# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
深度强化学习(Deep Reinforcement Learning,DRL)是一种公认的解决连续决策问题的有效技术。为了应对 DRL 的数据低效(data inefficiency)问题,受到分布式机器学习技术的启发,分布式深度强化学习 (distributed deep reinforcement learning,DDRL) 已提出并成功应用于计算机视觉和自然语言处理领域。有观点认为,分布式强化学习是深度强化学习走向大规模应用、解决复杂决策空间和长期规划问题的必经之路。
分布式强化学习是一个综合的研究子领域,需要深度强化学习算法以及分布式系统设计的互相感知和协同。考虑到 DDRL 的巨大进步,我们梳理形成了 DDRL 技术的展历程、挑战和机遇的系列文章。我们在 part 1 部分回顾了经典的 DDRL 框架,在本部分,我们利用三篇论文,具体分析 DDRL 的今生 --- 最新研究进展。
1、SRL: Scaling Distributed Reinforcement Learning to Over TenThousand Cores [1] ICLR’24

本文为来自清华大学和上海期智研究院 Yi Wu(吴翼)教授研究团队的工作,该团队主要研究方向包括深度强化学习、多智能体学习、自然语言基础、大规模学习系统。本文已被 ICLR’24 录用。ICLR 是机器学习领域重要的学术会议质疑,每年举办一次。2024 年是第十二届,将于 5 月 7 日至 11 日在维也纳召开。据统计,本届会议共收到了 7262 篇论文,整体接收率约为 31%。
强化学习(RL)任务的复杂性与日俱增,需要分布式 RL 系统高效地生成和处理海量数据来训练智能 agent。然而,现有的开源库存在各种局限性,阻碍了它们在需要大规模训练的挑战性场景中的实际应用。尽管 OpenAI 和 DeepMind 的工业化系统已经成功实现了大规模 RL 训练,但它们的系统架构和实现细节仍未向社区公开。本文针对 RL 训练的数据流提出了一种新颖的系统抽象概念,它将不同应用中的实际 RL 训练统一到一个通用而灵活的框架中,并实现了细粒度的系统级优化。根据这一抽象概念,作者开发了一种 scalable、高效、extensible 的分布式 RL 系统,称为 ReaLly Scalable RL(SRL)。SRL 的系统架构分离了主要的 RL 计算组件,允许大规模并行化训练。作者还引入了一系列技术来进一步优化系统性能。此外,SRL 还提供用户友好和可扩展的界面,便于开发定制算法。本文评估表明,无论是在单机还是在中型集群中,SRL 的性能都优于现有的 libraries。在大规模集群中,SRL 的新型架构与现有 libraries 采用的设计相比,速度提高了 3.7 倍。
1.1 架构设计出发点
现有许多开源 RL 系统都为特定应用场景提供了解决方案。然而,其中只有少数是通用的 (general-purposed)。作者发现这些系统在架构设计和实现方面都有其局限性。
首先,在架构设计方面,大多数开源系统都对可用计算资源做了假设,如硬件加速器的类型和物理位置,以及可用计算设备之间的比例。因此,它们的架构倾向于紧密结合多个计算组件,并将其映射到物理上位于同一节点的设备上。因此,在定制的本地集群中部署时,这可能会损害系统性能。例如,Sample Factory [4] 和 Rlpyt [5] 专门用于在本地机器上进行 RL 训练,不假定分布式计算资源是可用的。其他考虑到分布式设置的库通常可分为两类:IMPALA -style [6] 和 SEED -style [7]。
以 RLlib 和 ACME 为代表的 IMPALA -style 架构(图 1 顶部)假定用于环境模拟和策略推断的计算资源之间存在紧耦合。在这种设置下,策略推断只能在与环境位于同一节点的 CPU 或 GPU 上进行。使用 CPU 进行策略模型推理本身效率就不高,而使用本地 GPU 进行推理也存在严重缺陷。根据应用场景的不同,环境模拟速度、观测值大小和策略模型大小的变化很容易造成本地 GPU 的推理空闲或过载,从而导致严重的资源浪费。此外,如果 agent 在多 agent 环境中遵循不同的策略,本地 GPU 必须维护多个策略模型,从而导致大量内存占用,并限制了该节点可容纳的环境数量。SEED-style 架构(图 1 下)主要假定有独立的 TPU 内核可用于训练和策略推理。然而,在使用 GPU 而不是多核 TPU 的情况下,要同时处理推理和训练会很吃力。此外,在使用异构 GPU 时,训练吞吐量会因梯度同步中的滞后而受到限制。

图 1. RLlib/ACME(上)和 SeedRL(下)的实现,采用 IMPALA/SEED-style 架构。前者将环境模拟和策略推理合并在一个线程中,后者则将策略推理和训练合并在一个 GPU 上。请注意,在 SEED -style 中,运行环境模拟的 GPU 节点依靠训练 GPU 节点进行策略推断,而在 IMPALA -style 中,它们依靠本地 CPU/GPU 进行策略推断
其次,考虑到实现问题,开源的分布式系统无法在多个节点上扩展训练,这可能会阻碍需要复杂策略和大批量的复杂任务的 RL 训练。具体来说,RLlib 和 ACME 只能分别通过 Python threaded trainer1 和 jax.pmap2 支持本地多 GPU 训练,而 SeedRL 只能在单 GPU 上运行。
第三,开源库主要集中于中小型规模,导致实施简化,对细粒度性能优化的考虑有限。因此,这些系统导致训练吞吐量低下,尤其是在大规模场景中。通过对它们的设计和实现进行分析,作者发现了几种可能的优化方法,能够显著提高系统性能。应用这些修改后,训练吞吐量有了显著提高,从而使 SRL 的性能大大超过了现有系统。
此外,尽管现有的一些开源库提供了通用接口,允许用户定制环境和 RL 算法(如 RLlib),但它们的算法实现与其系统 API 紧密相连。这些系统提供的用户友好界面可以扩展系统组件,这就限制了它们与复杂 RL 算法的兼容性,因为这些算法要求的计算量超出了主要 RL 计算组件的范围。
主要 RL 计算组件包括:1)环境模拟(Environment simulation)根据 actions 产生观察结果和奖励。这种计算通常使用外部黑盒程序执行,如游戏或物理引擎,通常在 CPU 上执行;2)策略推理(Policy inference)从观察中生成 actions,观察是通过神经网络策略的推理(也称为前向传播)进行的。该系统可以使用 CPU 或 GPU 设备进行策略推理,尽管在采用 GPU 时可能具有明显的性能优势;3)训练(Training)使用收集的轨迹在 GPU 上执行梯度下降迭代以改进策略。
目前,人们正在努力解决这些限制。MSRL [8] 采用一种编译方法,将本地运行的用户代码转换为 "片段",这些 "片段" 由一组标记边界和定义数据流的 "注释" 划分。然而,与 SRL 相比,这种方法有其缺点。首先,MSRL 可编译的计算和通信应用程序接口受到很大限制,这套应用程序接口只能支持经典的 RL 算法(如 DQN 和 PPO),用户无法对其进行扩展。其次,MSRL 在实现过程中没有考虑系统级计算优化,导致训练效率大大降低。第三,MSRL 在将用户端实现分解为可执行的 "片段" 时,会遵循一组预先确定的调度计划。但是,这些调度计划仍然沿用现有的架构(即 IMPALA/SEED-style),只能满足特定 RL 应用的需要。
最后,表 1 给出了一系列 SRL 的对比方法的工作能力。作者表示,据他们所知,SRL 是第一个能提供所有所需特性(包括可扩展性、效率和可扩展性)的学术系统。

