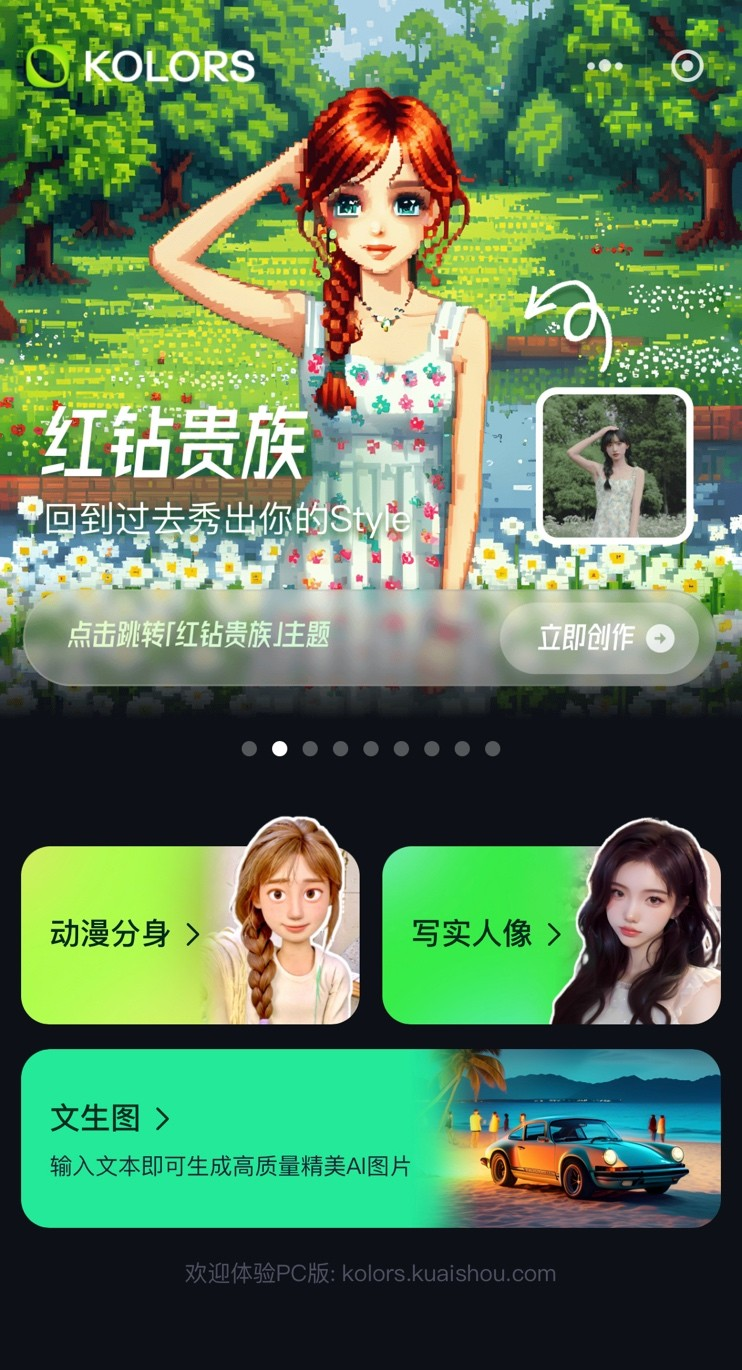
快手发布大模型产品“可图” 20多种创新AI图像玩法限免上线
快手发布大模型产品“可图” 20多种创新AI图像玩法限免上线随着大模型产品可图的正式发布,快手也将持续为用户带来更丰富有趣的AI互动新体验。
来自主题: AI资讯
11045 点击 2024-06-01 17:37
 搜索
搜索
随着大模型产品可图的正式发布,快手也将持续为用户带来更丰富有趣的AI互动新体验。

七年前,一张帅气军装照的H5活动,成为现象级刷屏朋友圈的“始祖”。

文生图模型成熟之后,有多少人苦练Midjourney咒语,还是调不出可用的图像?

