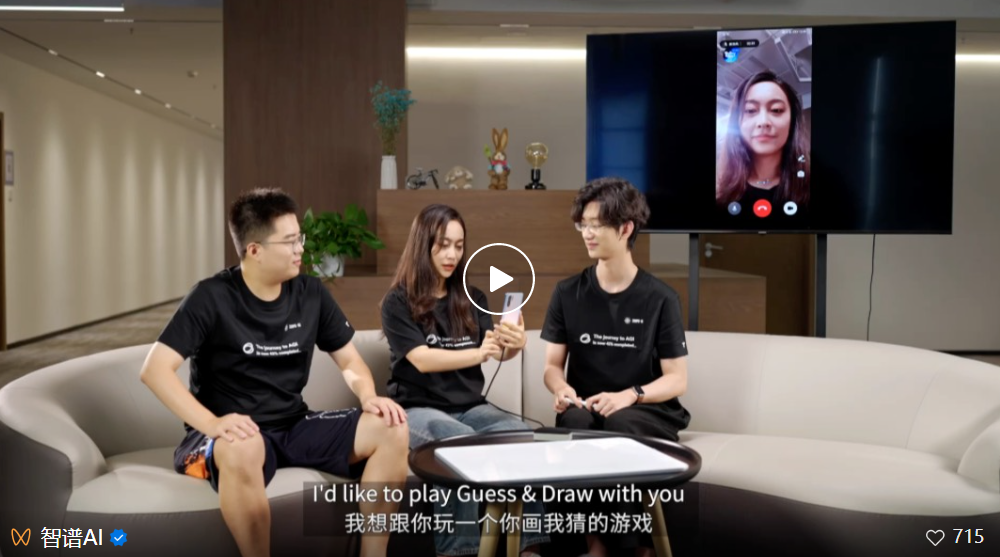
昨天,在 KDD 国际数据挖掘与知识发现大会上,智谱宣布「清言」App 迎来了重要更新,上线了「AI 视频对话功能」。

大摩认为,GPU供应仍然比较紧张,需求继续超过供应。过去6个月中H100租赁价格有所下降,但价格的绝对水平表明硬件的投资回报率非常高,回本期在一年以内。

本文的主要作者来自香港大学的数据智能实验室 (Data Intelligence Lab@HKU)。

最近,Meta的多个工程团队联合发表了一篇论文,描述了在引入基于GPU的分布式训练时,他们如何为其「量身定制」专用的数据中心网络。

OpenAI又憋大招了!据悉,下一代旗舰模型GPT-5或名为「猎户座」,由「草莓」合成的数据训练。而草莓具有极强的复杂推理(数学、编程)和语言能力,或将超越当前的任何模型的推理和生成的能力。

ACM SIGKDD(国际数据挖掘与知识发现大会,KDD) 会议始于 1989 年,是数据挖掘领域历史最悠久、规模最大的国际顶级学术会议,也是首个引入大数据、数据科学、预测分析、众包等概念的会议。