表 1. 开源 RL 系统实施能力
1.2 SRL 架构
1.2.1 SRL 的 high-level 设计
为了解决以往设计的局限性,作者对 RL 训练的数据流提出了一种新的抽象。在该抽象中,SRL 由多个相互连接的 "workers" 组成,这些 workers 承载着不同的 "任务处理程序",如环境和 RL 算法。这些 workers 通过数据 "流" 连接,并由后台 "服务" 提供支持。基于这个简单的抽象概念,作者开发了 SRL 架构,如图 2 所示。
SRL 包含三种核心 worker 类型:actor worker、policy worker 和 trainer worker,他们负责 RL 训练任务中的三项关键工作。
Actor worker 向 policy worker 发出包含观察结果的推理请求,policy worker 通过生成的行动做出响应。作者将这种 client-server 通信模式抽象为推理流。在进行环境模拟的同时,actor worker 会在本地缓冲区中积累 observation-action-reward 三元组,并定期将它们发送给 trainer worker。作者将这种推拉通信模式抽象为样本流。每个训练步骤结束后,更新的参数会被推送到参数服务器,该服务器会处理 policy worker 为参数同步而提出的拉取请求。
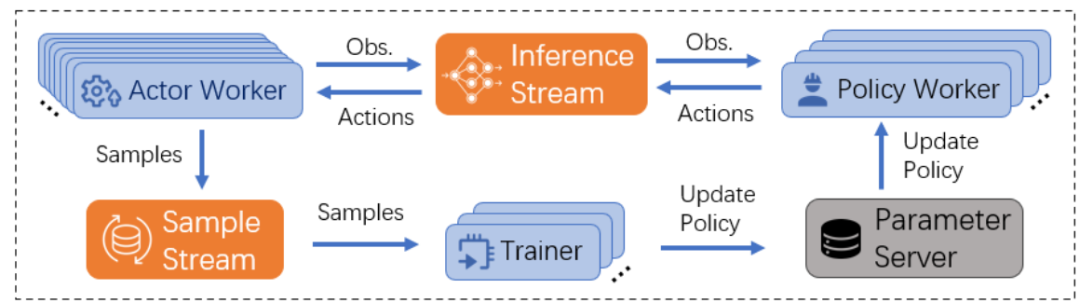
图 2. SRL 的核心组件。蓝色箭头表示 worker 和数据流之间的 dataflow。蓝色方框代表负责计算工作负载的 worker。橙色方框代表数据流,负责 worker 之间的通信。灰色方框代表服务,也就是本文提及的参数服务器
与以往的设计不同,SRL 中的所有 worker 都可以独立调度,并分布在多台拥有异构资源的机器上,从而在各种资源设置(包括本地机器和大型集群)下实现大规模并行和高效的资源利用。如图 3 所示,作者将抽象化的 worker 实例化为不同计算节点上的进程,并将数据流实例化为套接字或共享内存块。每个工作进程都会分配到适合其任务的特定数量的计算资源,工作进程通过最有效的可用接口进行连接,这种接口可以是用于节点间通信的网络接口,也可以是用于进程间通信的共享内存接口。
因此,SRL 的新型架构不仅以清晰的设计和实现统一了现有的本地和分布式架构,还能在现有架构无法实现的场景中实现高效的调度、资源分配和数据通信。此外,SRL 清晰的设计实现了细粒度的性能优化,与现有库相比,即使使用相同的架构,速度和可扩展性也有显著提高。此外,高级抽象还产生了一个简洁的用户界面,使扩展现有 RL 算法和定制 worker 变得更加容易。
1.2.2 SRL 的系统组件
要说明的是,以下内容假定了大多数流行的 RL 算法的典型工作流程,以便清楚地介绍这些算法。确实有一些 RL 算法需要更复杂的系统设计。SRL 也可以轻松支持这些不寻常的算法。
1.2.2.1 actor worker 和 policy worker。actor worker 负责托管环境,处理黑盒环境程序的执行。环境模拟通常独立于每个 actor,因此在计算资源充足的情况下,可以直接进行大规模并行化。另一方面,policy worker 托管 RL agent(或策略),并为 actor worker 提供批量推理服务。它们可以有效利用 GPU 设备来加速神经策略的前向传播。环境模拟通常分为几个阶段。在每一阶段的开始,actor worker 会重置其环境并获得第一个观测值。然后,在每一个环境步骤之前,每个 actor worker 都会发送上一个步骤(或初始重置)的观察结果,并请求 policy worker 采取行动,以继续下一个步骤。
Actor Worker 本身就是为多 agent 而设计的,例如:(1) 不同的 Actor Worker 可以容纳不同数量的 agent;(2) agent 可以异步浏览环境(如果环境返回 "无",则跳过);(3) agent 可以通过连接不同的流来应用不同的策略。这种灵活的设计使 SRL 能够处理更复杂、更现实的应用场景。
policy worker 会 flush 从多个 Actor Worker 处接收到的推理请求,用批量观测结果计算策略模型的前向传递,并用输出行动对其做出响应。为了使策略模型保持最新,policy worker 还需要不时地从参数服务器获取参数。数据传输、参数同步和神经网络推理由三个不同的线程处理。我们注意到,在某些情况下,例如没有 GPU 设备可用或网络带宽非常有限时,在单独的机器上启动 policy worker 可能并不可取。policy worker 实现还支持本地 CPU 模式,作者称之为 inline inference。在这种情况下,推理流模块将确保在 actor 与其相关本地 policy worker 之间直接传输数据,并进行适当的批处理,而无需使用网络。虽然 inline inference 模式在概念上与 RLlib 和 ACME 相似,但在不同的硬件支持下,Actor Worker 和 policy worker 的实现方式保持不变,从而提高了实际使用的灵活性。
1.2.2.2 Trainer workers。Trainer workers 负责计算梯度下降迭代。它们接收来自 actor worker 的样本。每个 Trainer workers 都嵌入了一个缓冲区,用于存储等待被提取到 GPU 的样本。在每次梯度下降迭代之前,Trainer workers 都会从数据缓冲区汇总一批样本,并将其加载到 GPU 设备中。CPU 和 GPU 上的工作分为两个线程。
SRL 支持跨节点的多 GPU 训练。通过 multi-GPU 训练设计,每个 Trainer workers 都被精确分配到一个 GPU 设备上,这意味着一个 Trainer workers 是训练计算的最小单位。需要注意的是,RL 中的策略模型通常很小(见表 2),因此在大多数应用中不需要模型并行化。因此,作者在 multi-trainer 设计中采用了单程序多数据(single-program multi-data,SPMD)模式。对于一大批样本,作者将样本平均分配给多个 trainer,每个 trainer 都有一份相同的策略模型。每个 trainer 使用自己的副本计算梯度,并在每次训练迭代结束时同步梯度,更新最终策略模型。Trainer workers 使用 PyTorch 分布式数据并行( Distributed Data Parallel,DDP)作为后端,与 trainer 进行通信并同步梯度。此外,在某些情况下,单个 trainer 可能无法充分利用 GPU 的计算能力。为了防止不必要的计算能力浪费,作者允许其他 worker(如 policy worker)与 trainer worker 共享一个 GPU。

