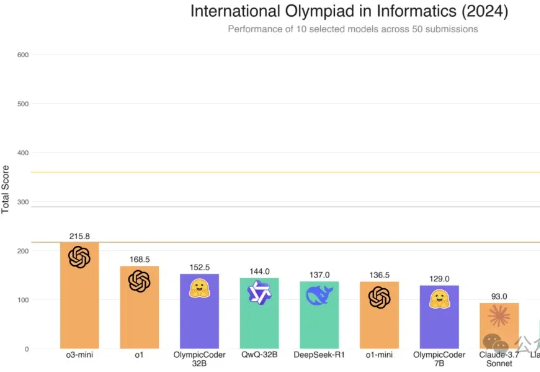
32B IOI奥赛击败DeepSeek-R1!Open R1开源复刻第三弹,下一步R1-Zero
32B IOI奥赛击败DeepSeek-R1!Open R1开源复刻第三弹,下一步R1-ZeroHugging Face的Open R1重磅升级,7B击败Claude 3.7 Sonnet等一众前沿模型。凭借CodeForces-CoTs数据集的10万高质量样本、IOI难题的严苛测试,以及模拟真实竞赛的提交策略优化,这款模型展现了惊艳的性能。
来自主题: AI资讯
10219 点击 2025-03-12 18:35