
从图像到视频的任意分割:X2SAM让MLLM 真正看懂像素级时空世界
从图像到视频的任意分割:X2SAM让MLLM 真正看懂像素级时空世界为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。
来自主题: AI技术研报
7751 点击 2026-05-16 10:50
 搜索
搜索
为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。

在多模态大模型(MLLM)快速发展的浪潮中,融合多模型 “集体智慧” 已成为提升模型性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,不同来源的教师模型在架构与优化上的差异,其在相似推理过程中呈现出不稳定甚至偏移的认知轨迹,即 “概念漂移”(Concept Drift)。
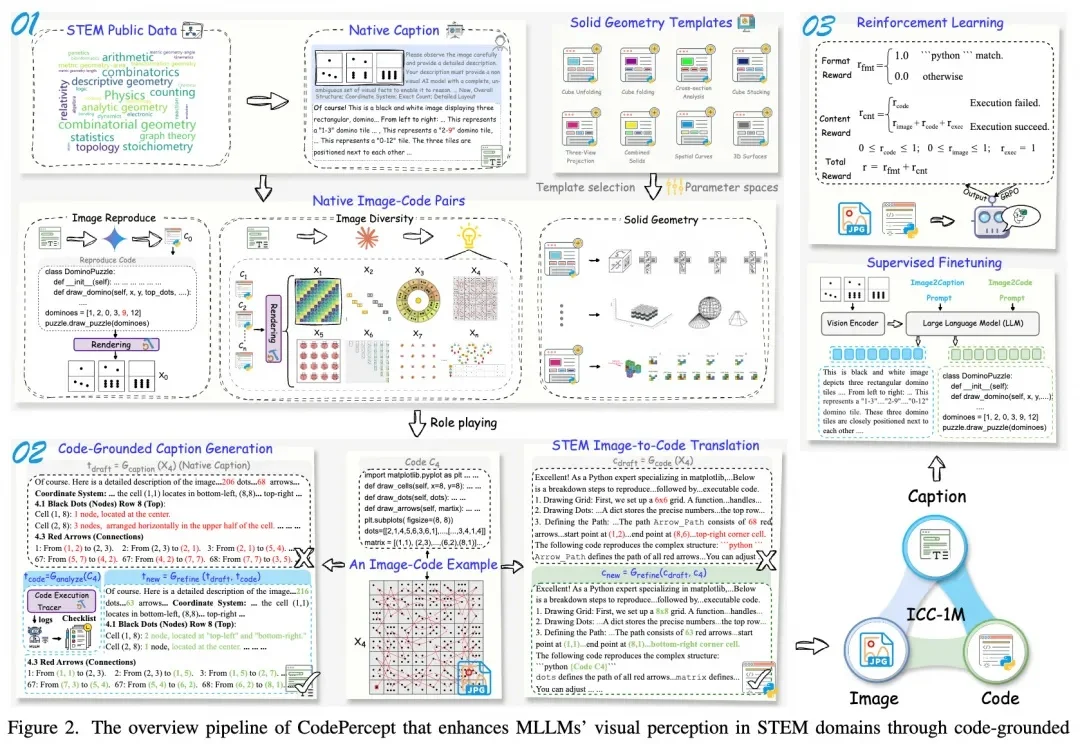
当多模态大语言模型(MLLMs)在面对科学、技术、工程和数学(STEM)领域的视觉推理题时频频「翻车」,一个根本性的问题摆在了所有研究者面前:大模型做不出理科题,究竟是因为「脑子笨」(推理能力受限),还是因为「眼神差」(视觉感知缺陷)?