表 2.RL 与监督学习的模型大小对比
1.2.2.3 样本流和推理流。SRL 确定了 workers 之间两种最基本的数据传输类型。一种是在 actor worker 和 policy worker 之间交换观察结果和行动;另一种方法是将样本从 actor worker 发送给 trainer worker。与这两类数据传输相对应,作者开发了推理流和样本流,它们具有不同的数据传输模式。推理流需要是双工的,因为 actor worker 会发送推理请求,而 policy worker 则需要回复。同时,样本流是单工的。只有 actor worker 向 trainer worker 发送训练样本,而 trainer worker 无需回复。
对于网络传输,作者将推理流作为一对 request-replay socket 来实现,将样本流作为一对 push-pull sockets 来实现。对于本地共享内存传输,作者将推理流实例化为一个固定的共享内存块,即为每个客户端分配一个读写槽,将样本流实例化为一个精心设计的共享内存 FIFO 队列。
作者还讨论了数据流的一些特殊用例。在某些 RL 应用(如多 agent RL 和基于群体的训练)中,需要在一次训练实验中训练多个策略模型。这表明,不同的 actor worker 需要与持有特定策略模型的特定 policy worker 和 trainer worker 群体进行通信。因此,一个实验中可能需要多个样本流和推理流实例。不同的数据流在各组 worker 之间建立独立的、可能重叠的通信,以确保来自不同策略的数据不会相互污染。
1.2.2.4 参数服务器。在 RL 训练中,用于训练的策略模型和策略推理需要定期同步。在 SRL 中,参数服务器是策略模型的中间站。一段时间后,trainer workers 会向参数服务器推送更新版本的策略模型。policy worker 会偶尔检查参数服务器中策略模型的版本。如果参数服务器存储了更新的版本,policy worker 就会立即调用模型。由于与监督学习相比,RL 应用中的大多数策略模型规模并不大(见表 2),因此参数服务器通常不会成为 SRL 的瓶颈。作者提供了两种参数服务器实现,一种基于 NFS,另一种运行后台服务线程,向每个节点广播更新的参数,供 policy worker 查询。根据作者的经验,NFS 变体的吞吐量足以满足常用需求,因此作者在所有实验中都采用了 NFS 变体。
1.2.2.5 控制器 。在 SRL 中,实验表示一个完整的 RL 训练任务,需要在有多个节点的大型集群上运行。图 3 显示了使用 SRL 在集群上运行实验的步骤。作者将整个实验运行分为以下 5 个步骤:
(1) 用实验配置启动控制器并应用资源。
(2) 使用资源管理器分配资源。
(3) 使用控制器启动和配置 worker。
(4) worker 连接数据流并运行任务。
(5) 完成实验后,停止 worker。
在此过程中,控制器是一个关键组件。它从资源管理器分配资源,处理实验配置,管理 worker 和数据流的生命周期。它的实现分为两个部分。第一部分是资源管理器服务的客户端(作者使用 slurm [9] 作为集群中的资源管理器)。第二个是 RPC 客户端,用于启动 Worker(作为 RPC 服务器)并向 Worker 发送请求。

图 3. 在集群上运行 SRL 实验。圆圈中的数字代表此过程中的步骤
1.2.3 用户友好型和可扩展设计
除了可扩展性强和效率高之外,SRL 还提供用户友好和可扩展的界面,允许在其框架内开发和执行定制的环境、策略、算法和架构。SRL 中的策略和算法与系统设计相分离,允许用户开发新的变体,而无需使用任何与系统相关的接口。作者在代码 1 中演示了一个具体实例。要实现 Deep Q-Network,用户只需编写一个策略文件(用于定义策略在数据收集和训练过程中的行为)和一个算法文件(用于指定如何计算从策略中获取的数据的标量损失)。这些文件可以完全独立于现有的算法实现和系统应用程序接口,这样用户就可以专注于算法开发,而不必被繁重的系统代码所困扰。

