# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

近日,北大、斯坦福、以及爆火的Pika Labs联合发表了一项研究,将大模型文生图的能力提升到了新的高度。

论文地址:https://arxiv.org/pdf/2401.11708.pdf
代码地址:https://github.com/YangLing0818/RPG-DiffusionMaster
论文作者提出了一个全新的免训练文本到图像生成/编辑框架,利用多模态大语言模型(MLLM)强大的思维链推理能力,来增强文本到图像扩散模型的组合性。
简单来说,就是能让文生图模型在面对「多个属性和关系的多个对象的复杂文本提示」时表现更出色。
话不多说,直接上图:

A green twintail girl in orange dress is sitting on the sofa while a messy desk under a big window on the left, a lively aquarium is on the top right of the sofa, realistic style.
一个穿着橙子连衣裙的绿色双马尾女孩坐在沙发上,左边的大窗户下是一张凌乱的办公桌,沙发右上方是一个活泼的水族馆,现实主义风格。
面对关系复杂的多个对象,模型给出的整个画面的结构、人与物品的关系都非常合理,使观者眼前一亮。
而对于同样的提示,我们来看一下当前最先进的SDXL和DALL·E 3的表现:

再看一下新框架面对多个对象绑定多个属性时的表现:

From left to right, a blonde ponytail Europe girl in white shirt, a brown curly hair African girl in blue shirt printed with a bird, an Asian young man with black short hair in suit are walking in the campus happily.
