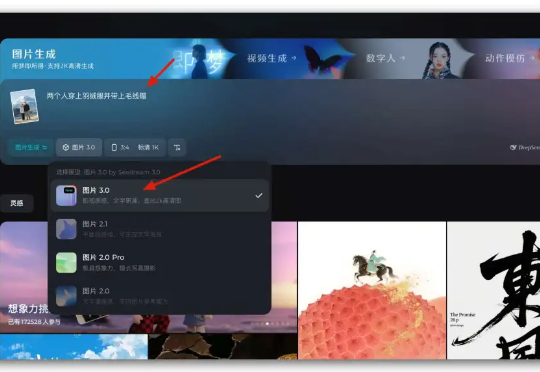
100镜实测即梦3.0新功能“看图改图”,一致性精细到头发丝级了
100镜实测即梦3.0新功能“看图改图”,一致性精细到头发丝级了前段时间,我们横向对比了即梦3.0、2.1、GPT4o的海报生成能力, 当时即梦3.0的文生图中文能力就已经超过了 GPT4o,我们通过提示语就可以控制字体的样式、位置、大小、排版等等。
来自主题: AI产品测评
12996 点击 2025-06-07 10:50
 搜索
搜索
前段时间,我们横向对比了即梦3.0、2.1、GPT4o的海报生成能力, 当时即梦3.0的文生图中文能力就已经超过了 GPT4o,我们通过提示语就可以控制字体的样式、位置、大小、排版等等。

3月时候GPT迎来了一波更新,在文生图、图生图领域带来了巨大更新,而紧接而至的却是一些创业公司的哀嚎:

刚刚,鹅厂把文生图卷出了新高度——发布混元图像2.0模型(Hunyuan Image 2.0),首次实现毫秒级响应,边说边画,实时生成!用户一边描述,它紧跟着绘制,整个过程那叫一个丝滑。不用等待,专治各种没有耐心。
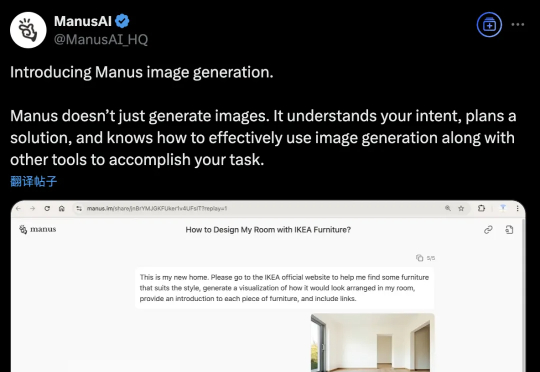
Manus深夜官宣,现在支持生成图像了!和一般AI绘图工具的“抽卡”模式不同,Manus能够理解你画图的目的,规划出生成方案后再“动手”。
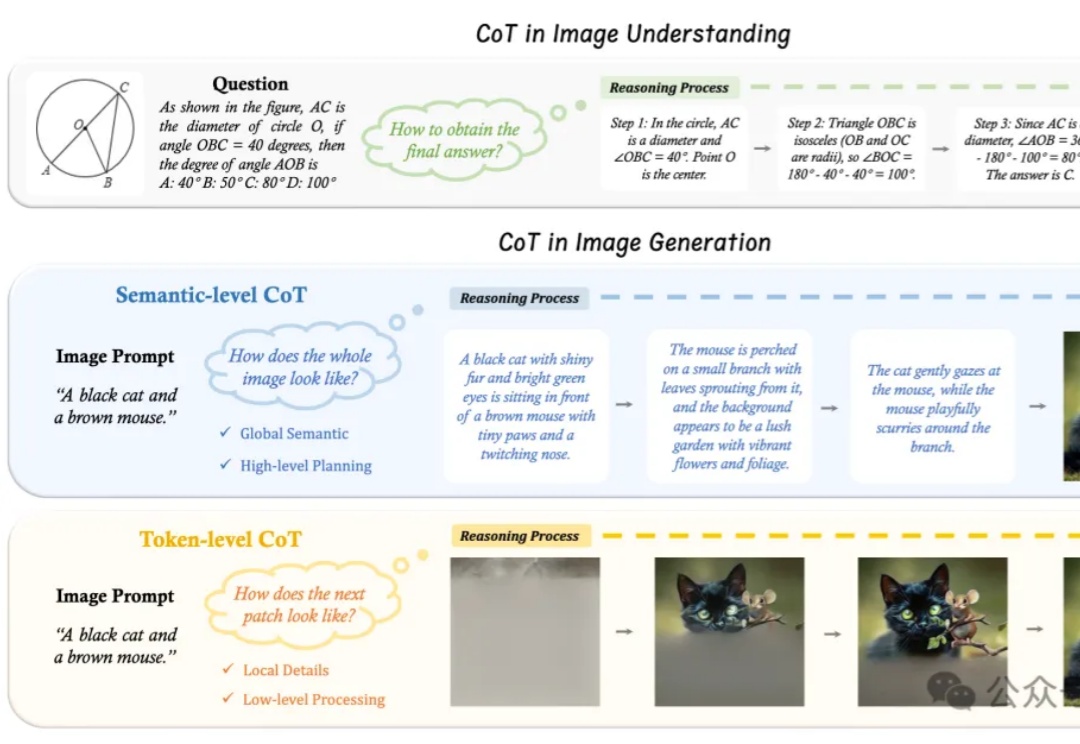
“先推理、再作答”,语言大模型的Thinking模式,现在已经被拓展到了图片领域。