Code 1:简化深度 Q-learning 的 Python 示例。用户无需了解任何与系统相关的 API,即可编写新的神经网络模型和 RL 算法
此外,SRL 还为新 workers 和数据流提供了多种配置选项和通用接口,便于完全定制数据流和算法模块。作者在 Code 2 和 Code 3 中介绍了两个实际例子。第一个实例描述了这样一种情况:环境返回的奖励必须使用预先训练好的(大型)神经网络模型来计算,而不是程序本身。通过 SRL,用户可以创建一个额外的哨兵 agent 来计算奖励。该 agent 与另一个推理流和 policy worker 相连,而推理流和 policy worker 是奖励模型的主机。每个环境步骤结束后,真实 agent 返回 "无",哨兵 agent 发出奖励计算推理请求。奖励返回后,哨兵 agent 返回 "无",真实 agent 返回下一步观察结果和计算出的奖励,以推进环境模拟。在第二个例子中,SRL 使附加计算模块的实施成为可能,该模块支持对先前生成的样本进行定期再处理。虽然该模块不属于图 1 中描述的主要计算组件,但用户可以通过继承基本 Worker 类并覆盖 Worker 的执行步骤来轻松创建一个自定义的 BufferWorker,以执行此类计算。这种基于 Worker 的自定义功能进一步促进了框架内复杂 RL 训练例程的开发。

图 4. 强化学习的 Vanilla 实现

Code 2:在托管大型预训练模型的远程 policy worker 中计算奖励的配置示例

Code 3:SRL 中的工作程序接口(Worker API)和用于数据再处理的定制缓冲工作程序的实施
此外,作者还提出了一些优化 SRL 的方法,感兴趣的读者可以阅读原文。
1.3 实验分析
作者对 SRL 进行实证评估,重点关注两个关键指标:训练吞吐量和学习性能。训练吞吐量指的是系统每秒处理梯度更新样本帧的速度,而学习性能则衡量生成最优解所需的 wall-clock 时间。实验在两种资源设置下进行评估(所有物理内核都启用了超线程功能,并作为 2 个逻辑内核计算):
(1) 本地单机设置:32 个物理 CPU 内核、512GB DRAM 和一个 Nvidia 3090 GPU。
(2) 分布式集群设置:4 个节点,64 个物理 CPU 内核和 8 个 Nvidia A100 GPU + 64 个节点,128 个物理 CPU 内核和一个 Nvidia 3090 GPU。集群中的每个节点都有 512GB DRAM,并通过 100 Gbps 集群内网络相互连接。集群的存储通过 NFS 和参数服务实现,所有节点均可使用。
1.3.1 训练吞吐量
作者比较了 SRL 与基线方法在本地和分布式环境下的性能。使用的评估指标是每秒训练环境帧数 (FPS),即所有 trainer worker 每秒消耗的环境帧数。作者在一组学术环境中进行了实验,包括 Atari 2600 游戏(Atari)(游戏 Pong)、Google Research Football(gFootball)(场景 11_vs_11)、StarCraft Multi-Agent Challenge(SMAC)(地图 27m_vs_30m)和 Deepmind Lab(场景 watermaze),每种环境在观察类型、速度、内存等方面都具有不同的特点(见表 3)。在 Atari 和 DMLab 环境中,作者采用传统的 4 帧剪辑设置,即环境帧数为实际训练样本步数的 4 倍。

表 3. 选用的环境参数
在单机环境下,作者选择 Sample Factory、rlpyt 和 SeedRL 作为基线。Sample Factory 和 rlpyt 都是专门针对单机场景优化的系统。SeedRL 最初是为分布式环境中的 TPU 训练而设计的。然而,即使是一台机器生成的样本,也很容易使其单个 "learner" 不堪重负。因此,只在单机环境下对 SeedRL 进行了评估。图 5 显示,SRL 在 Atari 上表现优异,与基线中表现最好的 Sample Factory 相比,SRL 实现了近 30% 的加速。在其他环境下,SRL 的表现与 Sample Factory 相似或略胜一筹。至于 MSRL [8],结果显示,在相同的实验设置下,SRL 与 MSRL 相比,训练 FPS 可达到 2.52 倍。

图 5. 在大规模集群中使用三种不同配置的 SRL 训练 FPS,最多使用 32 个 Nvidia A100 GPU、32 个 Nvidia Geforce RTX 3090 GPU 和 12800 个 CPU 内核。配置 1:解耦 worker。每个 trainer worker 拥有一个 A100 GPU,4 个 policy worker 共享一个 RTX 3090 GPU。配置 2:trainer worker 和 policy worker 耦合。一个 trainer worker 和 4 个 policy worker 共享一个 A100 GPU。配置 3:耦合 actor worker 和 policy worker(inner inference)。trainer worker 有一个 A100 GPU。推理由 CPU 内核完成
1.3.2 学习性能
对 SRL 的训练吞吐量进行量化有助于深入了解其效率和可扩展性,但同样重要的是,要评估 SRL 在现实和具有挑战性的环境中开发智能 agent 的能力(即学习性能)。在这种情况下,捉迷藏( hide-and-seek,HnS)环境是一个很有吸引力的选择。如图 6a 所示,捉迷藏(HnS)环境模拟了一个物理世界,其中有 2-6 个 agent,包括 1-3 个躲藏者和 1-3 个寻找者,以及各种物理对象,包括 3-9 个盒子、2 个斜坡和随机放置的墙壁。Agents 可以通过移动或锁定箱子和斜坡来操纵它们,而锁定的物体只能由队友来解锁。每局游戏开始时,都会有一个准备阶段,在这一阶段中,寻找者不能移动,这样躲藏者就可以利用现有物品建造一个庇护所,以保护寻找者。准备阶段结束后,如果寻找者中有人能发现躲藏者,他们就会获得 + 1 的奖励,反之则为 - 1。躲藏者获得的奖励符号相反。图 6b 显示了整个学习过程的奖励。由于 agent 与对象之间的交互是 non-trival 的,而且任务也很复杂,因此观察这种行为演化需要极大的批次规模,例如单个批次中需要 320k 个交互步骤。作者尽了最大努力在这种环境下运行基线系统,但没有一个系统能处理如此大规模的训练任务。

