
顶刊TPAMI|多模态视频理解领域重磅数据更新:MeViSv2发布
顶刊TPAMI|多模态视频理解领域重磅数据更新:MeViSv2发布近日,多模态视频理解领域迎来重磅更新!由复旦大学、上海财经大学、南洋理工大学联合打造的 MeViSv2 数据集正式发布,并已被顶刊 IEEE TPAMI 录用。
来自主题: AI技术研报
10338 点击 2025-12-29 09:07
 搜索
搜索
近日,多模态视频理解领域迎来重磅更新!由复旦大学、上海财经大学、南洋理工大学联合打造的 MeViSv2 数据集正式发布,并已被顶刊 IEEE TPAMI 录用。

案情显示:刘某在某科技公司负责传统人工地图数据采集业务多年。2024年初,公司决定全面转向AI主导的自动化数据采集,撤销了刘某所在部门及对应岗位。2024年年底,公司以“劳动合同订立时所依据的客观情况发生重大变化,致使劳动合同无法继续履行”为由,解除与刘某的劳动合同。

为了促进人工智能拟人化互动服务健康发展和规范应用,依据《中华人民共和国民法典》《中华人民共和国网络安全法》《中华人民共和国数据安全法》等法律法规,国家互联网信息办公室起草了《人工智能拟人化互动服务管理暂行办法(征求意见稿)》

福布斯400新晋最年轻富豪——Edwin Chen,美裔华人,年仅37岁。在Edwin看来,在我们的世界里,人类,就是那批拥有超能力的外星人。而AI可以通过标注数据,学习我们的思维模式,最终获得独属于人类的超能力——智能。
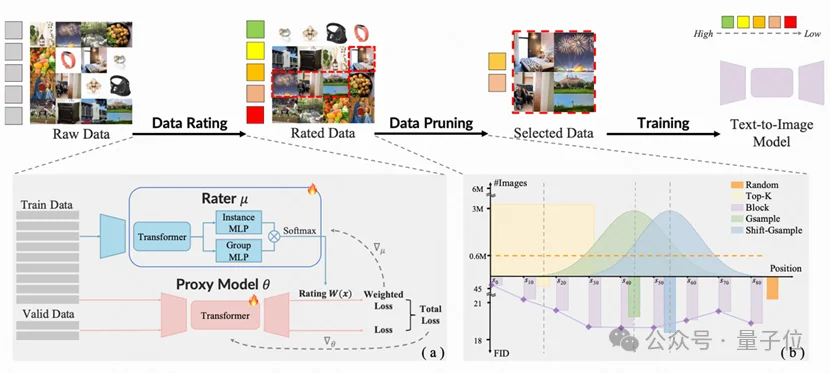
由香港大学丁凯欣领导,联合华南理工大学周洋以及快手科技Kling团队共同完成的这项研究,开发出了一个名为“炼金师”(Alchemist)的AI系统。它就像一位挑剔的大厨,能从海量图片数据中精准挑选出最有价值的一半。

英伟达在开源模型上玩的很激进: “最高效的开放模型家族”Nemotron 3,混合Mamba-Transformer MoE架构、NVFP4低精度训练全用上。而且开放得很彻底:

能自动查数据、写分析、画专业金融图表的AI金融分析师来了!最近,中国人民大学高瓴人工智能学院提出了一个面向真实金融投研场景的多模态研报生成系统——玉兰·融观(Yulan-FinSight)。

为了AI还真是,搞网络的钱不少花,大动作,大投入,数据中心内部网络,重做;数据中心外部网络,也重做;确切表达,不是完全推翻,但也是大变革。数据中心里的网络,谭老师我写了好几篇了,
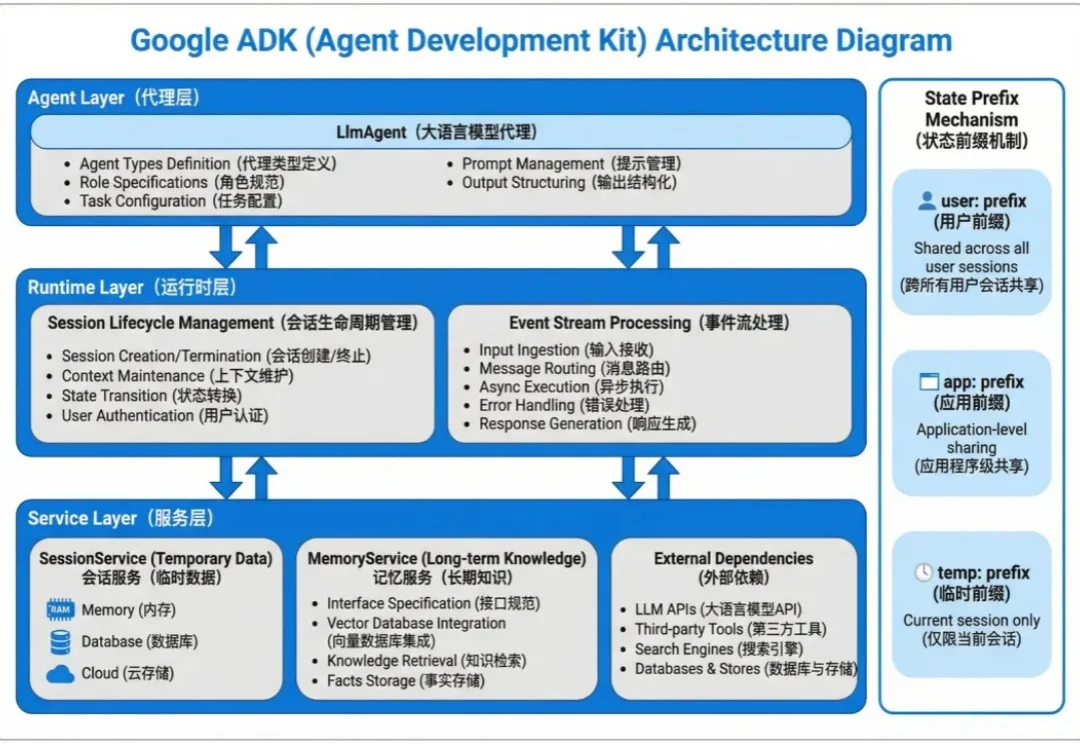
Agent 的状态数据分两种:会话内的临时上下文和跨会话的长期知识。

在生成式AI(GenAI)的推动下,2025年标志着行业从“震撼期”正式步入“深水区”。这并非资本的泡沫,而是计算范式从CPU向GPU的根本性迁移——数据中心正进化为实时生产智能的“AI工厂”。相比于模型参数的单纯竞赛,AI应用带来的“任务执行”能力与直观体验,让人切身感受到从“信息检索”向“智能生成”的范式跃迁。