
AI天气预报新布局
AI天气预报新布局我国自主研发的“风清”“风雷”“风顺”“风和”等气象大模型,不仅在实战中并跑国际同类系统,更让气象服务走向个性化、精准化与智能化。在“风和”大模型的对话框输入上述问题,AI立刻展现出它的“思考轨迹”:先定位时间与地点,调取该时段温度、风力、湿度等数据,继而生成贴心的穿搭提醒——“内薄外厚,方便调节室内外温差”“早晚温差大,建议携带外套”“室内暖气较足
来自主题: AI资讯
9628 点击 2026-01-03 14:04
 搜索
搜索
我国自主研发的“风清”“风雷”“风顺”“风和”等气象大模型,不仅在实战中并跑国际同类系统,更让气象服务走向个性化、精准化与智能化。在“风和”大模型的对话框输入上述问题,AI立刻展现出它的“思考轨迹”:先定位时间与地点,调取该时段温度、风力、湿度等数据,继而生成贴心的穿搭提醒——“内薄外厚,方便调节室内外温差”“早晚温差大,建议携带外套”“室内暖气较足

借势Agent浪潮,实时数据企业走上港股舞台。
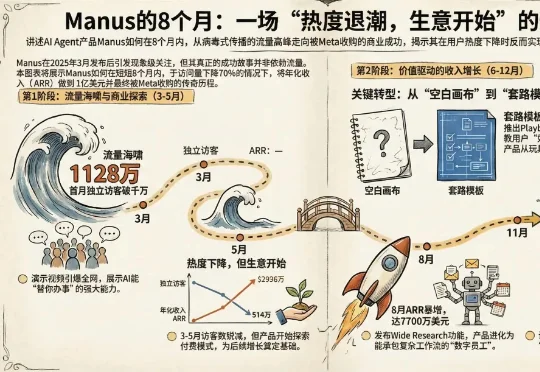
Manus被Meta收购的消息在AI圈刷屏了。 交易细节尚未完全公开,但Meta的态度很明确:它不仅要把Manus的能力整合进自家产品(包括Meta AI),还计划继续把Manus作为独立服务运营和销

在空间智能(Spatial Intelligence)飞速发展的今天,全景视角因其 360° 的环绕覆盖能力,成为了机器人导航、自动驾驶及虚拟现实的核心基石。然而,全景深度估计长期面临 “数据荒” 与 “模型泛化差” 的瓶颈。

惊到了!Claude Code之父 Boris Cherny 刚跟大神卡帕西友好互动了“9级大地震”的帖子,后脚就在X上放出自己过去一个月使用CC的真实生产数据:

如果一项任务主要涉及文本处理,并且你拥有完善的数据渠道,能够获取完成该任务所需的全部文本信息,那么人工智能完成这项任务的难度就会较低。

清华大学等多所高校联合发布SR-LLM,这是一种融合大语言模型与深度强化学习的符号回归框架。它通过检索增强和语义推理,从数据中生成简洁、可解释的数学模型,显著优于现有方法。在跟车行为建模等任务中,SR-LLM不仅复现经典模型,还发现更优新模型,为机器自主科学发现开辟新路径。

又一家核能初创公司获得了九位数的融资。
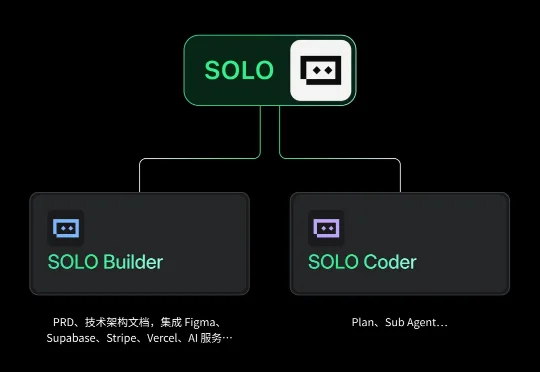
TRAE在一年里写了1000亿行代码!如果按照一个程序员每天写100行有效代码计算,这相当于300万个程序员不吃不喝、没日没夜干了一整年。而这也仅仅是《TRAE 2025年度产品报告》中的冰山一角,更多惊人的数据还包括:
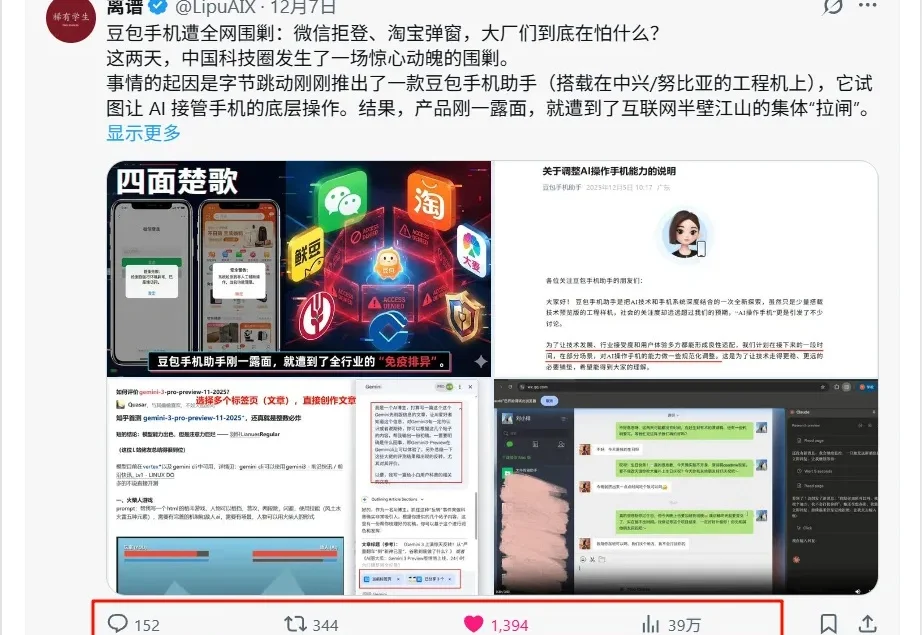
说实话,昨天的数据真的把我吓了一跳。