图 6. (a) HnS 的快照。(b) HnS 中的奖励。agent 行为分为四个阶段:奔跑和追逐、箱子锁定、斜坡使用和斜坡锁定
作者在分布式环境中使用 inline CPU 推理(简称 CPU Inf.)和远程 GPU 推理(简称 GPU Inf.)进行实验。在 CPU Inf. 推理中,将每个训练器的 actor worker 数量固定为 480 个,每个 actor worker 有一个单独的环境;在 GPU Inf. 推理中,将每个 actor worker 的数量固定为 120 个,每个 actor worker 有一个大小为 20 的环境环。另外,GPU Inf. 使用 8 个 policy worker 和一个 trainer,占用两个 3090 GPU。在实验中,作者展示了在 HnS 中实现斜坡锁定阶段所需的训练时间和数据量,如图 7 所示。结果显示,SRL 比具有相同架构(CPU Inf.)的 Rapid 系统快达 3 倍,而 GPU Inf. 则可在进一步减少时间和环境交互的情况下实现高达 5 倍的加速。作者将训练效率的提高归因于两个原因。首先,SRL 设计比 Rapid 更高效,FPS 也更高。其次,本文灵活的系统设计和细粒度的优化确保了 RL 算法的效率受网络延迟和过时数据等各种系统相关因素的影响较小,从而即使使用相同的 RL 算法,也能提高采样效率。

图 7. 达到 HnS 第四阶段所需的时间 / 数据
2、Parallel Q-Learning: Scaling Off-policy Reinforcement Learning under Massively Parallel Simulation [2] ICML’23

本文为 MIT 电气工程与计算机科学系研究员 Pulkit Agrawal 研究团队的研究成果,该团队还曾经获得 CoRL 2021 的最佳论文奖。本文发表在 ICML’23 中。ICML 是计算机人工智能领域的顶级会议,ICML 2023 是第 40 届,共收到 6538 份投稿,有 1827 份被接收,录用率为 27.9%。
由于需要大量的训练数据,强化学习对于复杂任务来说非常耗时。基于 GPU 的物理仿真技术的最新进展,如 NVIDIA Isaac Gym,已将 commodity GPUs 上的数据收集更新速度提高了数千倍。由于 PPO 等 on-policy 方法简单且易于扩展,之前的大多数研究都采用了这种方法。off-policy 方法的采样效率更高,但难以扩展,导致 wall-clock 训练时间更长。
本文提出了一种 parallel Q-learning(PQL)方案,它在 wall-clock 时间方面优于 PPO,并保持了卓越的采样效率。其关键点在于数据收集、策略函数学习和值函数学习的并行化。与 Apex 等之前的分布式 off-policy 方法不同,本文方案专为基于 GPU 的大规模并行仿真而设计,并针对在单个 worker 上的运行进行了优化。在实验中,作者展示了将 Q-learning 方法扩展到数万个并行环境的能力,并研究了影响学习速度的重要因素,包括并行环境数量、探索策略、批大小、GPU 模型等。本文方法代码已发布在 https://github.com/Improbable-AI/pql。
2.1 方案架构
PQL 可以在单个 GPU 上同时仿真数千个环境。在典型的 actor-critic Q-learning 方法中,有三个组件依次运行:策略函数、Q 值函数和环境。agent 在环境中执行策略并收集交互数据,这些数据被添加到重放缓冲区;然后,更新值函数以最小化贝尔曼误差,之后更新策略函数以最大化 Q 值。这种顺序方案会减慢训练速度,因为每个组件都需要等待其他两个组件完成后才能继续。
为了最大限度地提高学习速度并减少等待时间,作者将三个部分的计算并行化。这使得每次数据收集可以更新更多网络,从而提高海量数据的利用率,并提高训练速度。off-policy RL 方法非常适合并行化,因为重放缓冲区中的交互数据不需要来自最新的策略。相比之下,PPO 等 on-policy 方法需要使用最新策略的推出数据(on-policy 数据)来更新策略,因此数据收集和策略 / 值函数更新的并行化并非易事。本文方案以 wall-clock 时间为单位对训练速度进行了优化,可以在 worker 上轻松应用。该方案基于 DDPG [10],但也可轻松扩展到其他 off-policy 算法,如 SAC [11]。
本文方案还采用了用于提高 Q-learning 性能的常用技术,如 double Q learning 和 n-step returns。作者还尝试在 PQL 中添加分布式 RL,称之为 PQL-D。虽然它提高了高难度操作任务的性能,但却导致 RL agent 的收敛速度略有下降。本文使用以下符号:在时间步长 t,s_t 表示观测数据,a_t 表示行动指令,r_t 表示奖励,d_t 表示环境是否终止,π(s_t) 表示策略网络,Q (s_t, a_t) 表示 Q 网络,Q′(s_t, a_t) 表示目标 Q 网络,N 表示并行环境的数量。
如图 8 所示,PQL 将数据收集、策略学习和价值学习并行化为三个过程。作者将它们分别称为 Actor、策略学习者(P-learner)和价值学习者(V-learner)。

图 8. PQL 概述。三个并发进程在运行:Actor、P-learner、V-learner。Actor 收集交互数据。P-learner 更新策略网络。V-learner 更新 Q 函数
该方案的伪代码如算法 1、2 和 3。



数据传输。假设 Actor 进程中有 N 个并行环境。在每个推出步骤中,Actor 都会推出策略 π^a (s_t),并生成 N 对 (s_t, a_t, s_t+1, r_t, d_t+1)。然后,Actor 将整批交互数据 {(s_t, a_t, s_t+1, r_t, d_t+1)} 发送给 V-learner(如图 8 所示)。由于 P-learner 中的策略更新只需要状态信息,因此 Actor 只需向 P-learner 发送 {(s_t)} 即可。
网络传输 。V-learner 定期向 P-learner 发送 Q^v_1 (s_t, a_t) 的参数,P-learner 更新 P-learner 中的本地 Q^p (s_t,a_t)。P-learner 将策略网络 π^p (s_t) 发送给 Actor 和 V-learner。数据传输和网络传输同时进行。
2.2 Actor, P-learner, and V-learner 之间的均衡
本文方案允许 Actor、P-learner 和 V-learner 同时运行。不过,需要适当限制数据收集、策略网络更新和价值网络更新的频率。换句话说,每个进程都不应该以最快的速度单独运行。作者对这三个频率添加了明确的控制,并定义了如下两个比率:

其中,f_a 是 Actor 中单位时间内每个环境的推出步数,f_v 是 V-learner 中单位时间内 Q 功能更新的次数,f_p 是 P-learner 中单位时间内策略更新的次数。β_a:v 决定当 Actor 在 N 个环境中一步步推出策略时,V-learner 要执行多少次 Q 函数更新。β_p:v 决定当 P-learner 更新一次策略时,在 V-learner 中执行多少次 Q 函数更新。一旦设定了比例,就会监控每个进程的进度,并动态调整 Actor 和 P-learner 的速度,必要时让进程等待。
通过 β_a:v、 β_p:v 控制三个进程有三大优势。
2.3 Mixed Exploration
进一步,作者通过制定良好的探索策略来提高收敛性。过多的探索会使 agent 无法抓住有用的经验并迅速学习到好的策略,而过少的探索又无法为 agent 提供足够的良好交互数据来改进策略。要平衡探索和利用,往往需要大量的超参数调整或复杂的调度机制。在 DDPG 中,控制探索的一种常见做法是设置无相关零均值高斯噪声的标准偏差 σ,将该噪声添加到确定性策略输出中:

由于很难预测多少探索噪声是合适的,因此通常需要为每项任务调整 σ。我们能减轻调整 σ 的麻烦吗?本文的想法是,与其寻找最佳的 σ 值,不如尝试不同的 σ 值,作者称之为混合探索。即使在某个训练阶段,某些 σ 值会导致糟糕的探索结果,但其他 σ 值仍能生成良好的探索数据。由于大规模并行仿真,我们可以在不同的并行环境中使用不同的 σ 值,因此这一策略很容易实施。之前的研究也采用了类似的思路。本文在 [σ_min, σ_max] 的范围内均匀地生成噪声水平。对于 N 个环境中的第 i 个环境:

本文实验中的所有任务都使用了 σ_min = 0.05、σ_max = 0.8。
2.4 实验分析
作者证明了本文方法与 SOTA 基线方法相比的有效性,展示了影响学习的关键超参数的效果,并提供了设置这些值的经验指导。所有实验都是在一台配有少量 GPU 的工作站上进行的。作者在六项 Isaac Gym 基准任务中对本文方法进行了评估:Ant, Humanoid, ANYmal, Shadow Hand, Allegro Hand, Franka Cube Stacking(见图 9)。此外,还提供了另外两个任务:(1) 基于视觉的球体平衡任务;(2) 接触丰富的灵巧操作任务,该任务要求学习使用 DClaw Hand 调整数百个不同物体的方向,并采用单一策略。

图 9. 六项 Isaac Gym 基准任务
本文实验考虑了以下基线:(1) PPO,这是之前许多使用 Isaac Gym 进行模拟所使用的默认算法;(2) DDPG (n):采用 double Q-learning 和 n-step returns 的 DDPG 实现;(3)SAC (n):SAC [11] 的实现,有 n-step returns。本文实验中使用 NVIDIA GeForce RTX 3090 GPU 作为默认 GPU。
要回答的第一个也是最重要的问题是,PQL 是否比 SOTA 基线方法学习速度更快。为了回答这个问题,作者比较了 PQL 和 PQL-D(分布式 RL 的 PQL)与基线在六个基准任务上的学习曲线。如图 10 所示,与所有基线相比,本文方法(PQL、PQL-D)在六项任务中的五项都实现了最快的策略学习。此外,我们还观察到,在 PQL 中添加分布式 RL 可以进一步提高学习速度。
图 10 显示,在六项任务中,PQL-D 有五项任务的 wall-clock 时间比 PQL 更快,或至少与 PQL 相当。在两项富有挑战性的接触式操作任务中,PQL-D 的改进最为显著。此外,PQL 的学习速度快于 DDPG (n),这证明了使用并行方案进行数据收集和网络更新的优势。我们还发现,DDPG (n) 在所有任务中的表现都优于 SAC (n)。作者分析,这可能是由于 DDPG 中的探索方案比 SAC 中的探索方案能更好地扩展。在 DDPG 中,作者采用了与 PQL 相同的混合探索方法,而 SAC 的探索方法仅来自随机策略分布中的采样,这可能会受到策略分布质量的严重影响。

图 10. 将本文方法与 SOTA RL 算法(PPO、n-step returns SAC 和 n-step returns DDPG)进行了比较。在所有任务中都使用了 4096 个环境进行训练,只有 PPO 基线任务 "Shadow Hand" 和 "Shadow Hand" 除外
大规模并行仿真使我们能够在不同环境中部署不同的探索策略,从而生成更多样化的探索轨迹。作者使用一种简单的混合探索策略,并将其有效性与所有环境使用相同探索能力(相同的 σ 值)的情况进行比较。作者试验了 σ∈{0.2, 0.4, 0.6, 0.8}。如图 11 所示,σ 值的选择对学习性能影响很大。如果我们在所有并行环境中使用相同的 σ 值,那么我们就需要为每个任务调整 σ。相比之下,混合探索策略(即每个环境使用不同的 σ 值)的性能优于所有其他固定 σ 值的策略(学习速度更快或至少与之相当)。这意味着,使用混合探索策略可以减少每个任务所需的 σ 值调整工作。

图 11. 通过应用不同的恒定最大噪声值,对本文提出的混合探索方案进行比较。我们可以看到,混合探索方案要么优于其他方案,要么与其他方案相当,这可以节省噪声水平的调整工作
此外,作者还对比了不同参数设置情况下的方案效果,感兴趣的读者可以阅读原文。
3、ACTORQ: QUANTIZATION FOR ACTOR-LEARNER DISTRIBUTED REINFORCEMENT LEARNING

本文为来自哈佛大学、谷歌等机构研究人员的工作。本文提出了一种强化学习训练范式 ActorQ,用于加快 Actor-Learner 分布式 RL 训练。ActorQ 利用了对 learner 的全精度优化,以及通过低精度量化 actor 的分布式数据收集。对 actor 进行量化的 8 位(或 16 位)推理可加快数据收集速度,而不会影响收敛性。量化分布式 RL 在一系列任务(Deepmind 控制套件)和不同 RL 算法(D4PG、DQN)上训练系统 ActorQ 的端到端速度提高了超过 1.5 至 2.5 倍,收敛速度超过全精度训练。最后,作者分解了分布式 RL 训练的各种运行成本(如通信时间、推理时间、模型加载时间等),并评估了量化对这些系统属性的影响。
3.1 ActorQ 介绍
分布式强化学习系统采用标准的 "行动者 - 学习者"(actor-learner)方法:单个 learner 优化策略,多个 actor 并行执行 rollout 任务。由于 learner 执行的是计算密集型操作(对 actor 和 critic 进行批量更新),因此为其分配了更快的计算(在我们的例子中是 GPU)。另一方面,actor 执行单个推出,这涉及一次执行一个推理实例,其并行性受到限制;因此,它们被分配到单个 CPU 内核,彼此独立运行。Learner 持有策略的主副本,并定期将模型广播给所有 actor。Actor 提取模型并利用它来执行 rollouts,向重放缓冲区提交样本,learner 对其进行采样,以优化策略和 critic 网络。图 12 显示了 actor-learner 设置的示意图。