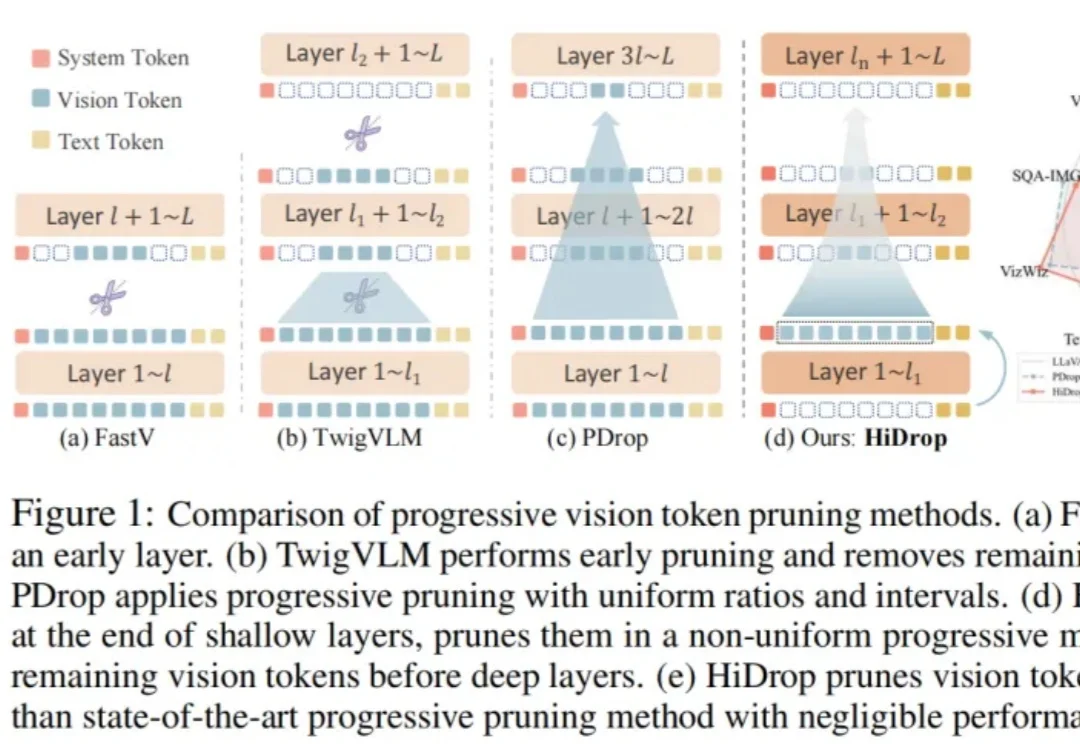
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。
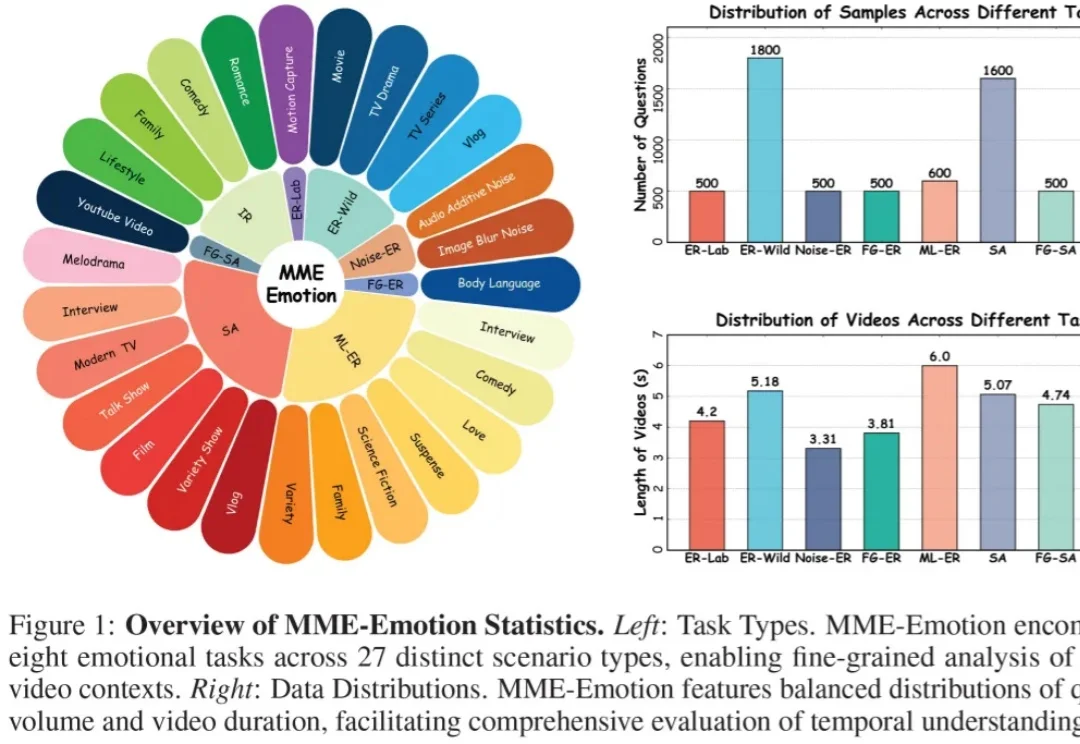
近年来,多模态大模型(Multimodal Large Language Models, MLLMs)正在迅速改变人工智能的能力边界。从图像理解到视频分析,从语音对话到复杂推理,大模型正在逐步具备类似人类的综合感知能力。但一个关键问题仍然没有得到充分回答:这些模型真的能够理解人类情绪吗?

