
告别卡脖子,华为黑科技破局!昇腾推理加速1.6倍打破LLM降智魔咒
告别卡脖子,华为黑科技破局!昇腾推理加速1.6倍打破LLM降智魔咒LLM发展到今天,下一步该往哪个方向探索?
来自主题: AI资讯
9808 点击 2025-05-28 15:32
LLM发展到今天,下一步该往哪个方向探索?
大模型巨无霸体量,让端侧部署望而却步?华为联手中科大提出CBQ新方案,仅用0.1%的训练数据实现7倍压缩率,保留99%精度。

在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。

刚刚,昇腾两大技术创新,突破速度瓶颈重塑AI推理。FusionSpec创新的框架设计配合昇腾强大的计算能力,将投机推理框架耗时降至毫秒级,打破延迟魔咒。OptiQuant支持灵活量化,让推理性价比更高。

部署超大规模MoE这件事,国产芯片的推理性能,已经再创新高了—— 不仅是“英伟达含量为0”这么简单,更是性能全面超越英伟达Hopper架构!

现在,跑准万亿参数的大模型,可以彻底跟英伟达Say Goodbye了。
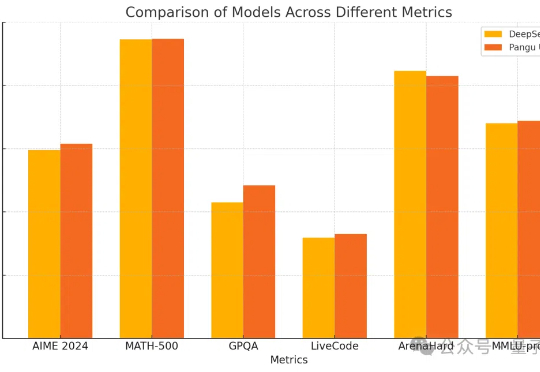
密集模型的推理能力也能和DeepSeek-R1掰手腕了?

终于,华为盘古大模型系列上新了,而且是昇腾原生的通用千亿级语言大模型。我们知道,如今各大科技公司纷纷发布百亿、千亿级模型。但这些大部分模型训练主要依赖英伟达的 GPU。
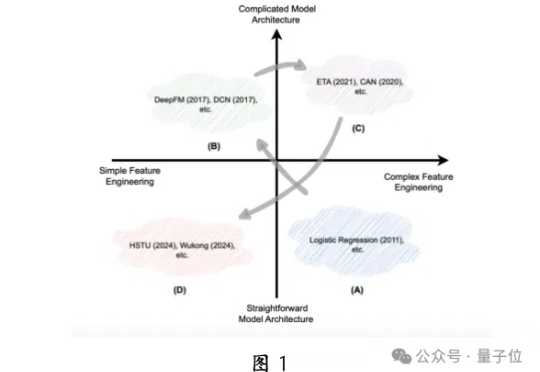
推荐大模型也可生成式,并且首次在国产昇腾NPU上成功部署!

国产GPU适配DeepSeek,商用前景广阔。