最近我们AI爱好者的群里玩的全都是豆包和即梦生成的海报图片,大家评价做图片和海报效果真的很不错,豆包进步了,即梦也进步了。真的进步太大了!下面是我的朋友们尝试过的一些趣味玩法:
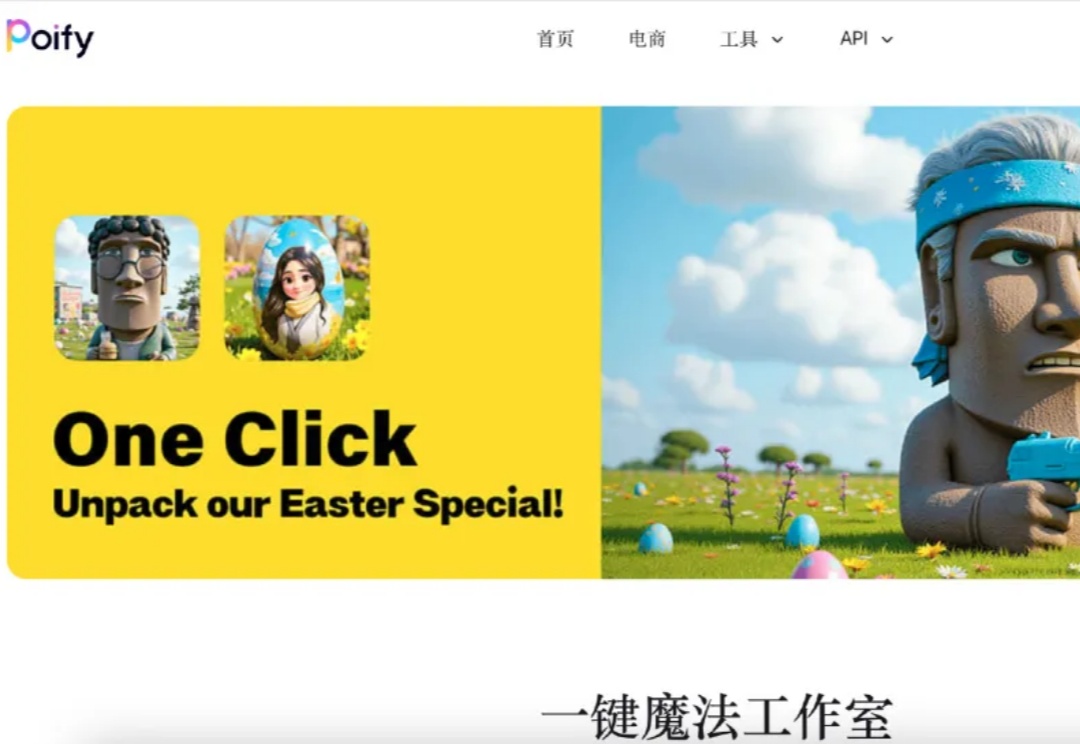
《读佳》获悉,快手已上线名为Poify的AI业务,不同于可灵AI,据悉,Poify更加专注于AI作图领域,除了支持常规的文生图和图生图的功能外,最重要的是涉足电商方面的AI作图。