又一家大模型开源了,这次是腾讯。

北京时间 5 月 15 日凌晨,在 OpenAI 春季发布会的第二天,2024 年谷歌 I/O 召开,这是一场充满了 AI 的发布会,谷歌对其旗下的多款 AI 产品发布了大更新,从基座模型 Gemini 到新的 AI 助手 Astra、新的文生视频模型 Veo,以及更强大的文生图模型 Imagen 3。
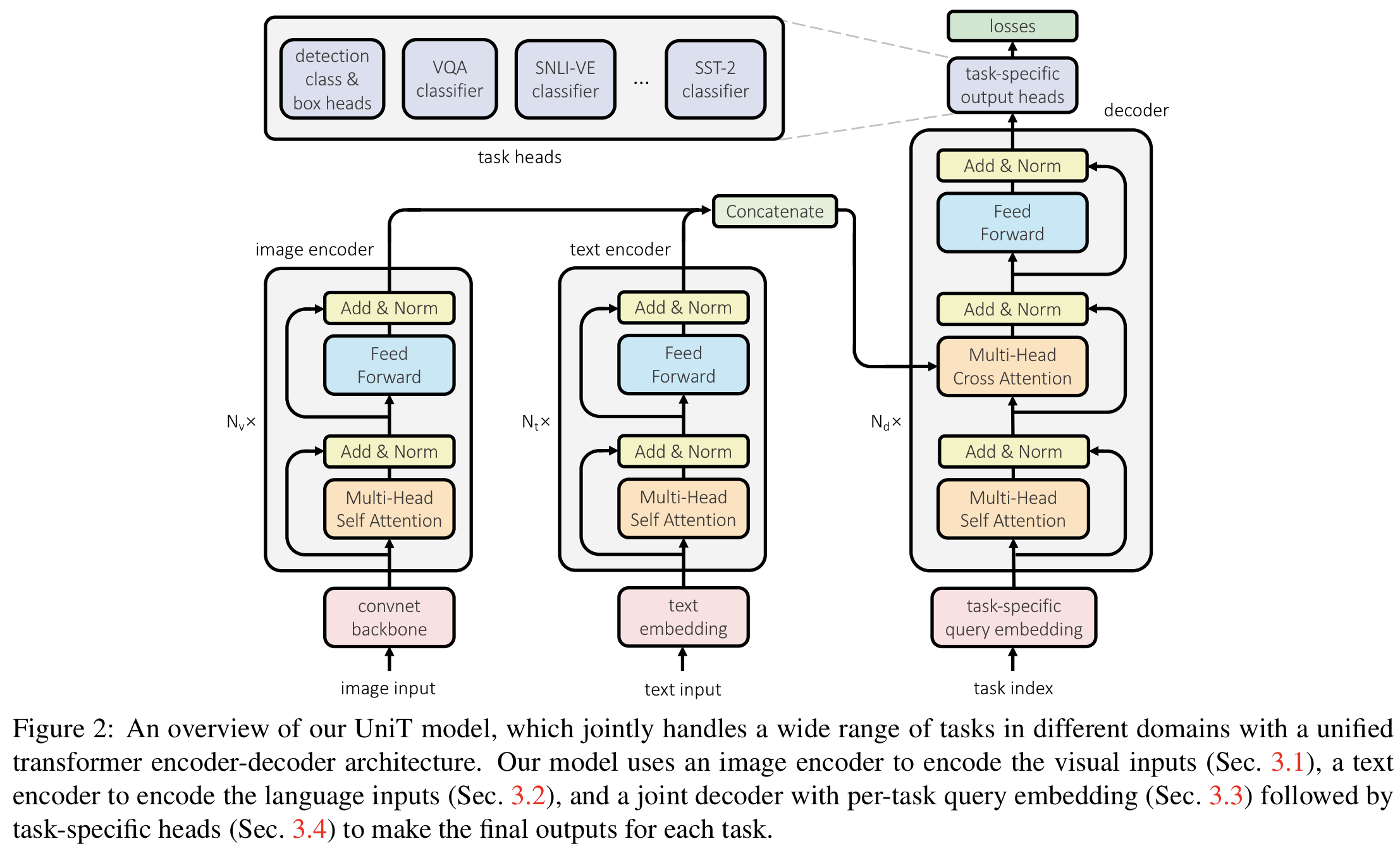
多模态 AI 无疑是今年大模型的发展重点之一,Sora、Midjourney、Suno 等文生视频、文生图、文生音乐赛道的代表产品也是用户的关注热点。