从左到右,一个穿着白色衬衫、扎着金发马尾辫的欧洲女孩,一个穿着印着小鸟的蓝色衬衫、棕色卷发的非洲女孩,一个穿着西装、黑色短发的亚洲年轻人正开心地在校园里散步。
研究人员将这个框架命名为RPG(Recaption,Plan and Generate),采用MLLM作为全局规划器,将复杂图像的生成过程分解为子区域内多个更简单的生成任务。
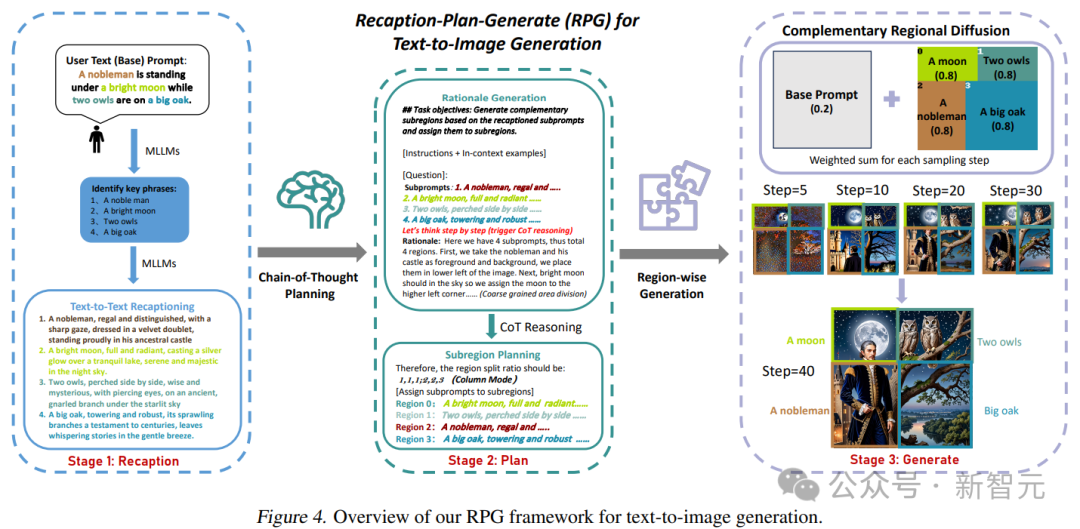
文中提出了互补的区域扩散,实现区域组合生成,还将文本引导的图像生成和编辑以闭环方式集成到了RPG框架中,从而增强了泛化能力。
实验表明,本文提出的RPG框架优于目前最先进的文本图像扩散模型,包括DALL·E 3和SDXL,尤其是在多类别对象合成以及文本图像语义对齐方面。
值得注意的是,RPG框架可以广泛兼容各种MLLM架构(如MiniGPT-4)和扩散骨干网络(如ControlNet)。
当前的文生图模型主要存在两个问题:1. 基于布局或基于注意力的方法只能提供粗略的空间引导,并且难以处理重叠的对象;2. 基于反馈的方法需要收集高质量的反馈数据,并产生额外的训练成本。
为了解决这些问题,研究人员提出了RPG的三个核心策略,如下图所示:
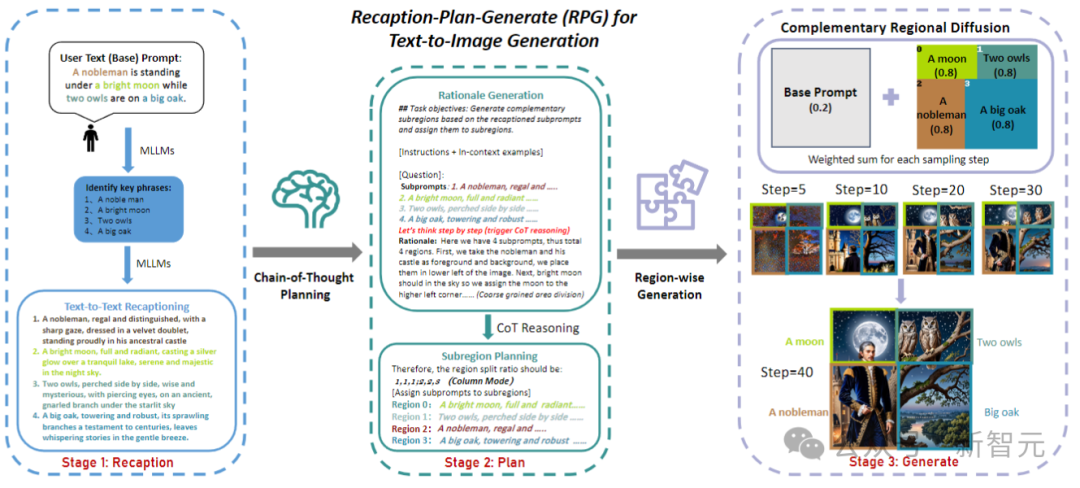
给定一个包含多个实体和关系的复杂文本提示,首先利用MLLM将其分解为基本提示和高度描述性的子提示;随后,利用多模态模型的CoT规划将图像空间划分为互补的子区域;最后,引入互补区域扩散来独立生成每个子区域的图像,并在每个采样步骤中进行聚合。
将文本提示转换为高度描述性的提示,提供信息增强的提示理解和扩散模型中的语义对齐。