没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。
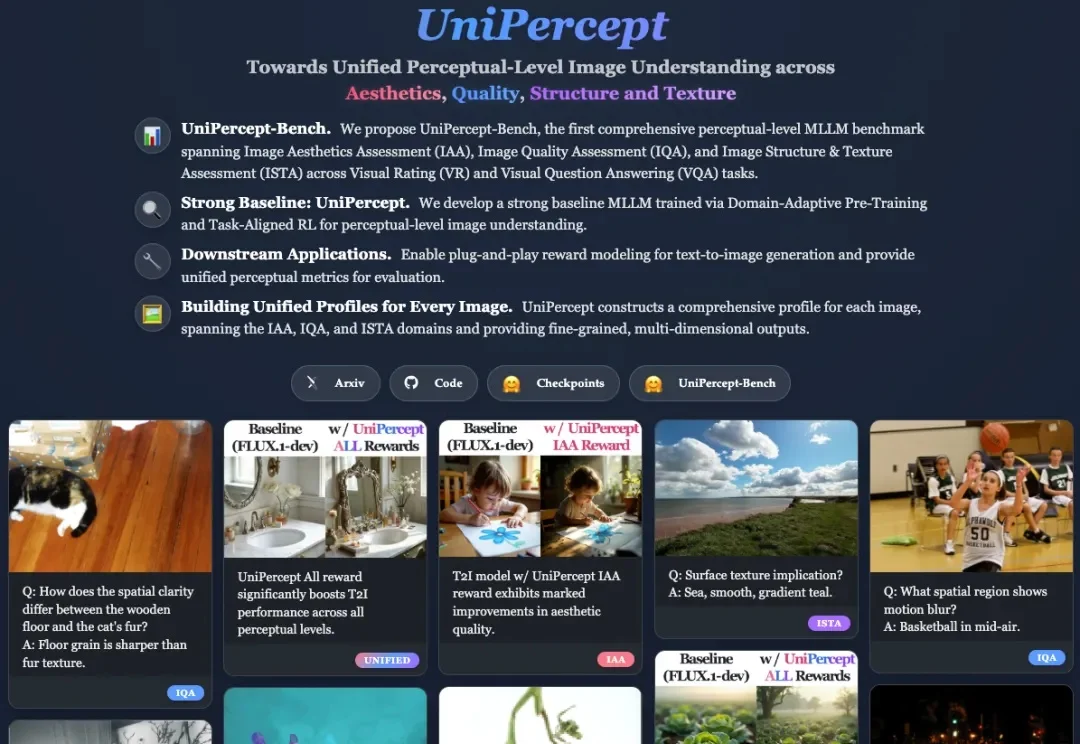
尽管多模态大语言模型(MLLMs)在识别「图中有什么」这一语义层面上取得了巨大进步,但在理解「图像看起来怎么样」这一感知层面上仍显乏力。
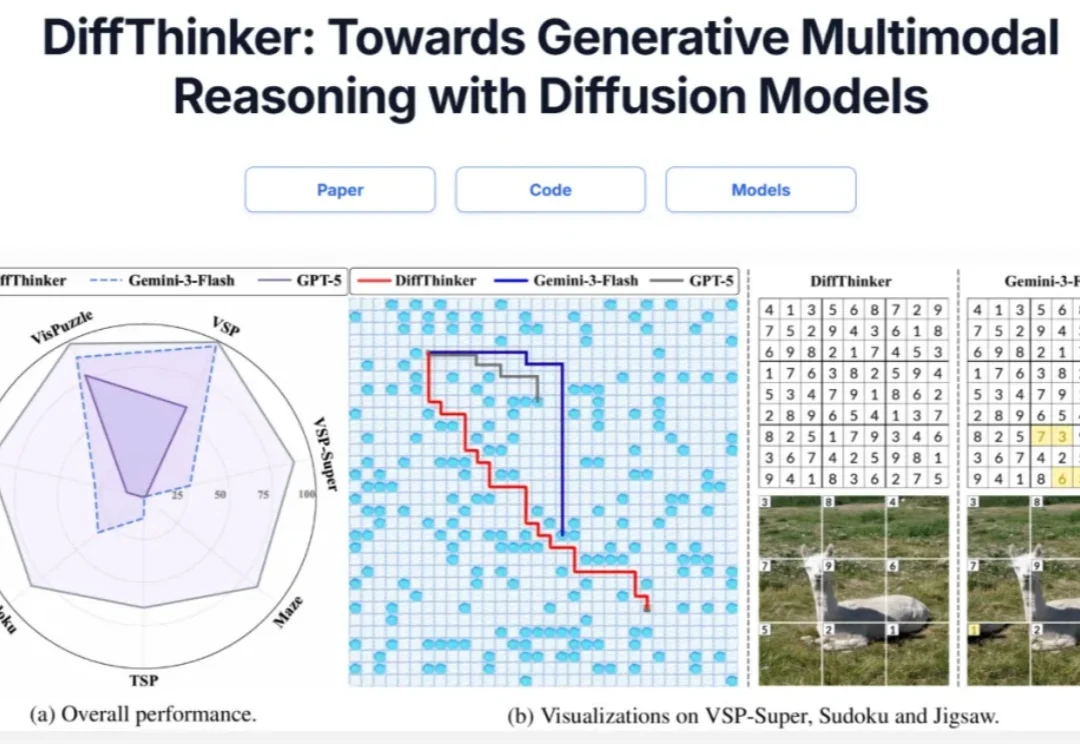
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。

空间理解能力是多模态大语言模型(MLLMs)走向真实物理世界,成为 “通用型智能助手” 的关键基础。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。

多模态大语言模型(MLLMs)已成为AI视觉理解的核心引擎,但其在真实世界视觉退化(模糊、噪声、遮挡等)下的性能崩溃,始终是制约产业落地的致命瓶颈。