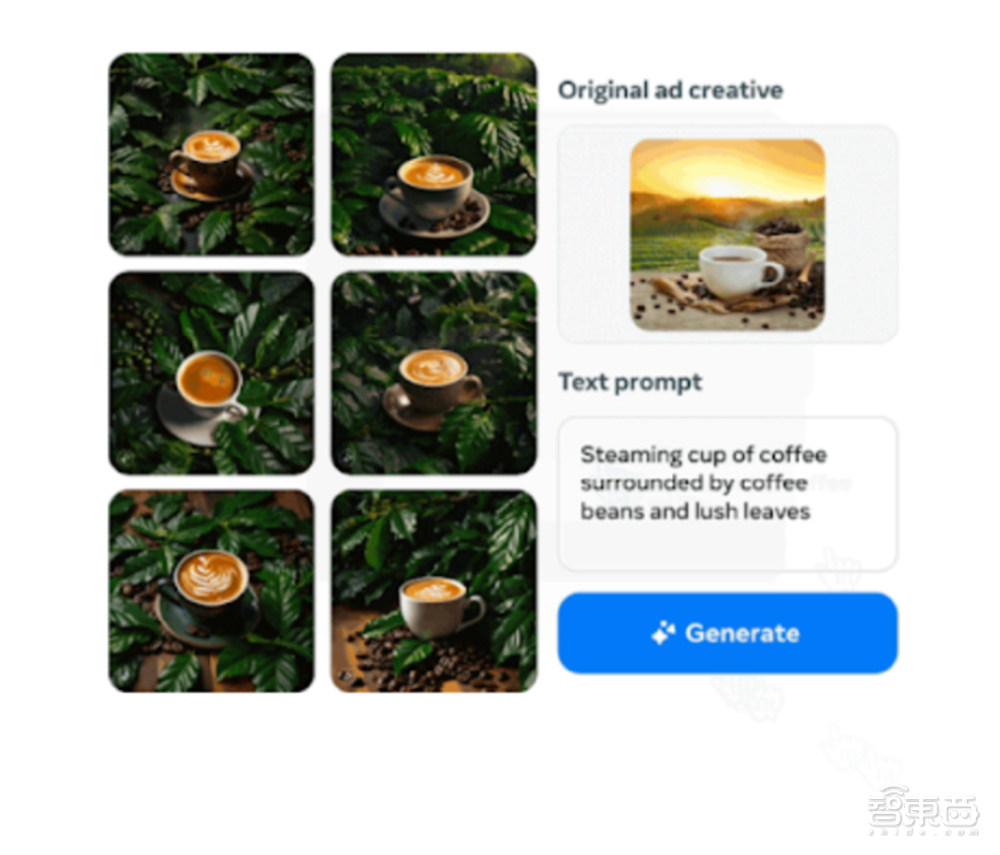
智东西5月9日报道,近日,Meta宣布推出一系列增强的生成式AI技术,扩展其生成式AI广告产品。其中,新增工具能自动生成多样化图像并在其上叠加文字,提升广告商的创意水平和广告效果。
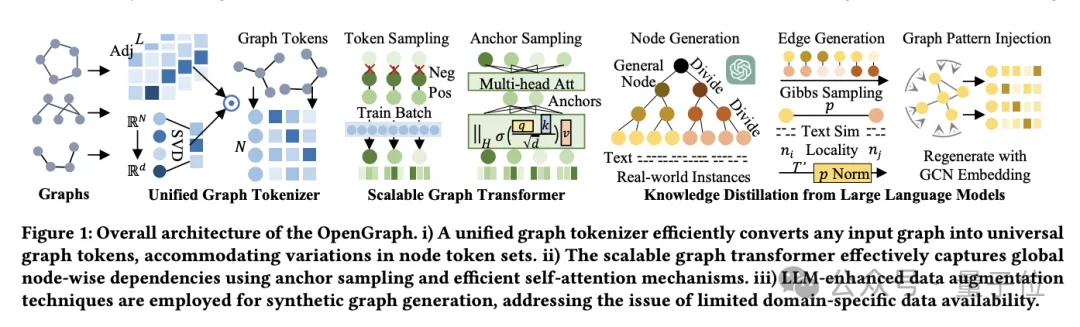
图学习领域的数据饥荒问题,又有能缓解的新花活了!

首届ICLR时间检验奖,颁向变分自编码器VAE

文生图、文生音频、文生视频、AI搜索引擎……大模型在多模态的进程可谓是愈演愈烈。