使用MLLM来识别用户提示y中的关键短语,获得其中的子项:
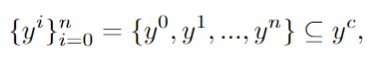
使用LLM将文本提示符分解为不同的子提示符,并进行更详细的重新描述:
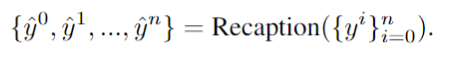
通过这种方式,可以为每个子提示生成更密集的细粒度细节,以有效地提高生成图像的保真度,并减少提示和图像之间的语义差异。
将图像空间划分为互补的子区域,并为每个子区域分配不同的子提示,同时将生成任务分解为多个更简单的子任务。
具体来说,将图像空间H×W划分为若干互补区域,并将每个增强子提示符分配给特定区域R:
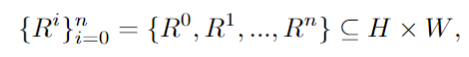
利用MLLM强大的思维链推理能力,进行有效的区域划分。通过分析重新获得的中间结果,就能为后续的图像合成生成详细的原理和精确的说明。
在每个矩形子区域内,独立生成由子提示引导的内容,随后调整大小和连接的方式,在空间上合并这些子区域。
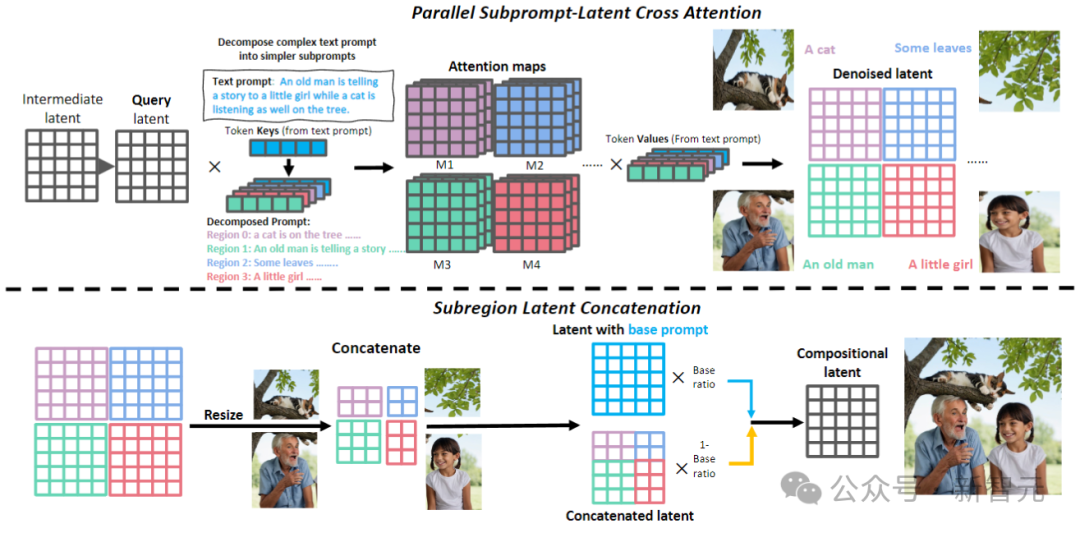
这种方法有效地解决了大模型难以处理重叠对象的问题。此外,论文扩展了这个框架,以适应编辑任务,采用基于轮廓的区域扩散,从而对需要修改的不一致区域精确操作。
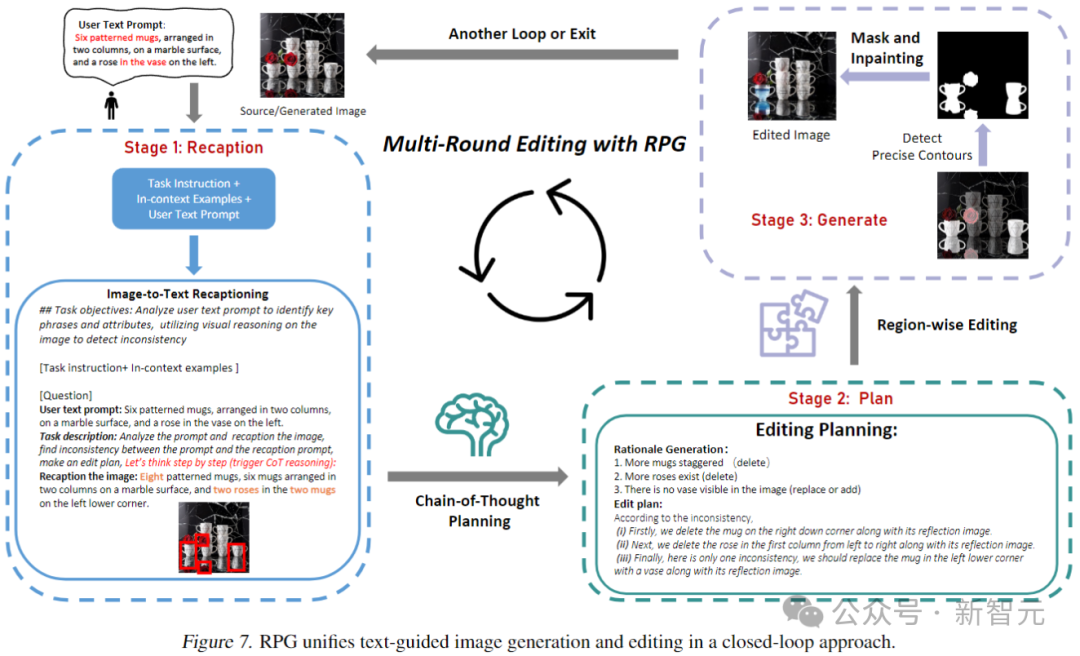
如上图所示。在复述阶段,RPG采用MLLM作为字幕来复述源图像,并利用其强大的推理能力来识别图像和目标提示之间的细粒度语义差异,直接分析输入图像如何与目标提示对齐。
使用MLLM(GPT-4、Gemini Pro等)来检查输入与目标之间关于数值准确性、属性绑定和对象关系的差异。由此产生的多模态理解反馈将被交付给MLLM,用于推理编辑计划。
我们来看一下生成效果在以上三个方面的表现,首先是属性绑定,对比SDXL、DALL·E 3和LMD+:

我们可以看到在全部三项测试中,只有RPG最准确地反映了提示所描述的内容。
然后是数值准确性,展示顺序同上(SDXL、DALL·E 3、LMD+、RPG):

——没想到数数这件事情对于文生图大模型还挺难的,RPG轻松战胜对手。
最后一项是还原提示中的复杂关系:

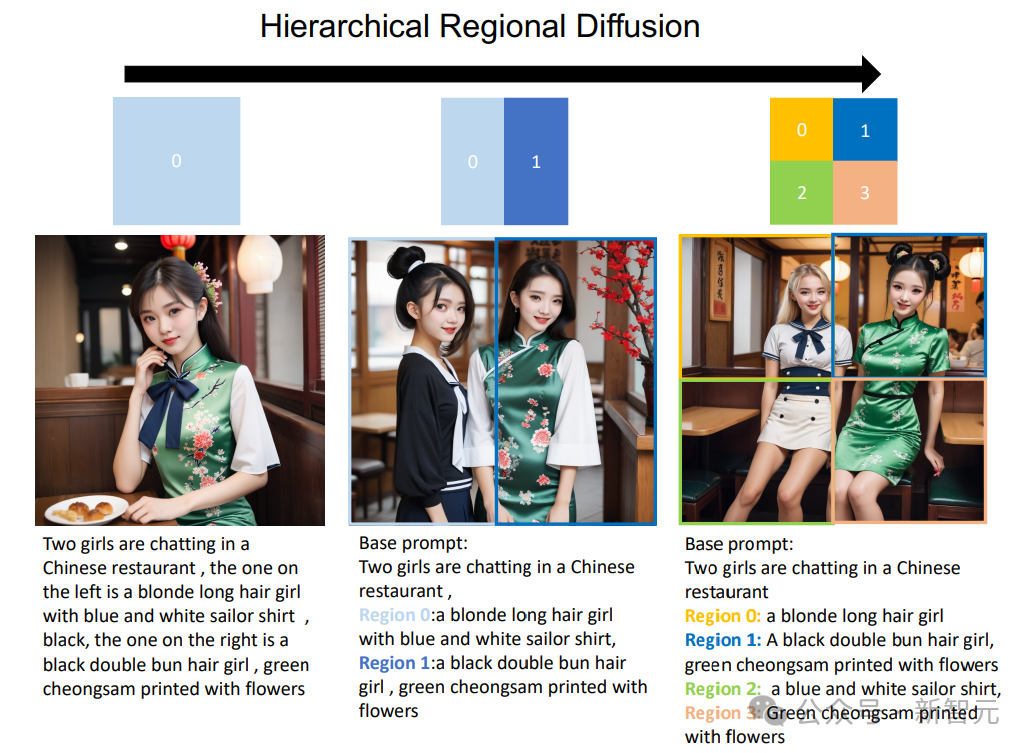
此外,还可以将区域扩散扩展为分层格式,将特定子区域划分为更小的子区域。
如下图所示,当增加区域分割的层次结构时,RPG可以在文本到图像的生成方面实现显著的改进。这为处理复杂的生成任务提供了一个新的视角,使我们有可能生成任意组成的图像。
参考资料:
https://arxiv.org/pdf/2401.11708.pdf
文章来自于微信公众号 “新智元”




