阿里发布信息检索Agent,可自主上网查资料,GAIA基准超越GPT-4o | 模型&数据开源
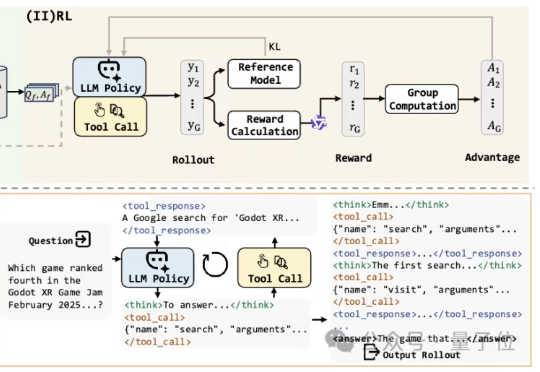
阿里发布信息检索Agent,可自主上网查资料,GAIA基准超越GPT-4o | 模型&数据开源Agent能“看懂网页”,像人类一样上网?阿里发布WebDancer,就像它的名字一样,为“网络舞台”而生。
来自主题: AI技术研报
8270 点击 2025-06-27 15:54
 搜索
搜索
Agent能“看懂网页”,像人类一样上网?阿里发布WebDancer,就像它的名字一样,为“网络舞台”而生。

中东国家凭借雄厚石油财富积极投入AI领域,建设全球级数据中心,利用低电价和丰富光伏资源解决能耗问题。通过免税、居留便利等政策吸引全球创业者和资本。其地缘优势成为中美技术博弈的缓冲带,美国解除芯片限制,争抢中东市场和投资。海湾国家正转型为新兴AI中心。

无需原作者同意,AI可以用已出版书籍作训练数据了。

大模型热潮席卷全球,越来越多企业拥抱AI变革。一个普遍却棘手的难题横亘在眼前:
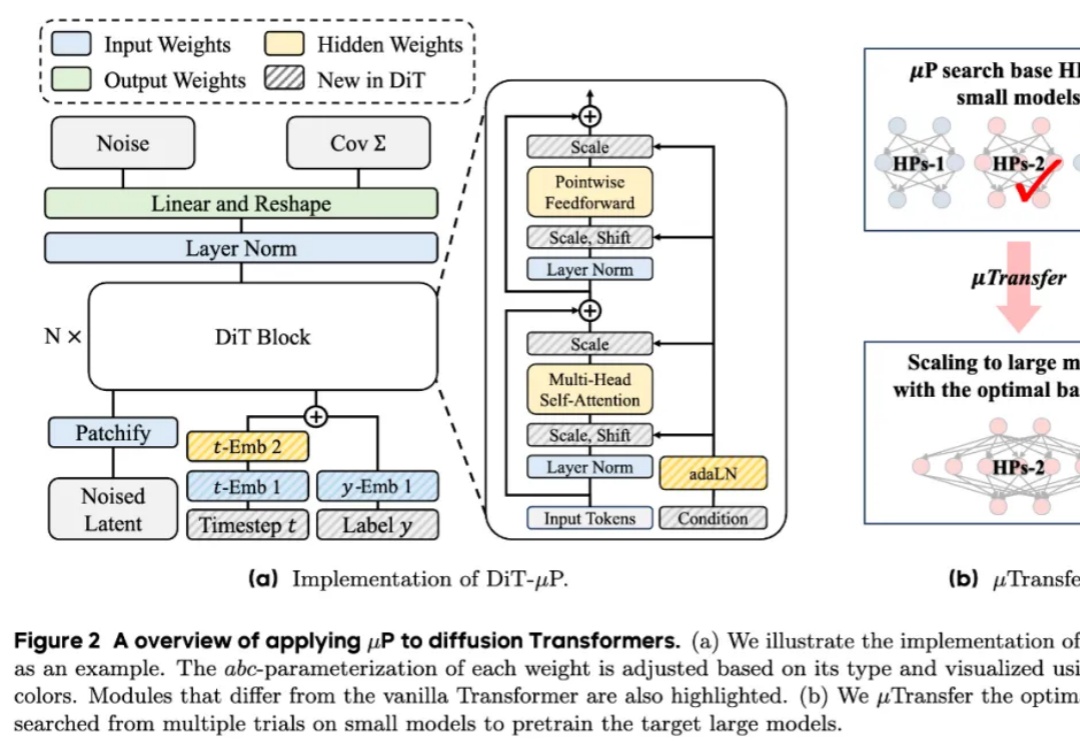
近年来,diffusion Transformers已经成为了现代视觉生成模型的主干网络。随着数据量和任务复杂度的进一步增加,diffusion Transformers的规模也在快速增长。然而在模型进一步扩大的过程中,如何调得较好的超参(如学习率)已经成为了一个巨大的问题,阻碍了大规模diffusion Transformers释放其全部的潜能。
第一作者孙秋实是香港大学计算与数据科学学院博士生,硕士毕业于新加坡国立大学数据科学系。

现在投资不止局限于做人形机器人本体的公司,还会押注模型、数据、硬件、场景等产业链上下游的企业;
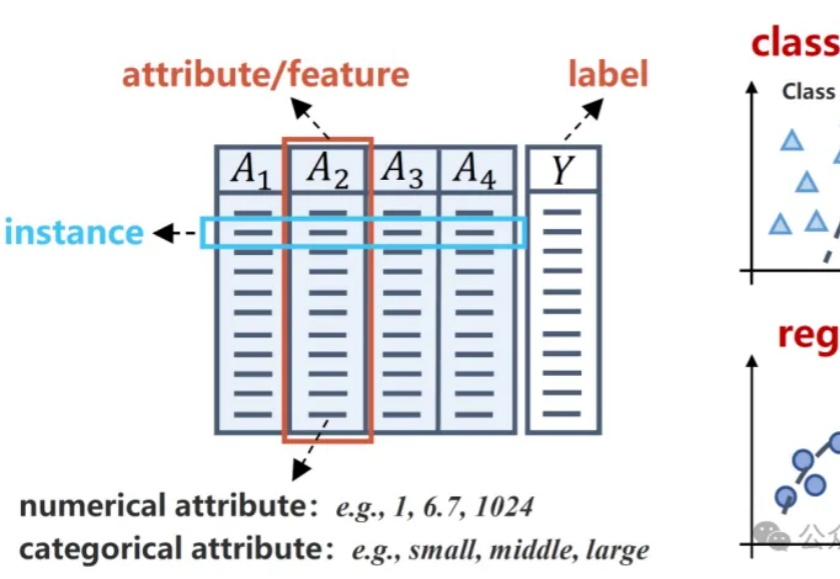
在AI应用中,表格数据的重要性愈发凸显,广泛应用于金融、医疗健康、教育、推荐系统及科学研究领域。
本文第一作者为韩沛煊,本科毕业于清华大学计算机系,现为伊利诺伊大学香槟分校(UIUC)计算与数据科学学院一年级博士生,接受 Jiaxuan You 教授指导。

基础模型严重依赖大规模、高质量人工标注数据来学习适应新任务、领域。为解决这一难题,来自北京大学、MIT等机构的研究者们提出了一种名为「合成数据强化学习」(Synthetic Data RL)的通用框架。该框架仅需用户提供一个简单的任务定义,即可全自动地生成高质量合成数据。