图 12. ActorQ 系统设置。在 learner 进程中利用 Tensorflow,在 actor 进程中利用 PyTorch,以促进用于优化的全精度 GPU 推理和用于经验生成的量化推理。作者引入了一个参数量化器,在 learner 的 Tensorflow 模型和 actor 的量化 PyTorch 模型之间架起了一座桥梁
本文引入了用于量化 actor-learner 训练的 ActorQ。ActorQ 包括在 actor 上使用量化执行的同时,保持 learner 所有计算的全精度。当 learner 广播其模型时,会对模型进行训练后量化,actor 会在其广播中使用量化后的模型。在实验中,作者测量了 learner 提供的全精度策略的质量。ActorQ 的几个考虑包括:
ActorQ 虽然简单,但却有别于传统的量化神经网络训练,因为 Actor 的纯推理角色可以使用精度很低(≤ 8 位)的算子来加速训练。这与传统的量化神经网络训练不同,传统的量化神经网络训练必须使用更复杂的算法。这增加了额外的复杂性,也可能限制速度,而且在许多情况下,由于收敛问题,仍仅限于半精度运算。ActorQ 的好处是双重的:不仅加快了 actor 的计算速度,还大大减少了 learner 与 actor 之间的交流。此外,在这一过程中,训练后量化可以被视为向 actor rollout 注入噪声。作者证明在某些情况下,这甚至会有利于收敛。最后,ActorQ 适用于许多不同的强化学习算法,因为 Actor-learner 范式适用于各种算法。
3.2 实验介绍
作者将 PTQ 应用于通过 ActorQ 进行的分布式强化学习训练中,并展示了在不损害收敛性的情况下显著提高了终端训练速度。作者评估了在分布式强化学习训练中量化通信与计算的影响,并分解了训练中的运行时间成本,以了解量化如何影响这些系统组件。作者评估了 ActorQ 算法在各种环境下加速分布式量化强化学习的效果。总的来说,我们发现 1)使用 ActorQ,训练强化学习策略的速度明显加快(>1.5 -2.5 倍);2)即使 actor 执行 8 位量化处理,也能保持收敛。最后,作者分解了训练各部分的相对成本,以了解计算瓶颈在哪里。在 ActorQ 中,actor 执行的是量化执行,而 learner 的模型是全精度的,因此我们评估的是 learner 的全精度模型质量。

表 4. 在 Deepmind Control Suite 和 gym 的特定任务中,ActorQ 的时间和速度提升高达 95% 的奖励。与全精度训练相比,8 位和 16 位推理的速度提高了超过 1.5 -2.5 倍。作者在 DeepMind Control Suite 环境(non-gym)中使用 D4PG,在 gym 环境中使用 DQN
作者在 Deepmind 控制套件的一系列环境中对 ActorQ 进行了评估。作者选择的环境涵盖了各种难度,以确定量化对简单和困难任务的影响。表 5 列出了测试环境及其相应的难度和训练步数。每一 episode 的最长步数为 1000 步,因此每项任务的最高奖励为 1000(尽管不一定能达到)。作者根据任务的特征而不是像素进行训练。

表 5. 使用 ActorQ 评估的任务从易到难,以及相应任务所训练的步骤,以及在 actor 一侧拉动模型的频率
策略架构是具有 3 个大小为 2048 的隐藏层的全连接网络。作者在 actor 的策略网络输出中应用高斯噪声层,以鼓励探索;根据执行的 actor,sigma 在 0 到 0.2 之间均匀分配。在 learner 方面,critic 网络是一个 3 层隐藏网络,大小为 512。在连续控制环境中使用 D4PG 训练策略,在离散控制环境中使用 DQN 训练策略。所有实验都在单机设置上运行(但分布在 GPU 和单机的多个 CPU 上)。Learner 使用的是 V100 GPU,使用 4 个 actors(每个 actor 1 个内核),每个 actor 分配一个 IntelXeon 2.20GHz CPU 进行分布式训练。运行每个实验,至少取 3 次运行的平均值,并计算汇总运行的运行平均值(window=10)。
图 13 和表 4 中展示了使用 ActorQ 的最终训练速度提升。在几乎所有任务中,我们都看到 8 位和 16 位量化推理的显著提速。此外,为了提高可读性,我们估算了 fp32 最大得分的 95% 百分位数,并测量了 fp32、fp16 和 int8 达到此奖励水平的时间,计算了相应的速度提升。在人形机器人、站立和人形机器人上,使用较慢的模型拉动频率(1000)时,步行收敛速度明显较慢,因此作者在其训练中使用了更频繁的拉动频率(100)。频繁的拉动使 16 位推理变慢,以至于与全精度训练一样慢。

图 13. ActorQ 在各种 Deepmind 控制套件任务中使用 8 位、16 位和 32 位的端到端速度提升 推理(对 Learner 进行全精度优化)。与全精度基线相比,8 位和 16 位训练的端到端训练速度明显加快
图 14 展示了使用 ActorQ 的 episode 奖励与 actor 总步数收敛图。数据显示,无论在简单任务还是困难任务中,即使对 actor 进行 8 位和 16 位推理,收敛性也能大致保持。在 Cheetah、Run 和 Reacher、Hard 中,8 位 ActorQ 的收敛速度甚至更快,作者认为这可能是因为量化引入了噪声,而噪声可以被视为探索。

