刚刚,ChatGPT 发布 AI 医疗功能!能读病历做诊断,支持苹果健康
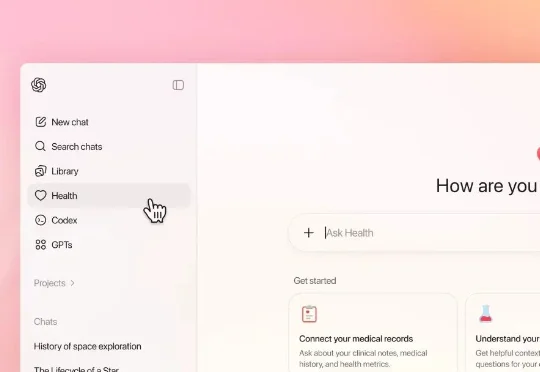
刚刚,ChatGPT 发布 AI 医疗功能!能读病历做诊断,支持苹果健康新的一年,OpenAI 决定认真入局 AI 医疗健康领域了。就在刚刚,OpenAI 重磅推出了 ChatGPT 健康(ChatGPT Health),能够把你的医疗记录、健康 App、甚至是 Apple 健康数据连接起来,然后用 AI 帮你看懂那些复杂到头大的体检报告、准备就医问题清单、甚至规划饮食运动。
来自主题: AI资讯
7630 点击 2026-01-08 09:48