5月9日,京西智谷潭柘智空基座大模型体系及应用平台建设项目开标,北京智谱清言科技有限公司中标,金额6400万元。根据此前公开的采购公告,本项目招标范围是:文生图片平台、图生视频与视频生视频平台、汉藏平台、多语种平台、AI数字人与垂类大模型对接平台、集成总平台等。

今天,字节发布了一整套 AI 全家桶,深度思考模型、视觉推理、文生图、AI Agent……几乎涵盖了最近 AI 圈关注度最高的产品。字节发布的产品和亮点有哪些:1. 豆包 1.5 · 深度思考模型,2. 文生图 3.0
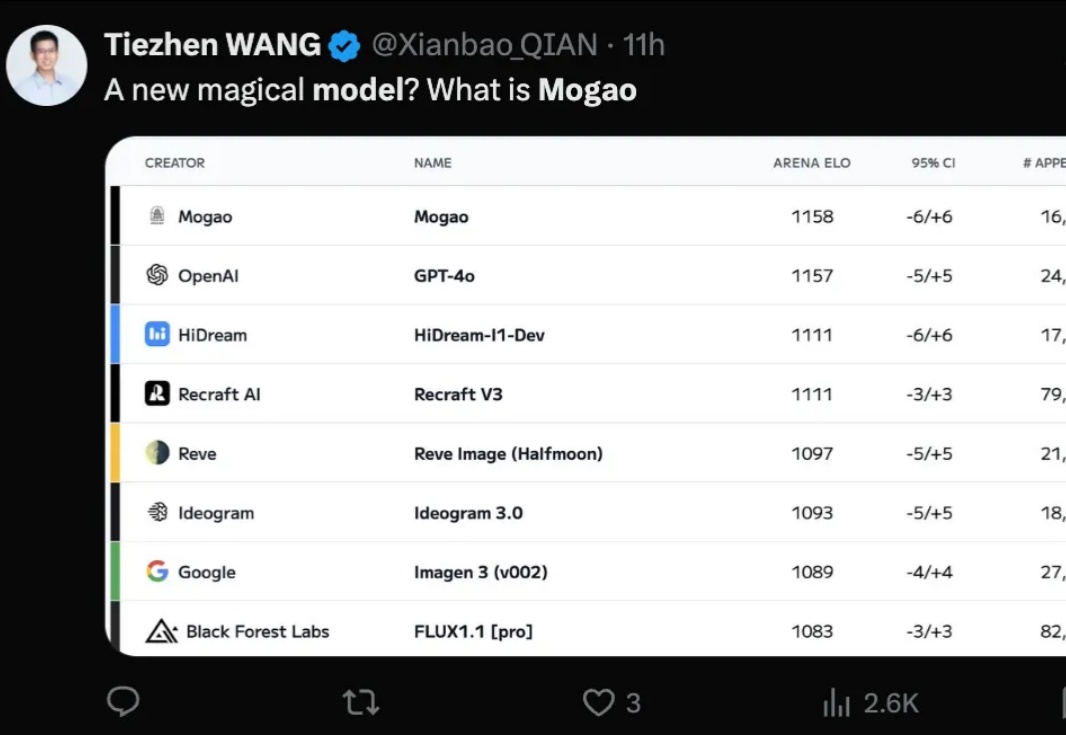
霸榜数天的神秘文生图模型 Mogao,什么来头?