图 14. ActorQ 在各种 Deepmind Control Suite 任务中使用 8 位、16 位和 32 位 actor 推理(对 learner 进行全精度优化)时的收敛性。8 位和 16 位量化训练的收敛性与全精度训练相同或更好
对 actor 进行模型拉动的频率可能会对收敛性产生影响,因为它会影响用于填充重放缓冲区的策略的僵化程度;这在之前的研究中都有所体现,图 15 给出了一个具体示例。因此,作者探讨了在通信量大和计算量大的情况下量化通信与计算的效果。为了量化通信,作者将策略权重量化为 8 位,并通过将其打包成矩阵的方式进行压缩,从而将模型广播的内存减少了 4 倍。自然,在重通信的情况下,对通信进行量化会更有利,而在重计算的情况下,对计算进行量化会产生相对更多的奖励。图 16 显示了在重通信场景(频率 = 30)和重计算场景(频率 = 1000)中量化对通信和计算的增益的消减图。图中显示,在通信量大的情况下,量化通信的速度可提高 30%;相反,在计算量大的情况下,量化通信的影响很小,因为开销主要来自计算。由于本文的实验是在单个节点的多个内核上运行的(有 4 个 actors),因此通信的瓶颈较小。作者认为,在拥有更多 actors 的网络集群上,通信成本会更高。

图 15. 模型拉动频率会影响 actor 策略的僵化程度,并可能对训练产生影响

图 16. 在计算量大和通信量大的训练场景中,量化通信与计算的效果。q 是推理的精度;q_c 是通信的精度。注意 q=8 隐含地将通信量化为 8 比特
作者进一步细分了对单个 actor 的运行时间有贡献的各种组件。运行时间组件可细分为:步长时间、拉动时间、反序列化时间和加载状态支配时间。步长时间是指执行神经网络推理所花费的时间;拉动时间是指从查询 Reverb 队列中的模型到接收序列化模型权重之间的时间;反序列化时间是指反序列化模型字典所花费的时间;load_state_dict 时间是指调用 PyTorch load state dict 所花费的时间。图 16c 显示了在计算量大的情况下,32、16 和 8 位量化推理的组件运行时间的相对细分。如图所示,步长时间是主要瓶颈,而量化可显著加快步长时间。图 16d 显示了通信量大时的成本明细。在加快计算速度的同时,由于内存的减少,拉取时间和反序列化时间也因量化而大大加快。
在 8 位和 16 位量化训练中,PyTorch 加载状态判定的成本要高得多。调查显示,加载量化 PyTorch 模型的成本是将权重从 Python 对象重新打包到 Cdata 中。由于内存访问次数较少,8 位权重重新打包明显快于 16 位权重重新打包。模型加载的成本表明,通过对打包的 C 数据结构进行序列化并降低权重打包的成本,可以获得额外的速度提升。为了证明量化在部署强化学习策略方面的显著优势,作者还评估了机器人应用案例中的量化策略优势,感兴趣的读者可以阅读原文。
4、文章小结
本文通过详细分析三篇近期论文,探索了分布式强化学习算法的今生 --- 最新研究进展。分布式强化学习侧重于研究强化学习低采样效率的问题,嵌入并行计算以高效加速模型训练过程并提高学习效果。与本系列文章 Part1 部分介绍的 “使用异步架构,在提升样本吞吐量的同时,引入一些 off-policy 修正” 的经典架构相比,part2 部分最新的研究方法更细粒度的考虑 RL 计算组件的离散化、协同化,也考虑了基于 GPU 的大规模并行仿真。
近几年,分布式强化学习的发展速度非常快,相关的论文发表数量也非常多,更加强调深度强化学习算法和分布式系统设计的互相感知和协同,学习性能更高、计算成本逐渐降低。我们也会持续跟踪关注分布式强化学习方面的最新进展。
参考引用的文献:
[1] SRL: Scaling Distributed Reinforcement Learning to Over Ten Thousand Cores, https://arxiv.org/pdf/2306.16688.pdf
[2] Parallel Q-Learning: Scaling Off-policy Reinforcement Learning under Massively Parallel Simulation, https://openreview.net/pdf?id=4aECnTuPEq
[3] ACTORQ: QUANTIZATION FOR ACTOR-LEARNER DISTRIBUTED REINFORCEMENT LEARNING, https://zishenwan.github.io/publication/ICLR2021.pdf
[4] Aleksei Petrenko, Zhehui Huang, Tushar Kumar, Gaurav S. Sukhatme, andVladlen Koltun. 2020. Sample Factory: Egocentric 3D Control from Pixels at100000 FPS with Asynchronous Reinforcement Learning. CoRR abs/2006.11751 (2020). arXiv:2006.11751 https://arxiv.org/abs/2006.11751
[5] Adam Stooke and Pieter Abbeel. 2019. rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch. CoRR abs/1909.01500 (2019). arXiv:1909.01500http://arxiv.org/abs/1909.01500
[6] Lasse Espeholt, Hubert Soyer, Rémi Munos, Karen Simonyan, Volodymyr Mnih,Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg,and Koray Kavukcuoglu. 2018. IMPALA: Scalable Distributed Deep-RL withImportance Weighted Actor-Learner Architectures. CoRR abs/1802.01561 (2018).arXiv:1802.01561 http://arxiv.org/abs/1802.01561
[7] Lasse Espeholt, Raphaël Marinier, Piotr Stanczyk, Ke Wang, and Marcin Michalski. 2019. SEED RL: Scalable and Efficient Deep-RL with Accelerated CentralInference. CoRR abs/1910.06591 (2019). arXiv:1910.06591 http://arxiv.org/abs/1910.06591
[8] Huanzhou Zhu, Bo Zhao, Gang Chen, Weifeng Chen, Yijie Chen, Liang Shi,Yaodong Yang, Peter Pietzuch, and Lei Chen. 2022. MSRL: Distributed Reinforcement Learning with Dataflow Fragments. arXiv:2210.00882
[9] Andy B. Yoo, Morris A. Jette, and Mark Grondona. 2003. SLURM: Simple Linux Utility for Resource Management. In Job Scheduling Strategies for Parallel Processing, Dror Feitelson, Larry Rudolph, and Uwe Schwiegelshohn (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 44–60.
[10] Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., and Wierstra, D. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015.
[11] Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pp. 1861–1870. PMLR, 2018.
[12] Makoviychuk, V., Wawrzyniak, L., Guo, Y., Lu, M., Storey, K., Macklin, M., Hoeller, D., Rudin, N., Allshire, A., Handa, A., et al. Isaac gym: High performance gpu-based physics simulation for robot learning. arXiv preprint arXiv:2108.10470, 2021
[13] Horgan, D., Quan, J., Budden, D., Barth-Maron, G., Hessel, M., Van Hasselt, H., and Silver, D. Distributed prioritized experience replay. arXiv preprint arXiv:1803.00933, 2018.
文章来自微信公众号 “ 机器之心 ”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
